
作业①:
要求:
在中国气象网(http://www.weather.com.cn)给定城市集的 7日天气预报,并保存在数据库。
输出信息:Gitee 文件夹链接
实验如下:
代码:
复制import sqlite3
import pandas as pd
from bs4 import BeautifulSoup
import urllib.request
from tabulate import tabulate
placeId={
"北京":"101010100","上海":"101020100","广州":"101280101","深圳":"101280601"
}
date = []
weather = []
temp = []
place=[]
count = 1
for i in placeId.keys():
url = "http://www.weather.com.cn/weather/"+placeId[i]+".shtml"
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.1171 SLBChan/103"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
# dammit = UnicodeDammit(data, ["utf-8", "gbk"])
# data = dammit.unicode_markup
data = data.decode('utf-8', 'gbk')
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date.append(li.select('h1')[0].text)
weather.append(li.select('p[class="wea"]')[0].text)
temp.append(li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text)
place.append(i)
count = count + 1
except Exception as err:
print("", end="")
except Exception as err:
print(err)
# 建立数据库
conn = sqlite3.connect('shijian1.db')
cursor = conn.cursor()
# 建立表
cursor.execute('''
CREATE TABLE IF NOT EXISTS shijian1 (
id INTEGER PRIMARY KEY,
address TEXT,
time TEXT,
message TEXT,
temp TEXT
)
''')
# 插入数据
for i in range(count-1):
cursor.execute('''
INSERT INTO shijian1 (
id,
address,
time,
message,
temp
) VALUES (?, ?, ?, ?,?)
''', (
i + 1,
date[i],
place[i],
weather[i],
temp[i]
))
conn.commit()
conn.close()
# 连接到数据库
conn = sqlite3.connect('shijian1.db')
# 创建游标对象
cursor = conn.cursor()
# 执行 SQL 查询语句
cursor.execute('SELECT * FROM shijian1')
# 获取查询结果
results = cursor.fetchall()
# 将查询结果转换为 DataFrame
df = pd.DataFrame(results)
# 获取表格的列名
cursor.execute("PRAGMA table_info(shijian1)")
columns = [column[1] for column in cursor.fetchall()]
# 关闭游标和数据库连接
cursor.close()
conn.close()
# 输出表格(包含列名)
table = tabulate(df, headers=columns, tablefmt='psql')
print(table)
代码结果如下:
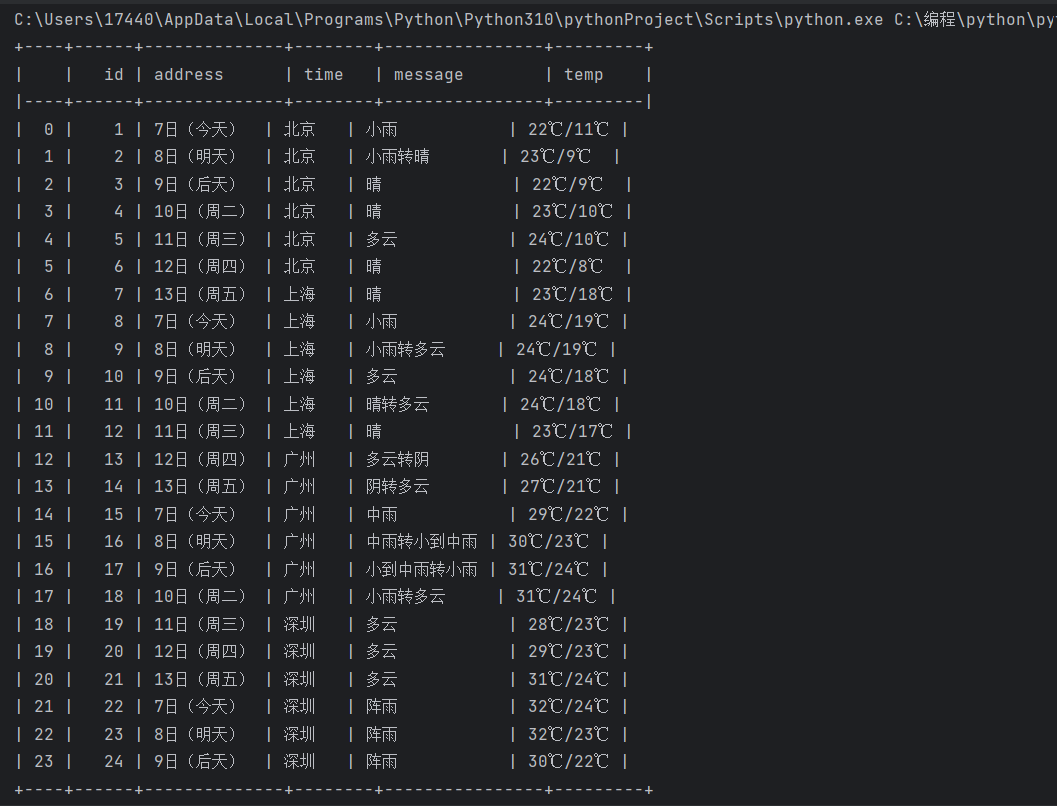
当然可以采用pycharm的数据库可视化工具
查看数据库可视化如下:
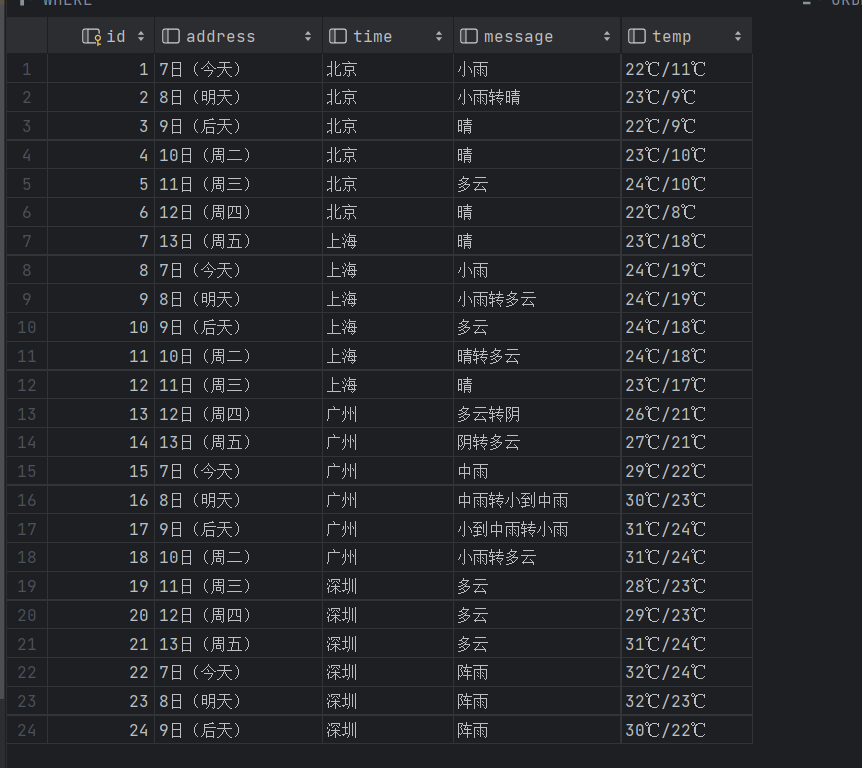
