
字符编码
1 字符编码进化史

(1)UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
(2)在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
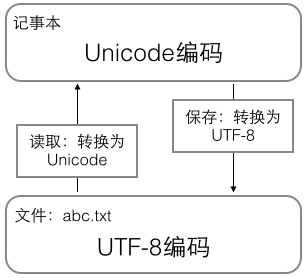
(3)用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
(4)浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器,所以很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。

2 Python的字符串编码
(1)Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes(二进制流)。
(2)字符串是以字符为单位进行处理的,bytes类型是以字节为单位处理的。
(3)Bytes 对象是由单个字节作为基本元素(8位,取值范围 0-255)组成的序列,为不可变对象。Bytes 对象只负责以二进制字节序列的形式记录所需记录的对象,至于该对象到底表示什么(比如到底是什么字符)则由相应的编码格式解码所决定。
(4)Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
(5)strings类型可以被编码(encode)成bytes类型,bytes类型也可以解码(decode)成strings类型。
>>> a = '你好'
>>> type(a)
<class 'str'>
>>> a.encode('utf-8')
b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>> b = b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>> type(b)
<class 'bytes'>
>>> b.decode('utf-8')
'你好'
(6)Pyrhon3.X的默认编码方式为UTF-8。

