数据库中间件Mycat配置
本文简单介绍mycat中重点配置项的作用和如何简单配置,在学习过程中做个简单记录,防止遗忘。
- 什么是Mycat?
- 为什么使用Mycat?
- 如何使用Mycat?
一、什么是Mycat?
Mycat 是什么?从定义和分类来看,它是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的的Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以用MySQL 原生(Native)协议与多个 MySQL 服务器通信,也可以用 JDBC 协议与大多数主流数据库服务器通信,其核心功能是分表分库,即将一个大表水平分割为 N 个小表,存储在后端 MySQL 服务器里或者其他数据库里。
Mycat 是一个强大的数据库中间件,不仅仅可以用作读写分离、以及分表分库、容灾备份,而且可以用于多租户应用开发、云平台基础设施、让你的架构具备很强的适应性和灵活性,借助于即将发布的 Mycat 智能优化模块,系统的数据访问瓶颈和热点一目了然,根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表映射到不同存储引擎上,而整个应用的代码一行也不用改变。
Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服务。
二、为什么使用Mycat?
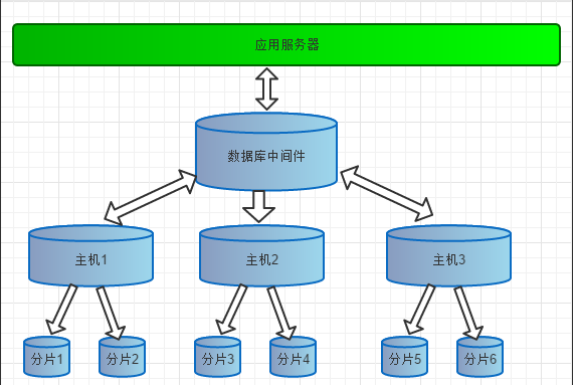
随着业务的不断增长,数据量也越来越大,单库单表存储压力会很大,因此,分库分表就是必须面对的问题。如上图所表示,数据被分到多个分片数据库后,应用如果需要读取数据,就要需要处理多个数据源的数据。如果没有数据库中间件,那么应用将直接面对分片集群,数据源切换、事务处理、数据聚合都需要应用直接处理,原本该是专注于业务的应用,将会花大量的工作来处理分片后的问题,最重要的是每个应用都将重复处理这些工作。所以有了数据库中间件,应用只需要集中与业务处理,大量的通用的数据聚合,事务,数据源切换都由中间件来处理,中间件的性能与处理能力将直接决定应用的读写性能,所以一款好的数据库中间件至关重要。
说到分库分表,不得不说的是数据切分。数据切分根据切分规则主要分成两种:垂直切分、水平切分。
垂直切分:按照不同的表(或者Schema)来切分到不同的数据库(主机)之上。
水平切分:根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面。
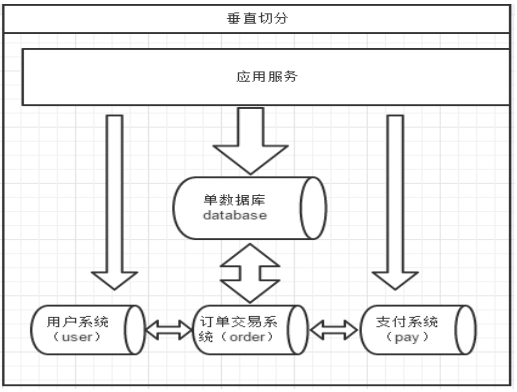
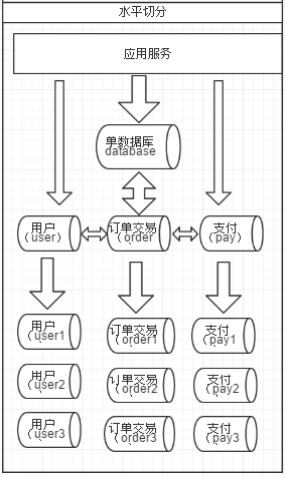
垂直切分和水平切分的优缺点比较:
| 优点 | 缺点 | |
| 垂直切分 |
|
|
| 水平切分 |
|
|
Mycat 通过数据切分解决传统数据库的缺陷,又有了 NoSQL 易于扩展的优点。通过中间代理层规避了多数据源的处理问题,对应用完全透明,同时对数据切分后存在的问题,也做了解决方案。
三、如何使用Mycat?