后面结果仅展示数据库可视化
心得体会:
这个实验是复现的一个实验,但是有两个不同点,一个是需要存入不同地区的天气,这个很简单只需要跟翻页一样改变url就行,还有一个是需要存入数据库,然后输出该数据库的表头和列名
作业②
要求:
用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
技巧:在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。根据 URL 可观察请求的参数 f1、f2 可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
输出信息:Gitee 文件夹链接
实验如下:
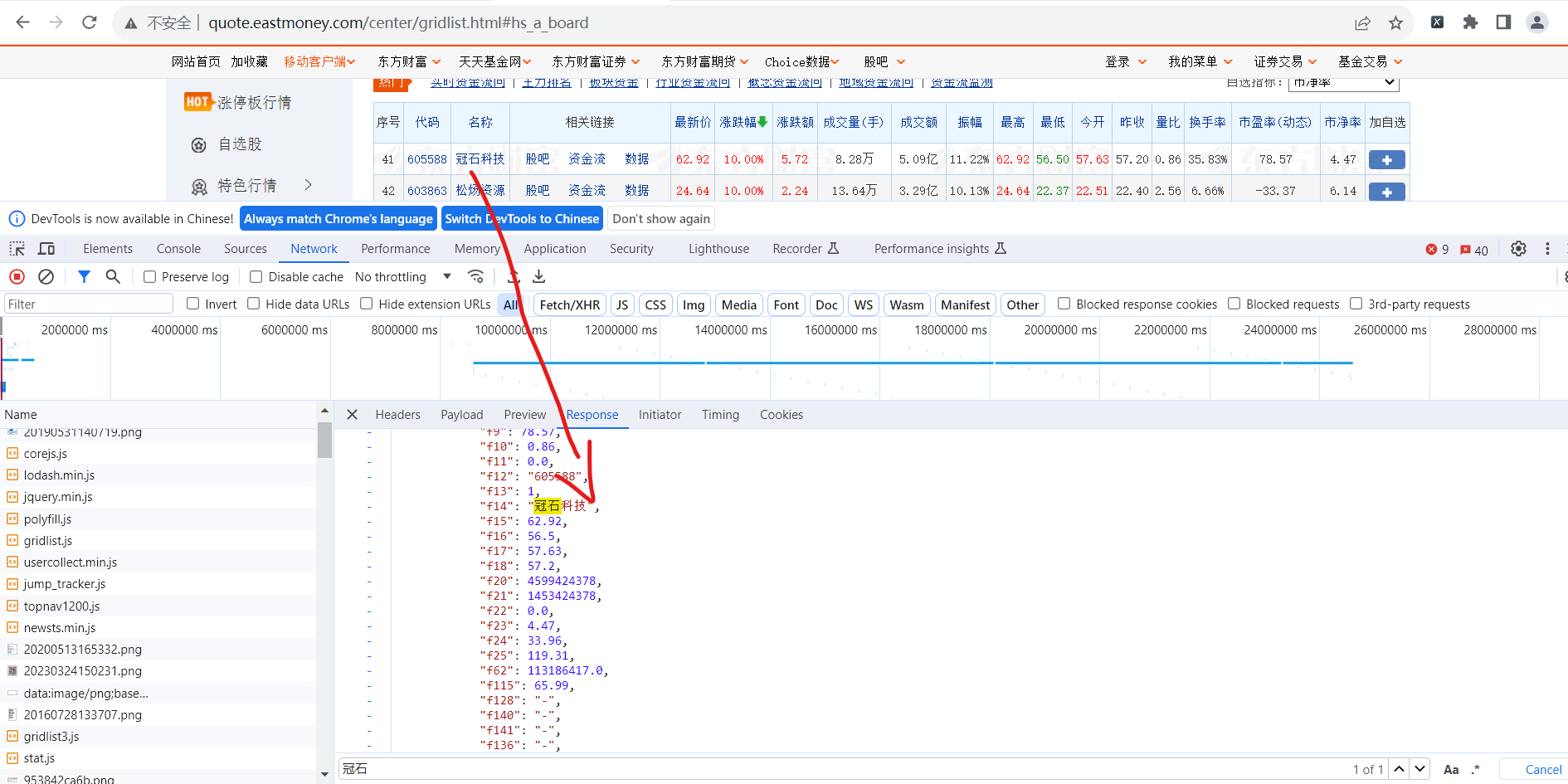
一开始报错:
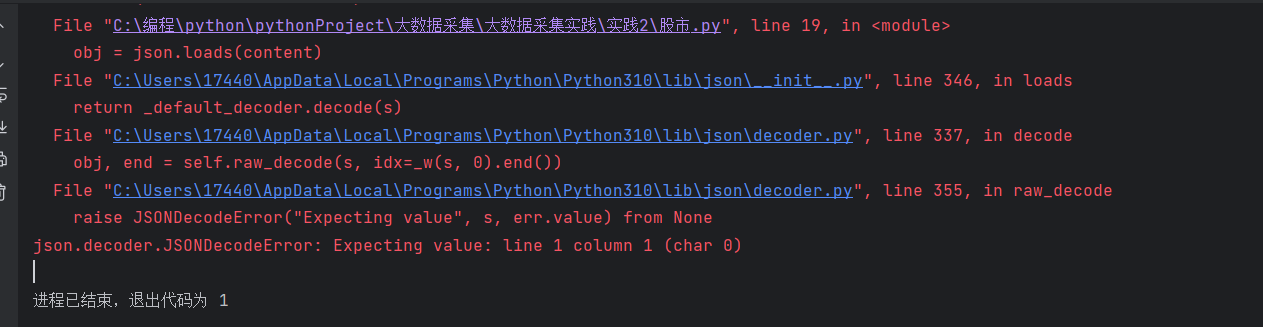
需要将字符串转换成字典的格式
代码:
复制import pandas as pd
import requests
import json
import sqlite3
from tabulate import tabulate
print("你要爬取的页数:")
#x = input()
url = 'http://72.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406687050406440853_1696660482354&pn=3&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1696660482355'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47'
}
response = requests.post(url=url, headers=headers)
content = response.text
content = content.replace("jQuery112406687050406440853_1696660482354(", "")
content = content.replace(");", "")
obj = json.loads(content)
