阿里巴巴大数据之路——数据技术篇
一、整体架构

从下至上依次分为数据采集层、数据计算层、数据服务层、数据应用层
数据采集层:以DataX为代表的数据同步工具和同步中心
数据计算层:以MaxComputer为代表的离线数据存储和计算平台
数据服务层:以RDS为代表的数据库服务(接口或者视图形式的数据服务)
数据应用层:包含流量分析平台等数据应用工具
二、数据采集(离线数据同步)
数据采集主要分为日志采集和数据库采集。日志采集暂略(参考书籍原文)。我们主要运用的是数据库采集(数据库同步)。
通常情况下,我们需要规定原业务系统表增加两个字段:创建时间、更新时间(或者至少一个字段:更新时间)
数据同步主要可以分为三大类:直连同步、数据文件同步、数据库日志解析同步
1.直连同步
通过规范好的接口和动态连接库的方式直接连接业务库,例如通过ODBC/JDBC进行直连
当然直接连接业务库的话会对业务库产生较大压力,如果有主备策略可以从备库进行抽取,此方式不适合直接从业务库到数仓的情景
2.数据文件同步
从源系统生成数据文本文件,利用FTP等传输方式传输至目标系统,完成数据的同步
为了防止丢包等情况,一般会附加一个校验文件 ,校验文件包含数据量、文件大小等信息
为了安全起见还可以加密压缩传输,到目标库再解压解密,提高安全性
3.数据库日志同步
主流数据库都支持日志文件进行数据恢复(日志信息丰富,格式稳定),例如Oracle的归档日志
(数据库相关日志介绍,参考:https://www.cnblogs.com/jiangbei/p/9366805.html)
4.阿里数据仓库同步方式
1)批量数据同步
要实现各种各样数据源与数仓的数据同步,需要实现数据的统一,统一的方式是将所有数据类型都转化为中间状态,也就是字符串类型。以此来实现数据格式的统一。
产品——阿里DataX:多方向高自由度异构数据交换服务产品,产品解决的主要问题:实现跨平台的、跨数据库、不同系统之间的数据同步及交互。
产品简介:https://yq.aliyun.com/articles/59373
开源地址:https://github.com/alibaba/DataX
更多的介绍将会通过新开随笔进行介绍!(当然还有其他主流的数据同步工具例如kettle等!)
2)实时数据同步
实时数据同步强调的是实时性,基本原理是通过数据库的日志(MySQL的bin-log,Oracle的归档日志等)实现数据的增量同步传输。
产品——阿里TimeTunnel(简称TT)。TT产品本质是一个生产者、消费者模型的消息中间件
3)常见问题
1.增量数据与全量数据的合并
主要的场景是数据同步中周期全量同步,对应的解决方案是每次只同步变更的数据,然后和上一周期合并,形成最新的全量数据(选择此方案的原因是绝大多数大数据平台不支持update操作)
具体的方案主要有union的联合操作(可以通过生成增量中间表detal)与阿里主推的全外连接full outer join+全量覆盖insert overwrite的形式。实例参考如下:


