
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Gitee文件夹链接
实验
爬取中国气象网:
天气网代码
image.py
复制import scrapy
from weather.items import WeatherItem
class ImageSpider(scrapy.Spider):
name = "image"
allowed_domains = ["www.weather.com.cn"]
start_urls = ["http://www.weather.com.cn/"]
def parse(self, response):
img_list = response.xpath('//img/@src').extract()
for img in img_list:
imgs = WeatherItem(img=img)
yield imgs
这里可以知道很多网站的图片都在xpath('//img/@src')下面,但是也有例外
pipelines.py
复制class jsonPipeline:
# 以下模式不推荐 因为每传递一个对象 那么就打卡一次文件 对文件的操作过于频繁
#
# item就是yield后面的book对象
def process_item(self, item, spider):
# (1)write方法必须是字符串,不能是对象
# (2)w模式 会每一个对象都打开一次文件 覆盖之前的内容
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
print(item.get('img'))
return item
def close_spider(self, spider):
self.fp.close()
class WeatherPipeline:
def open_spider(self, spider):
self.folder_path = 'C:\Programming\python\pythonProject\大数据采集\大数据采集实践\实践3\weather\image\\' # 设置保存图片的文件夹路径
def process_item(self, item, spider):
image_url = item['img'] # 假设图片地址存储在 item 的 'image_url' 字段中
# 使用 urllib 下载图片
file_name = image_url.split('/')[-1] # 图片文件名
file_path = self.folder_path + file_name # 图片保存的完整路径
urllib.request.urlretrieve(image_url, file_path)
return item
def close_spider(self, spider):
pass
采用多管道运行,下载图片速度更快
结果如下:
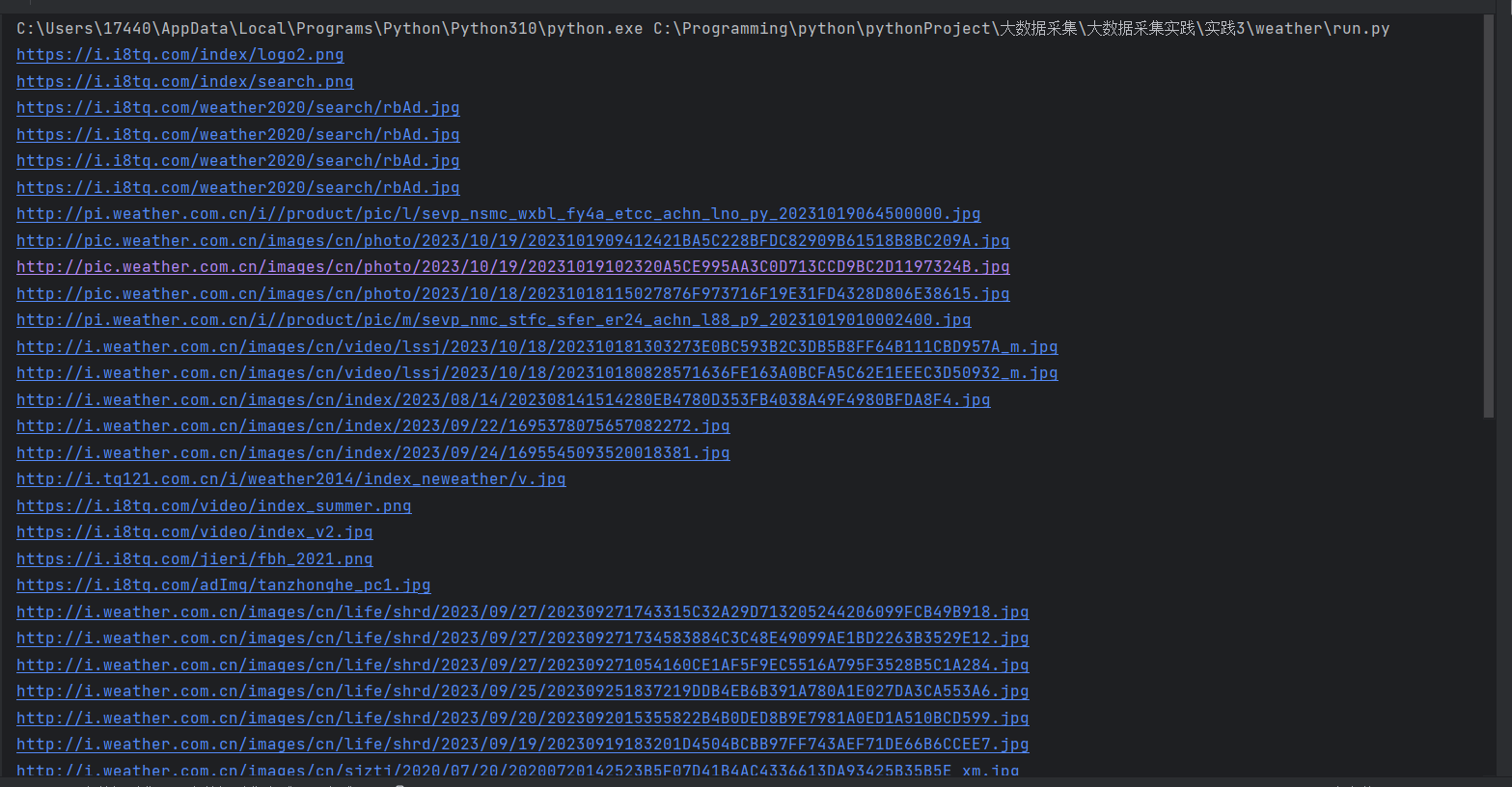
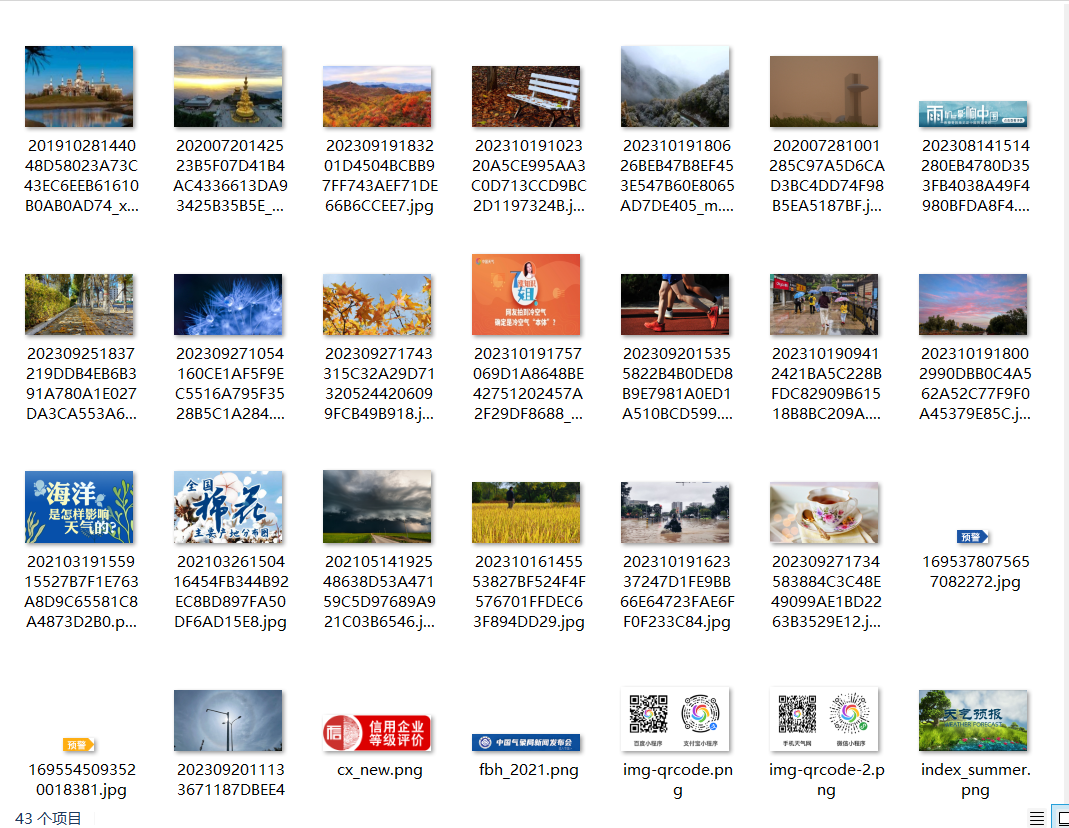
心得体会:
因为气象网没有页数可以翻页所以又爬取了其他网页 与上面代码有几点不同的地方:
1.使用xpath('//img/@src')爬取网页发现很多图片无法加载,这是因为网页采用了懒加载,只有等滑倒下面之后,图片的地址才从xpath('.//img/@data-original')加载到@src
2.因为每一页逻辑是一样的 只需要每页的请求再次调用parse方法就可以了,(如爬取当当网)
如果每页的逻辑不同就另写一个方法,第一个方法返回第二页的地址,因为第一页没有图片地址,要点击进去才能看到图片获取地址(如爬取电影网)
爬取当当网:
当当代码
复制import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangSpider(scrapy.Spider):
name = "dang"