使用mycat之前需要先熟悉以下几个概念:
逻辑库(schema):通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
逻辑表:分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:分片表,是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
全局表:系统中类似字典表的表,这些表基本上很少变动的表。
分片节点(dataNode):数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机(dataHost):数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则(rule):,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
具体概念可查看官方文档。接下来通过一个简单示例说明如何配置Mycat:
分库分表规则:根据车辆索引,每500辆车分一个数据库(数据库可以部署在不通的服务器上),每个库中每天一张表。
mycat配置如下:
server.xml中只说下连接用户的配置。注意:Mycat默认端口:8066
<user name="root" defaultAccount="true"> <property name="password">123456</property> <property name="schemas">testdb</property> <property name="defaultSchema">testdb</property> </user> <user name="user"> <property name="password">123456</property> <property name="schemas">testdb</property> <property name="readOnly">true</property> <property name="defaultSchema">testdb</property> </user>
schema.xml(配置分库规则):
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="testdb" checkSQLschema="true"> <table name="locationreport1" dataNode="dmark1" subTables="locationreport_202011$01-30,locationreport_202012$01-13" rule="sharding-by-date" /> <table name="locationstatus1" dataNode="dmark1" subTables="locationstatus_202011$01-30,locationstatus_202012$01-13" rule="sharding-by-date" /> <table name="locationalarm1" dataNode="dmark1" subTables="locationalarm_202011$01-30,locationalarm_202012$01-13" rule="sharding-by-date" /> <table name="locationreport2" dataNode="dmark2" subTables="locationreport_202011$01-30,locationreport_202012$01-13" rule="sharding-by-date" /> <table name="locationstatus2" dataNode="dmark2" subTables="locationstatus_202011$01-30,locationstatus_202012$01-13" rule="sharding-by-date" /> <table name="locationalarm2" dataNode="dmark2" subTables="locationalarm_202011$01-30,locationalarm_202012$01-13" rule="sharding-by-date" /> </schema> <dataNode name="dmark1" dataHost="dmark1" database="departmark_1" /> <dataNode name="dmark2" dataHost="dmark2" database="departmark_2" /> <dataHost name="dmark1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="127.0.0.1:3306" user="root" password="123456"> </writeHost> </dataHost> <dataHost name="dmark2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="127.0.0.1:3307" user="root" password="123456"> </writeHost> </dataHost> </mycat:schema>
这里需要注意的如下:
- schema节点中的name一定要和server.xml中配置的一样;
- table节点中的name可以随意定义,不重复即可;dataNode必须和下面的dataNode节点的name相对应;subTables是分表的规则;rule名字随意定义,但是需要和rule.xml文件中对应。
- dataNode节点中dataHost必须和下面的dataHost相对应,database填写真实数据库中的库名
- dataHost节点中writeHost、readHost的配置请查看官方文档,说明的很详细,需要注意的是url填写的是数据库的地址和端口,user和password就是数据库的账号密码
rule.xml(配置分表规则):
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mycat:rule SYSTEM "rule.dtd"> <mycat:rule xmlns:mycat="http://io.mycat/"> <tableRule name="sharding-by-date"> <rule> <columns>LocationDate</columns> <algorithm>partbyday</algorithm> </rule> </tableRule> <function name="partbyday" class="io.mycat.route.function.PartitionByDate"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2020-11-01</property> <property name="sPartionDay">1</property> </function> </mycat:rule>
注意如下:
- tableRule的name需要和schema.xml中table节点的rule属性相对应
- columns是数据库中用于分表的字段
- algorithm是自己定义的分表函数的方法名,和下面的function节点的name相对应
- function节点中的class是mycat内置的分表函数,使用适合自己的即可,如果需要扩展自己的规则需要修改源码
以上是对mycat初步认知的记录,后期研究主从同步时再另行记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号