filebeat+redis+elk构建多服务器日志收集系统配置文件说明
前言
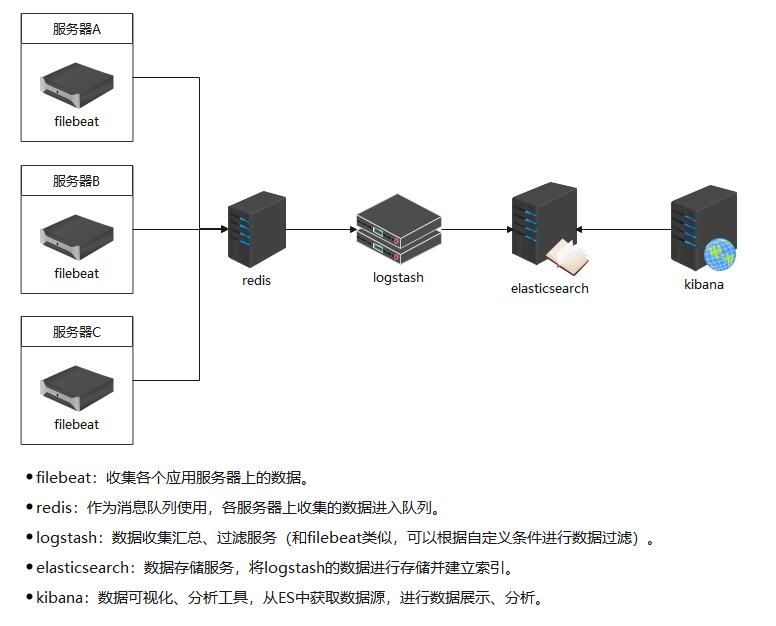
很多时候,我们需要将多台服务器上的日志文件(系统日志、站点日志、业务日志等)汇总到一台日志服务器上,同时需要对日志进行汇总分析、或从大量的日志数据中找到自己需要的日志信息,如何快速汇总和检索日志数据是需要解决的问题。本文主要介绍通过filebeat收集日志,再使用redis作为消息队列进行传输,最终存储到ES中,使用kibana进行统计和查询。本文主要记录配置信息,方便后期查看,原理这些不会介绍,有兴趣的可以看下我之前的博客。
系统结构说明
QA答疑:
- 为什么使用filebeat收集应用服务器上的数据,而不是logstash?答:因为logstash依赖JVM,运行期间占用服务器资源也很大,而filebeat没有依赖,更加轻量,部署很方便。
- 为什么使用redis作为消息队列,kafka是否可以?为什么需要消息队列?答:kafka也可以,根据自身业务需求自行选择即可。采用消息队列是考虑到随着业务服务器的越来越多,直接将filebeat搜集的数据传输给logstash,logstash接收数据会出现延迟甚至是宕机,从而导致数据丢失,通过消息队列作为数据缓冲层可以有效减轻logstash的压力,提高整个架构的稳定性。
- 为什么在redis和ES之间又加了logstash,是不是太多余了?答:这里的logstash不是必须的,可以将队列的里数据存储到ES中,博主这边之所以加一层logstash是因为从业务角度出发,需要将filebeat搜集上来的数据进行有目的的过滤,filebeat虽然也有filter,但是过于简单,不满足我的需求,所以将数据过滤的逻辑放到了logstash中。
配置及启动说明
filebeat
配置文件名:filebeat.yml
配置内容
# ============================== Filebeat 输入配置==============================
filebeat.inputs:
- type: log
enabled: true
# 每 5 秒检测一次文件是否有新的一行内容需要读取
backoff: "5s"
# 是否从文件末尾开始读取
tail_files: false
# 需要收集的数据所在的目录
paths:
- D:/web/openweb/Log/2021/*.log
# 自定义字段,在logstash中会根据该字段来在ES中建立不同的索引
fields:
filetype: apiweb_producelog
# 这里是收集的第二个数据,多个依次往下添加
- type: log
enabled: true
backoff: "5s"
tail_files: false
paths:
- D:/web/openweb/Logs/Warn/*.log
fields:
filetype: apiweb_supplierlog
# ============================== Filebeat modules ==============================
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
# ============================== Filebeat 输出配置====================
output.redis:
enabled: true
# redis地址
hosts: ["192.168.1.103:6379"]
# redis密码,没有密码则不添加该配置项
password: 123456
# 数据存储到redis的key值
key: apilog
# 数据存储到redis的第几个库
db: 1
# 数据存储类型
datatype: list
# ================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
- add_cloud_metadata: ~
- add_docker_metadata: ~
- add_kubernetes_metadata: ~
启动说明
# 进入执行文件目录
cd /d D:/ELK/filebeat-7.14.0
# 启动
.\filebeat -e -c filebeat.yml
logstash
配置文件名:logstash.conf(在bin目录下新建文件)
配置内容
# 输入
input {
redis {
host => "10.188.88.81"
port => 6379
password => "redis"
key => "apilog" #这里的key值和filebeat配置文件中output.redis的key值保持一致
data_type => "list"
db =>1
}
}
# 过滤
filter {
if [fields][filetype] == "apiweb_producelog" {
json {
source => "message"
remove_field => ["_type","beat","offset","tags","prospector"] #移除字段,不需要采集
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"] #匹配timestamp字段
target => "@timestamp" #将匹配到的数据写到@timestamp字段中
}
}
}
# 输出
output {
# 输出到 Elasticsearch,根据filebeat中配置的filetype,在ES中建立不同的索引
if [fields][filetype] == "apiweb_producelog" {
elasticsearch {
# Elasticsearch 地址
hosts => ["localhost:9200"]
# Elasticsearch 索引名
index => "producelog-%{+YYYY.MM.dd}"
}
} else if [fields][filetype] == "apiweb_supplierlog" {
elasticsearch {
hosts => ["localhost:9200"]
index => "supplierlog-%{+YYYY.MM.dd}"
}
} else {
elasticsearch {
hosts => ["localhost:9200"]
index => "apilog-%{+YYYY.MM.dd}"
}
}
}
启动说明
# 进入目录
cd /d D:/ELK/logstash-7.7.0
# 启动服务
bin\logstash -f bin\logstash.conf
elasticsearch
配置文件名:elasticsearch.yml
配置内容
# 数据存放目录
path.data: D:/ELK/elasticsearch-7.7.0/data
# 日志存放目录
path.logs: D:/ELK/elasticsearch-7.7.0/logs
# 服务IP
network.host: 127.0.0.1
# 服务端口
http.port: 9200
启动说明
# 进入目录
cd /d D:/ELK/elasticsearch-7.7.0
# 启动服务
bin\elasticsearch
kibana
配置文件名:kibana.yml
配置内容
# 服务地址,根据实际情况自行调整
server.host: "localhost"
# 服务端口
server.port: 5601
# ES的地址
elasticsearch.hosts: ["http://localhost:9200"]
# kibana的索引
kibana.index: ".kibana"
# 界面语言,默认是en
i18n.locale: "zh-CN"
以上就是filebeat、ELK的全部配置说明,本文主要是作记录使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号