obj = obj['data']['diff']
# 建立数据库
conn = sqlite3.connect('shijian2.db')
cursor = conn.cursor()
# 建立表
cursor.execute('''
CREATE TABLE IF NOT EXISTS shijian2 (
id INTEGER PRIMARY KEY,
stock_code TEXT,
stock_name TEXT,
latest_price REAL,
change_percent REAL,
change_amount REAL,
volume REAL,
turnover REAL,
amplitude REAL,
highest REAL,
lowest REAL,
open_price REAL,
close_price REAL
)
''')
# 插入数据
for item in obj:
cursor.execute('''
INSERT INTO shijian2 (
stock_code,
stock_name,
latest_price,
change_percent,
change_amount,
volume,
turnover,
amplitude,
highest,
lowest,
open_price,
close_price
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
item['f12'],
item['f14'],
item['f2'],
item['f3'],
item['f4'],
item['f5'],
item['f6'],
item['f7'],
item['f15'],
item['f16'],
item['f17'],
item['f18']
))
conn.commit()
conn.close()
# 连接到数据库
conn = sqlite3.connect('shijian2.db')
# 创建游标对象
cursor = conn.cursor()
# 执行 SQL 查询语句
cursor.execute('SELECT * FROM shijian2')
# 获取查询结果
results = cursor.fetchall()