SQL的Join语法有很多, inner join(等值连接) 只返回两个表中联结字段相等的行, left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录, right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录, 假设我们有两张表。Table A 是左边的表。Table B 是右边的表。其各有四条记录,其中有两条记录name是相同的,如下所示: A表 id name 1 Pirate 2 Monkey 3 Ninja 4 Spaghetti B表 id name 1 Rutabaga 2 Pirate 3 Darth Vade 4 Ninja 让我们看看不同JOIN的不同。 FULL [OUTER] JOIN (1) SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name TableA.name = TableB.name 的情况,A和B的交集有两条数据,那么 FULL OUTER JOIN的结果集, 应该是2+2+2=6条,即上面的交集,再加剩下的四条数据,没有匹配,以null补全。 结果集 (TableA.) (TableB.) id name id name 1 Pirate 2 Pirate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vade Full outer join 产生A和B的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。 可以使用IFNULL判断。 (2) SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableA.id IS null OR TableB.id IS null 添加这个 where 条件,可以排除掉两表的数据交集。 结果集 (TableA.) (TableB.) id name id name 2 Monkey null null 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vade 产生A表和B表没有交集的数据集。 UNION 与 UNION ALL UNION 操作符用于合并两个或多个 SELECT 语句的结果集。 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。UNION 只选取记录,而UNION ALL会列出所有记录。 (1)SELECT name FROM TableA UNION SELECT name FROM TableB 新结果集 name Pirate Monkey Ninja Spaghetti Rutabaga Darth Vade 选取不同值。 (2)SELECT name FROM TableA UNION ALL SELECT name FROM TableB 新结果集 name Pirate Monkey Ninja Spaghetti Rutabaga Pirate Darth Vade Ninja 全部列出来。
这里简要给出中间增量表detal表的SQL脚本:
insert overwrite table dwd_tb_delta partition (fq_day='${bizday}') select t.vhc_no as vhc_no,--号牌号码 t.passbook_id as passbook_id,--通行证编号 t.vhc_type_no as vhc_type_no,--车辆类型 from( select t0.vhc_no as vhc_no,--号牌号码 t0.passbook_id as passbook_id,--通行证编号 t0.vhc_type_no as vhc_type_no,--车辆类型 row_number() over (partition by t0.vhc_no order by t0.gmt_invalid desc) as rn from ods_vhc_passbook_info_tfcvideo_jj t0 where fq_day='${bizday}' ) t r(t.date_type_no) = t2.lyxtdm where t.rn = 1 --取最新的数据 ; ---------- insert overwrite table dwd_tb_dd partition (fq_day='${bizday}') select p.vhc_no, --号牌号码 p.passbook_id, --通行证编号 p.vhc_type_no, --车辆类型 from( select *, row_number() over (partition by t.vhc_no order by t.gmt_invalid desc) as rn from ( select * from dwd_wp_jj_zdcltxzxx_delta where fq_day='${bizday}' union all select * from dwd_wp_jj_zdcltxzxx_dd where fq_day='${bizday-1}' ) t ) p where p.rn = 1 ;
//阿里方案待研究。
三、实时技术
实时技术主要分为:数据采集->数据处理->数据存储->数据服务
流式技术架构图如下图所示:
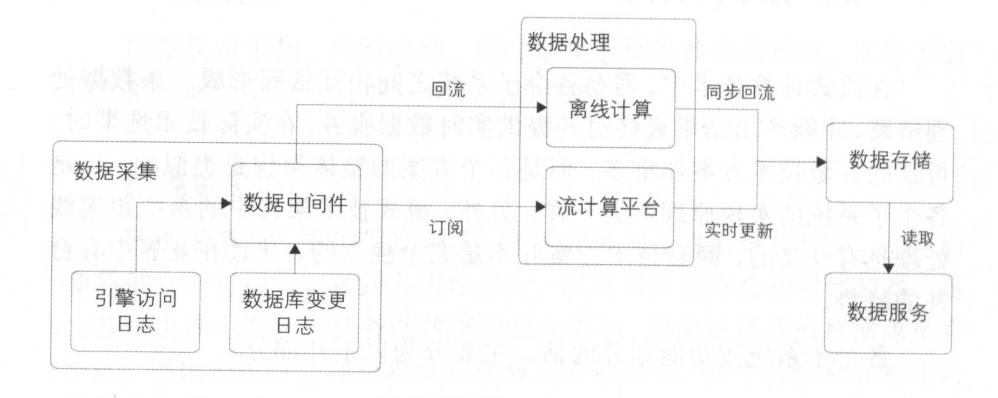
1.数据采集
实时数据的处理需要实时的采集,采集源一般来自数据库变更日志、引擎访问日志等
实时采集不是一条一条采集,而是根据一些限制条件,一般是数据大小限制(如满512KB采集)、时间阈值限制(如30秒采集)
采集的数据需要一个数据交换平台(中间件)分发给下游,一般选择kafka等
2.数据处理
从消息中间件中出来的数据,分发给下游的流数据处理平台。一般有strom、spark streaming以及新兴的flink
阿里内部使用的是stream compute
3.数据存储
存储数据库主要分为关系型数据库、列数据库、文档数据库等
实时的存储需要支持高并发的读写,根据hbase的优势
1 列的可以动态增加,并且列为空就不存储数据,节省存储空间. 2 Hbase自动切分数据,使得数据存储自动具有水平scalability. 3 Hbase可以提供高并发读写操作的支持
一般选择hbase、mongonDB等
4.数据服务
数据服务例如oneService等,后续详细介绍
数据模型分层,基本和离线数据一致,分为五层:ODS DWD DWS ADS MID

 浙公网安备 33010602011771号
浙公网安备 33010602011771号