allowed_domains = ["category.dangdang.com"]
start_urls = ["http://category.dangdang.com/cp01.01.02.00.00.00.html"]
base_url='http://category.dangdang.com/pg'
page=1
def parse(self, response):
# 图片//ul[@id="component_59"]/li//img/@src
# src=scrapy.Field()
# 名字//ul[@id="component_59"]/li//img/@alt
# name=scrapy.Field()
# 价格//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# price=scrapy.Field()
li_list = response.xpath('//ul[@id ="component_59"]/li')
for li in li_list:
# 懒加载
src = li.xpath('.//img/@data-original').extract_first()
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
book = ScrapyDangdangItem(src=src)
# 获取一个book就将book交给pipelines
yield book
# 每一页逻辑是一样的 只需要每页的请求再次调用parse方法就可以了
if self.page < 100:
self.page=self.page+1
url=self.base_url+str(self.page)+'-cp01.01.02.00.00.00.html'
# 怎么调用parse方法
yield scrapy.Request(url=url,callback=self.parse)
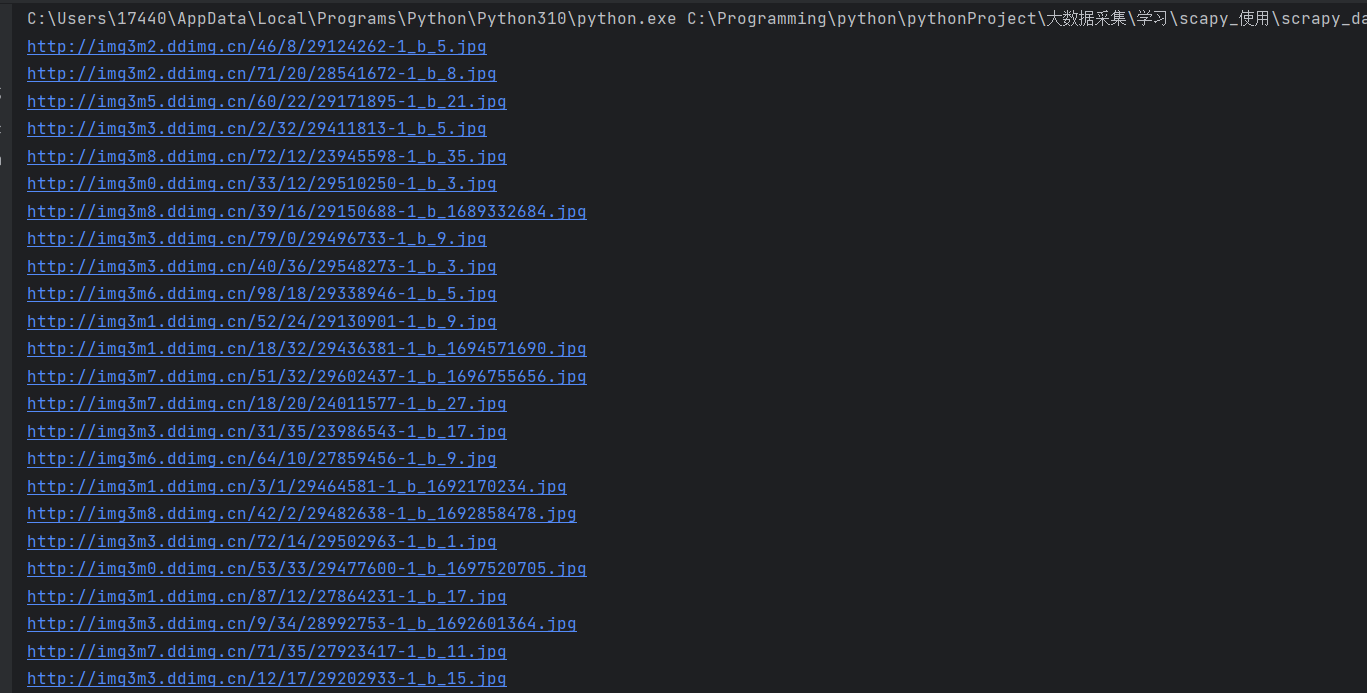