# 将查询结果转换为 DataFrame
df = pd.DataFrame(results)
# 获取表格的列名
cursor.execute("PRAGMA table_info(shijian2)")
columns = [column[1] for column in cursor.fetchall()]
# 关闭游标和数据库连接
cursor.close()
conn.close()
# 输出表格(包含列名)
table = tabulate(df, headers=columns, tablefmt='psql')
print(table)
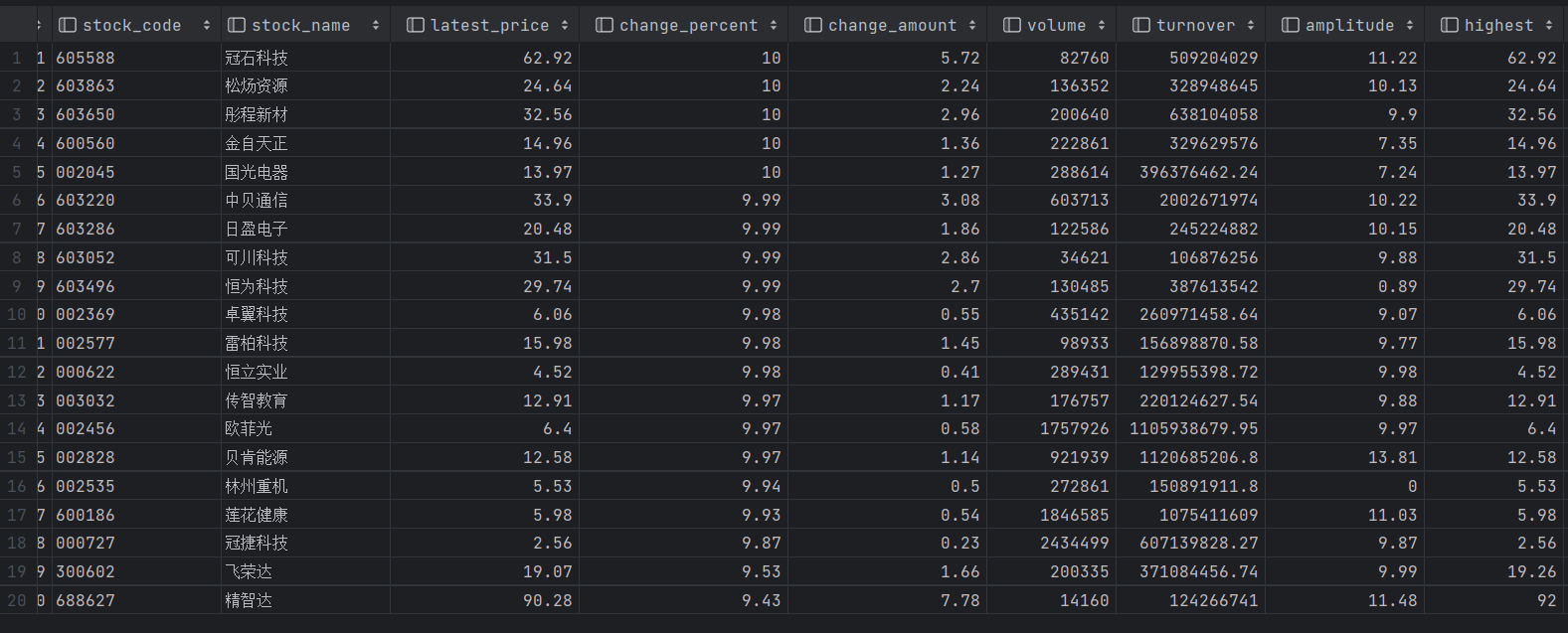
代码结果如下:
爬取第二页为例
心得体会:
一开始使用json.loads()时报错:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0),说明字符串不符合json的格式,需要将字符串转为json格式,
采用content = content.replace("jQuery112406687050406440853_1696660482354(", "")
content = content.replace(");", "")这两个代码把多余部分去除,就可以运行了
作业③:
要求:
爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加
入至博客中。
技巧:分析该网站的发包情况,分析获取数据的 api
输出信息:Gitee 文件夹链接
排名 学校 省市 类型 总分
1 清华大学 北京 综合 969.2
实验如下:
一开始看到省份和类型是q和f的时候很疑惑
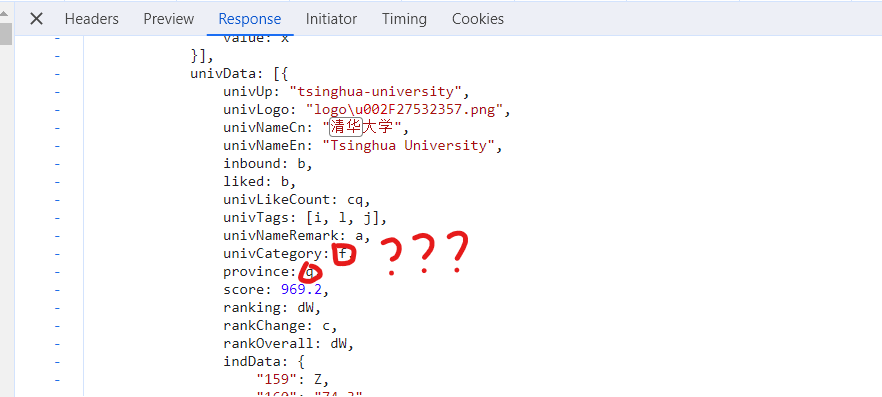
后面通过观察发现最前面的括号和最后面的括号里面的内容是一一对应的,所以我把他们看成字典的keys和values,通过zip结合成字典

浏览器 F12 调试分析的过程录制 Gif

代码:
复制import sqlite3
import requests
import json
import re
import pandas as pd
from tabulate import tabulate
