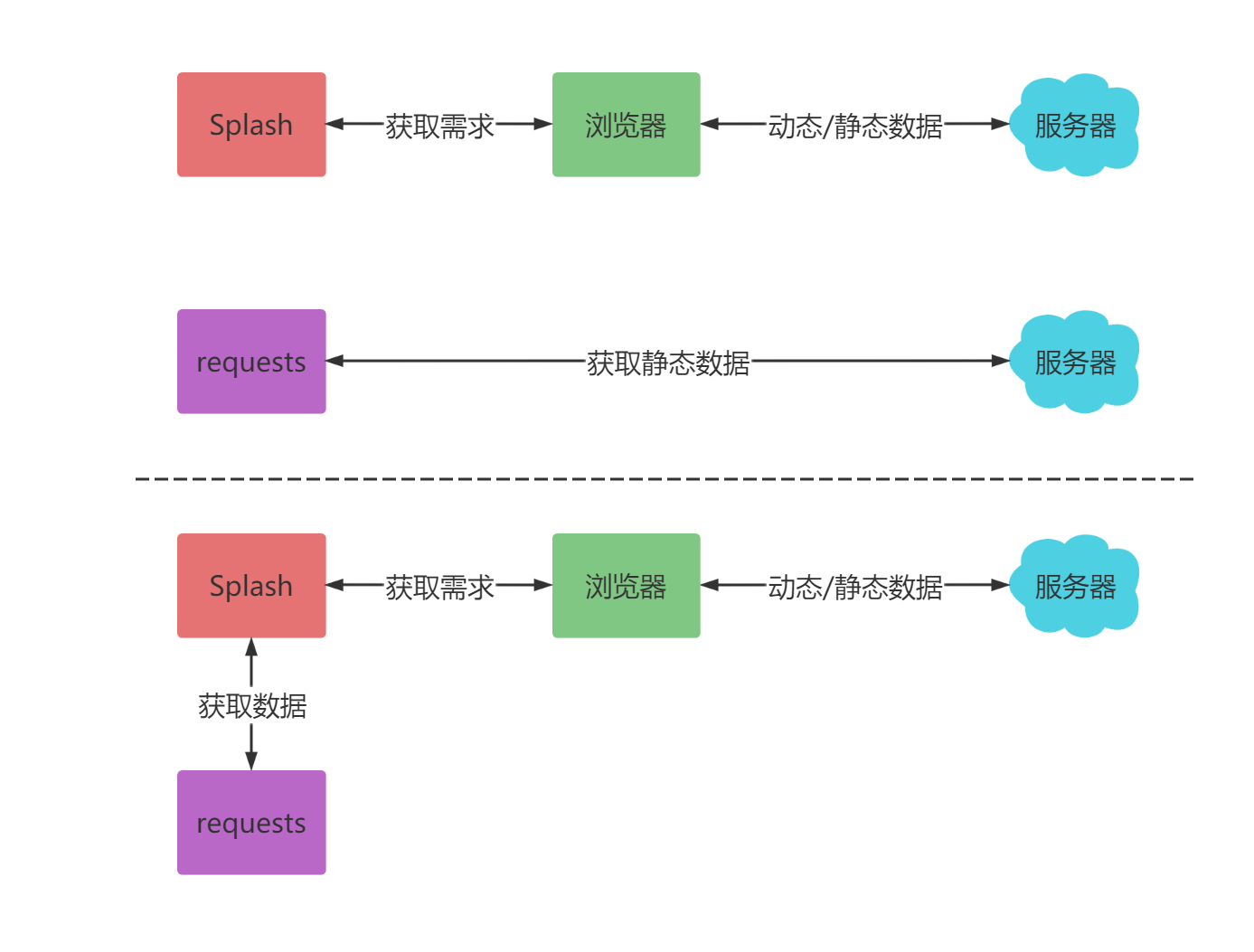
Splash与requests结合
Splash与requests结合

render.html
此接口用于获取JavaScript渲染的页面的HTML代码,接口地址就是Splash的运行地址加此接口名称,例如http://localhost:8050/render.html
import requests
def func1():
'''
render.html 返回一个html结果
'''
url = 'https://www.xxxxx.com/'
headers = {'User-Agent': UserAgent().random}
base_url =f'http://localhost:8050/render.html?url={url}&wait=1'
resp = requests.get(base_url,headers=headers)
with open('temp.html','wb') as f:
f.write(resp.content)render.png
此接口可以获取网页截图
import requests
def func2():
'''
render.png 返回一个截图
'''
url = 'https://www.xxxxx.com/'
headers = {'User-Agent': UserAgent().random}
base_url =f'http://localhost:8050/render.png?url={url}&wait=1'
resp = requests.get(base_url,headers=headers)
with open('temp.png','wb') as f:
f.write(resp.content)execute
最为强大的接口。前面说了很多Splash Lua脚本的操作,用此接口便可实现与Lua脚本的对接
import requests
from urllib.parse import quote
def func3():
'''
execute 执行lua脚本,返回相应的结果
'''
url = 'https://www.xxxxxx.com/'
lua = f'''
function main(splash,args)
splash:go("{url}")
splash:wait(1)
return splash:html()
end
'''
base_url = f'http://localhost:8050/execute?lua_source={quote(lua)}'
resp = requests.get(base_url)
with open('temp.html','wb') as f:
f.write(resp.content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号