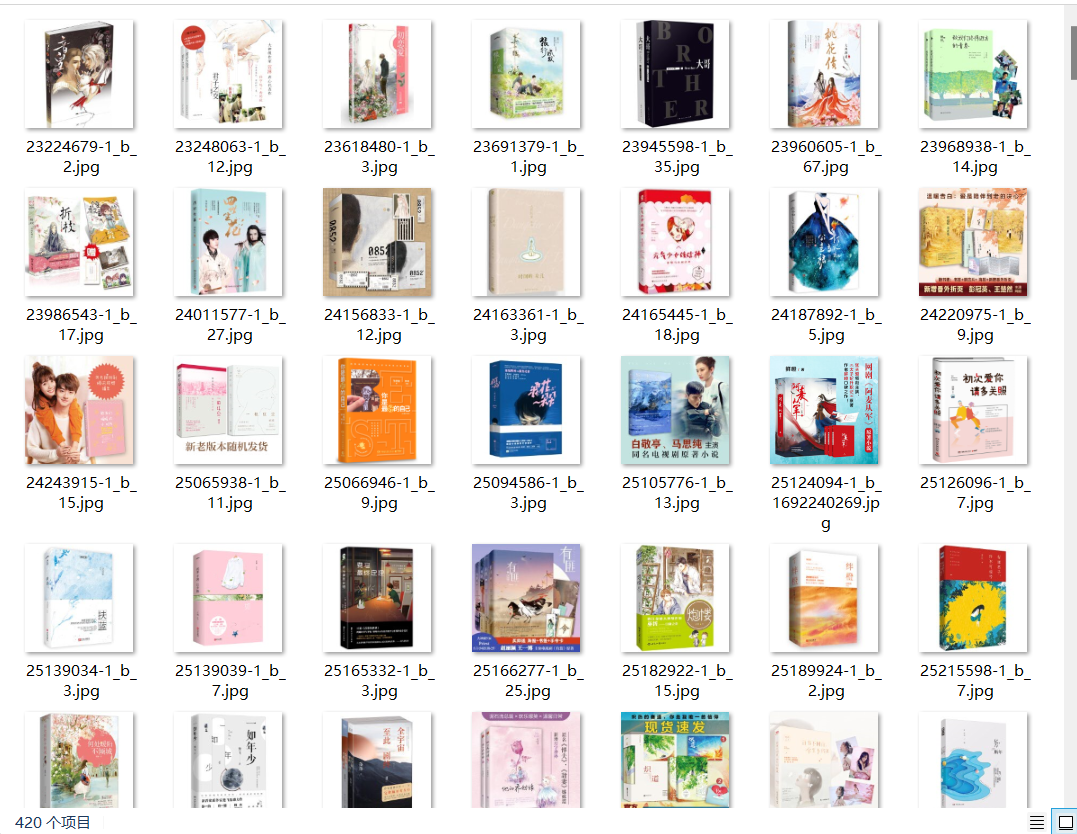
结果如下:
爬取电影网:
电影网代码
复制import scrapy
from scrapy_movie.items import ScrapyMovieItem
class MvSpider(scrapy.Spider):
name = "mv"
allowed_domains = ["www.dytt.to"]
start_urls = ["https://www.dytt.to/html/gndy/china/index.html"]
def parse(self, response):
# 要第一页的名字 和第二页的图片
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# 获取第一页的name 和第二页要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二页的地址
url = 'https://www.dytt.to' + href
print(url)
# 对第二页发起访问
yield scrapy.Request(url=url, callback=self.parse_second, meta={'name': name})
def parse_second(self, response):
src = response.xpath('//div[@id="Zoom"]//img[1]/@src').extract_first()
name = response.meta['name']
movie=ScrapyMovieItem(src=src,name=name)
yield movie
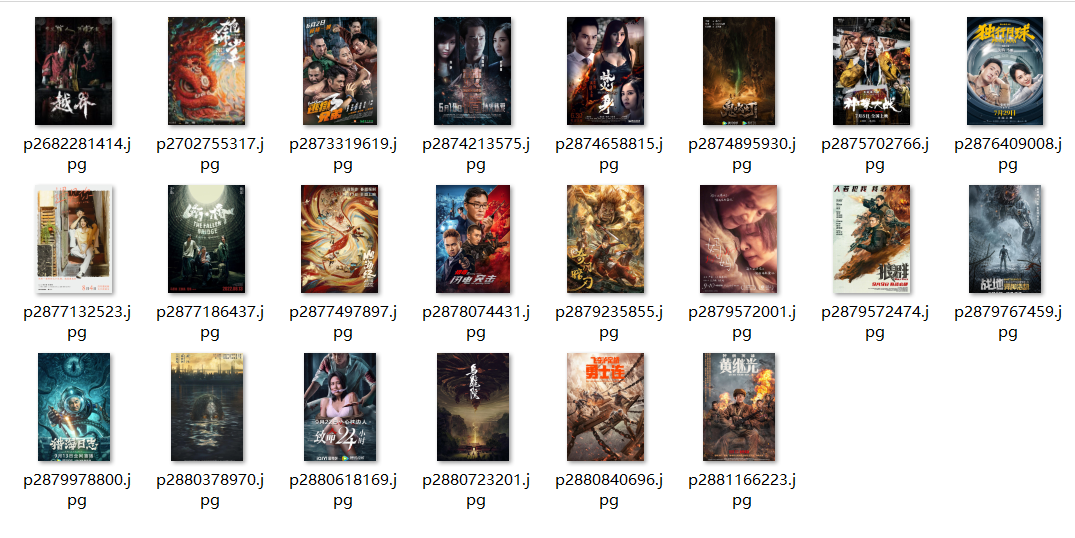
结果如下:
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55
2……
Gitee文件夹链接