url = 'https://www.shanghairanking.cn/_nuxt/static/1695811954/rankings/bcur/2021/payload.js'
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.1.1171 SLBChan/103"
}
res = requests.get(url=url,headers=headers)
content=res.text
name = re.findall(r'univNameCn:"(.*?)",',content)
print(type(name))
score = re.findall(r',score:(.*?),',content)
keys = re.findall(r'function\((.*?)\)', content)[0]
values=re.findall(r'}\((.*?)\)',content)[0]
values = values.split(",")
keys = keys.split(",")
mapping = dict(zip(keys, values))
univCategory=re.findall(r'univCategory:(.*?),',content)
province=re.findall(r'province:(.*?),',content)
# 建立数据库
conn = sqlite3.connect('shijian3.db')
cursor = conn.cursor()
# 建立表
cursor.execute('''
CREATE TABLE IF NOT EXISTS shijian3 (
id INTEGER PRIMARY KEY,
name TEXT,
province TEXT,
type REAL,
grade REAL
)
''')
# 插入数据
for i in range(400):
cursor.execute('''
INSERT INTO shijian3 (
id,
name,
province,
type,
grade
) VALUES (?, ?, ?, ?, ?)
''', (
i+1,
name[i],
mapping[province[i]],
mapping[univCategory[i]],
score[i]
))
conn.commit()
# 打印数据
cursor.execute('SELECT * FROM shijian3')
rows = cursor.fetchall()
conn.close()
# 连接到数据库
conn = sqlite3.connect('shijian3.db')
# 创建游标对象
cursor = conn.cursor()
# 执行 SQL 查询语句
cursor.execute('SELECT * FROM shijian3')
# 获取查询结果
results = cursor.fetchall()
# 将查询结果转换为 DataFrame
df = pd.DataFrame(results)
# 获取表格的列名
cursor.execute("PRAGMA table_info(shijian3)")
columns = [column[1] for column in cursor.fetchall()]
# 关闭游标和数据库连接
cursor.close()
conn.close()
# 输出表格(包含列名)
table = tabulate(df, headers=columns, tablefmt='psql')
print(table)
代码结果如下:
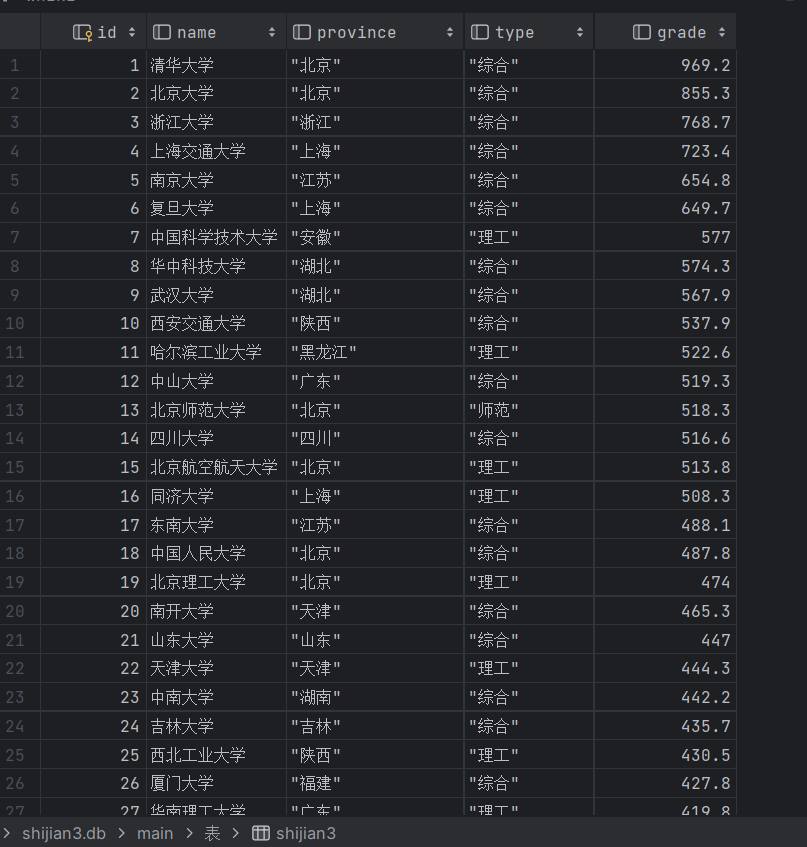
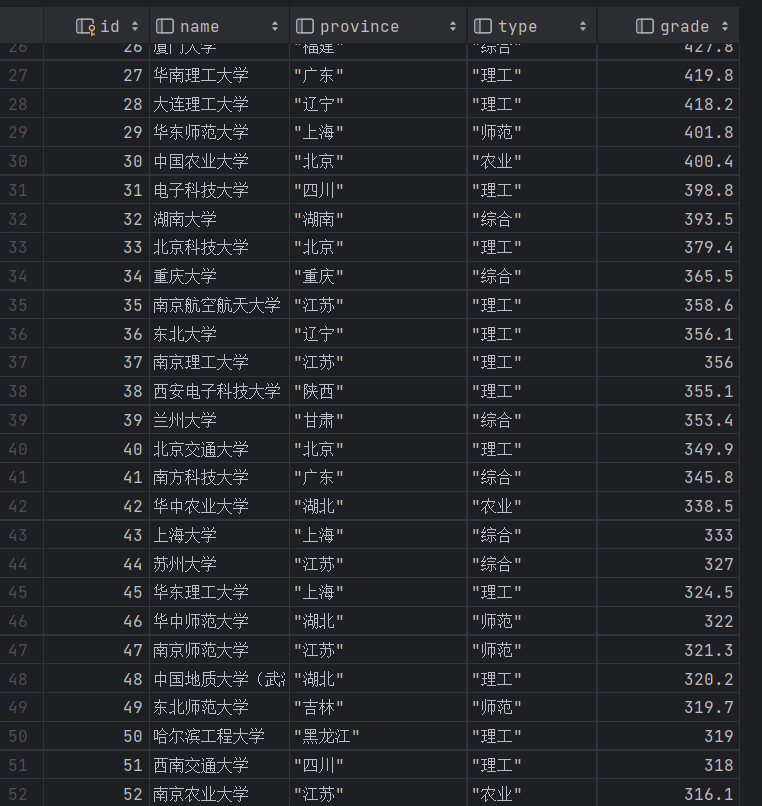
心得体会:
这个实验又进一步采用了正则表达式进行抓包,一个难点就是获取学校排名的省份和类型时,一开始找不到为什么q是北京的意思,f是综合的意思,后来发现在最上面和最上面分别是字典的key和value,所以我采用了zip将其变为字典,然后通过正则表达式得到的q和f的key来获取value值:北京,综合
总结:
难点1:需要建立数据库,并将数据库的数据和列名输出,这里遇到一个问题,一开始没有把之前的数据库删除导致翻页后输出的数据不变
难点2:正则表达式的选取,需要准确的找到并提取信息
难点3:不同网站的json解析也不同,要根据实际来选取合适的办法


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律