【dataX】阿里开源ETL工具——dataX简单上手
一、概述
1.是什么?
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
开源地址:https://github.com/alibaba/DataX
二、简介
1.设计架构
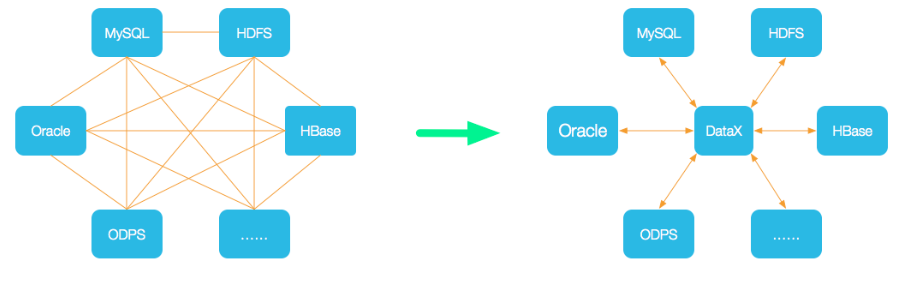
数据交换通过DataX进行中转,任何数据源只要和DataX连接上即可以和已实现的任意数据源同步
2.框架结构

核心组件:
Reader:数据采集模块,负责从源采集数据
Writer:数据写入模块,负责写入目标库
Framework:数据传输通道,负责处理数据缓冲等
以上只需要重写Reader与Writer插件,即可实现新数据源支持
支持主流数据源,详见:https://github.com/alibaba/DataX/blob/master/introduction.md
从一个JOB来理解datax的核心模块组件:
datax完成单个数据同步的作业,称为Job,job会负责数据清理、任务切分等工作;
任务启动后,Job会根据不同源的切分策略,切分成多个Task并发执行,Task就是执行作业的最小单元
切分完成后,根据Scheduler模块,将Task组合成TaskGroup,每个group负责一定的并发和分配Task
三、入门
1.安装
参考官方文档
提取为安装随笔:https://www.cnblogs.com/jiangbei/p/10901201.html
2.使用
核心就是编写配置文件(当前版本使用JSON)
在datax服务器上运行:
python bin/datax.py -r mysqlreader -w hdfswriter
即可获取配置模板
【配置文件】:
先看一个示例:


{ "job": { "setting": { "speed": { "channel": 1 } }, "content": [{ "reader": { "name": "mysqlreader", "parameter": { "username": "", "password": "", "connection": [{ "querySql": [ "SELECT Id,CopId,BrandId,PayType,TradeNo,OutTradeNo,TotalFee,PayTotalFee,PayCashFee,PayCouponFee,RefundFee,ShopId,VipOldCode,VipId,UserCode,PayStatus,IsReverse,CreateDate,UNIX_TIMESTAMP(LastModifiedDate) as LastModifiedDate FROM mall_out_sales_order_pay where brandid=63 order by createDate asc;" ], "jdbcUrl": [ "jdbc:mysql://192.168.12.41:3306/ezp-pay" ] }] } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "", "password": "", "dateFormat": "YYYY-MM-dd hh:mm:ss", "column": [ "Id", "CopId", "BrandId", "PayType", "TradeNo", "OutTradeNo", "TotalFee", "PayTotalFee", "PayCashFee", "PayCouponFee", "RefundFee", "ShopId", "VipOldCode", "VipId", "UserCode", "PayStatus", "IsReverse", "CreateDate", "LastModifiedDate" ], "session": [ "set session sql_mode='ANSI'" ], "preSql": [ "delete from pay_order where brandid=63" ], "connection": [{ "jdbcUrl": "jdbc:mysql://127.0.0.1:3306/ezp-pay", "table": [ "pay_order" ] }] } } }] } }
整个配置文件是一个Job配置文件,以Job为起手根元素,Job下面两个子元素配置项:setting和content,
其中,setting描述任务本身的信息,content描述源(reader)和目的端(writer)的信息:

其中,content下又分为reader和writer两块,分别对应源端和目的端:

各reader与writer插件的文档直接点击对应的文件夹进入doc即可!
3.示例
编写一个Mysql到本地打印的Job:
根据Mysqlreader插件编写配置文件:
{ "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root", "column": [ "id", "age", "name" ], "connection": [ { "table": [ "girl" ], "jdbcUrl": [ "jdbc:mysql://192.168.19.129:3306/mysql" ] } ] } }, "writer": { "name": "streamwriter", "parameter": { "print":true } } } ] } }
根据自检脚本(文件颜色浅绿色),可以知道需要是可执行文件,添加权限:
chmod +x mysqltest.json
使用运行命令,运行即可:(进入bin目录运行命令如下)
python datax.py ../job/mysqltest.json
有时是希望灵活一点的自定义的配置,则可参考如下json配置:
{ "job": { "setting": { "speed": { "channel":1 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root", "connection": [ { "querySql": [ "select db_id,on_line_flag from db_info where db_id < 10;" ], "jdbcUrl": [ "jdbc:mysql://bad_ip:3306/database", "jdbc:mysql://127.0.0.1:bad_port/database", "jdbc:mysql://127.0.0.1:3306/database" ] } ] } }, "writer": { "name": "streamwriter", "parameter": { "print": false, "encoding": "UTF-8" } } } ] } }
四、拓展
1.调度
任务很少,情景简单的情况下,使用Linux自带的corntab即可,当然,正常的时候推荐使用调度平台
这里推荐airflow(其他相关的azkaban、oozie等调度不展开)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号