实验
复制from typing import Iterable
import scrapy
from scrapy.http import Request
import json
# from ..items import Homework01Item
import pandas as pd
from sqlalchemy.engine import create_engine
class StockSpider(scrapy.Spider):
name = "scrapy_stock"
allowed_domains = ["eastmoney.com"]
start_urls = ["http://38.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406848566904145428_1697696179672&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697696179673"]
def start_requests(self):
for url in self.start_urls:
yield Request(url)
def parse(self, response):
content = response.text[response.text.find('(') + 1:response.text.rfind(')')]
obj = json.loads(content)
data = obj['data']['diff']
goods_list = []
name = ['f12', 'f14', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f15', 'f16', 'f17', 'f18']
count = 0
for li in data:
list = [count]
for n in name:
list.append(li[n])
count += 1
goods_list.append(list)
df = pd.DataFrame(data=goods_list,
columns=['序号', '股票代码', '股票名称', '最新报价', '涨跌幅', '涨跌额', '成交量', '成交额',
'振幅', '最高', '最低', '今开', '昨收'])
df.set_index('序号')
print(df)
engine = create_engine("mysql+mysqlconnector://root:021022@127.0.0.1:3306/mybatis")
df.to_sql("stock", engine, if_exists="replace", index=False)
结果如下:
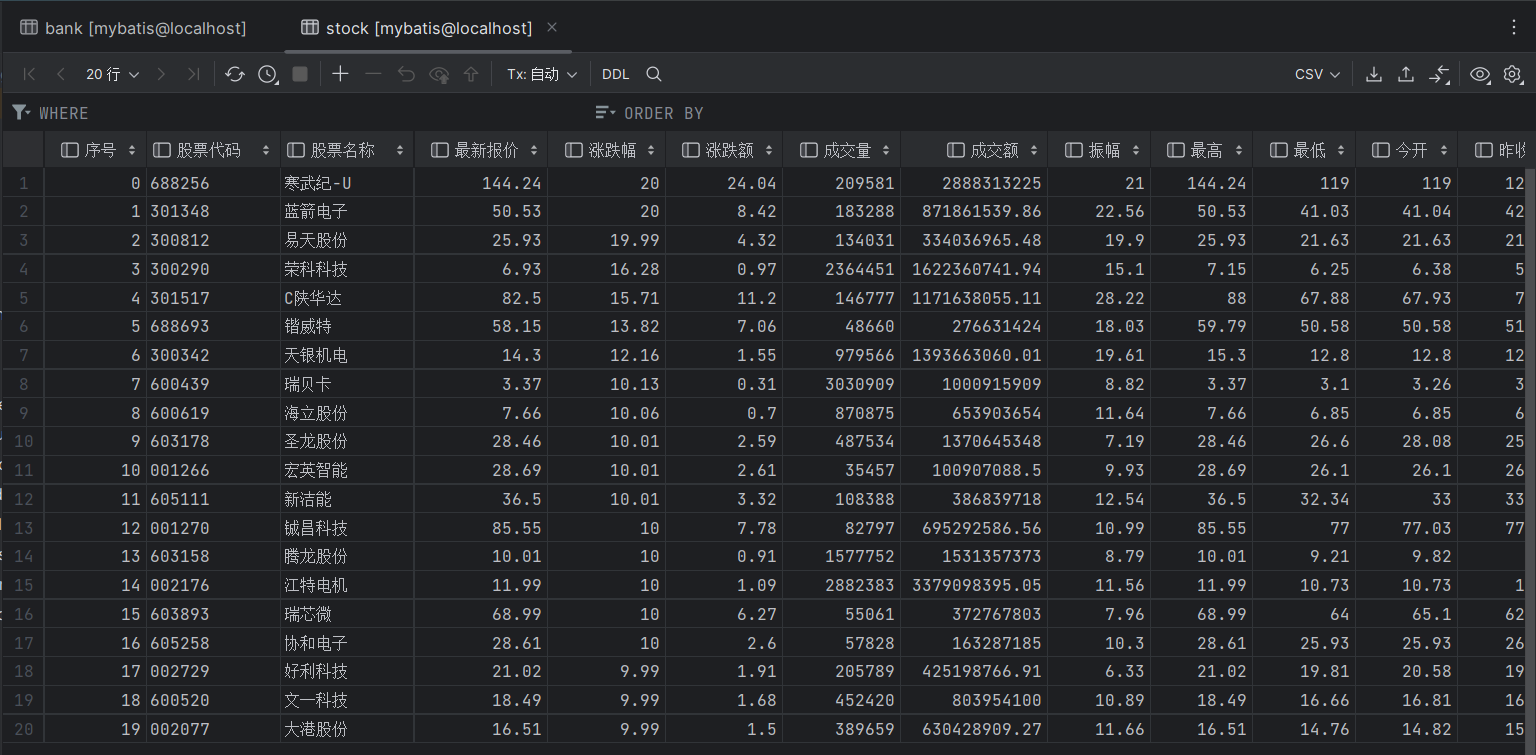
心得体会:
因为该网址的每一页的url不变,所以不能直接解析网址,查找静态的json解析,说明scrapy存在不能动态解析网址的问题
之前写的数据库都是sqlit的数据库,这次又学会了如何创建和插入mysql数据库,收获满满~
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:
Gitee文件夹链接
Currency TBP CBP TSP CSP Time
阿联酋迪拉姆 198.58 192.31 199.98 206.59 11:27:14
实验
复制import scrapy
import pandas as pd
from sqlalchemy.engine import create_engine
class BankSpider(scrapy.Spider):
name = "bank"
allowed_domains = ["www.boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
rows = response.xpath("//tr[position()>1]")
data = []
# 遍历每个<tr>元素
for row in rows:
lis=[]
Currency = row.xpath(".//td[1]/text()").extract_first()
TBP=row.xpath(".//td[2]/text()").extract_first()
CBP=row.xpath(".//td[3]/text()").extract_first()
TSP=row.xpath(".//td[4]/text()").extract_first()
CSP=row.xpath(".//td[5]/text()").extract_first()
Time=row.xpath(".//td[8]/text()").extract_first()
lis.append(Currency)
lis.append(TBP)
lis.append(CBP)
lis.append(TSP)
lis.append(CSP)
lis.append(Time)
data.append(lis)
df = pd.DataFrame(data=data,columns=['Currency', 'TBP', 'CBP', 'TSP', 'CSP', 'Time'])
print(df)
engine = create_engine("mysql+mysqlconnector://root:021022@127.0.0.1:3306/mybatis")
df.to_sql("bank", engine, if_exists="replace", index=False)
pass
结果如下:
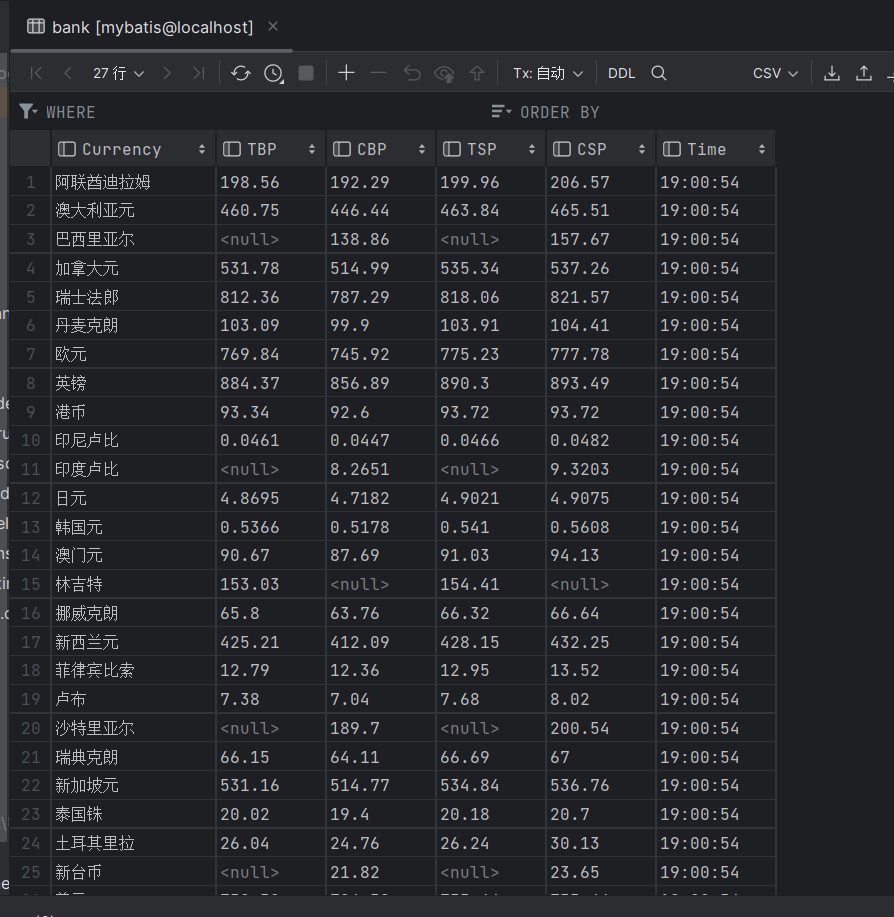
心得体会:
xpath("//tr[position()>1]")表示从列表第二个开始,把表头去除


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律