大数据入门第二十二天——spark(二)RDD算子(1)
一、RDD概述
1.什么是RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
2.RDD属性
1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
3.分类
主要分成Transformations(懒加载)和Actions,即转换算子和行动算子
更多的算子的具体介绍,参考官方文档:http://spark.apache.org/docs/latest/rdd-programming-guide.html#overview
博文参考:https://www.cnblogs.com/zlslch/p/5723857.html
4.创建RDD
1)由一个已经存在的Scala集合创建。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
2)由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
val rdd2 = sc.textFile("hdfs://node1.itcast.cn:9000/words.txt")
但是RDD里面是没有具体数据的,里面只记录了一些元数据(行动时再加载)
二、RDD编程API
1.Transformation
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
常用转换算子如下:更多,参考官网
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
|
sample(withReplacement, fraction, seed) |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
|
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
cartesian(otherDataset) |
笛卡尔积 |
|
pipe(command, [envVars]) |
|
|
coalesce(numPartitions) |
|
|
repartition(numPartitions) |
|
|
repartitionAndSortWithinPartitions(partitioner) |
// 更多,参考官网
2.Action
|
动作 |
含义 |
|
reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
|
takeOrdered(n, [ordering]) |
|
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
|
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
强烈推荐的RDD Examples:http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html
三、使用IDEA编写WordCount程序
1.创建maven工程
2.引入依赖与插件


<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.jiangbei.spark</groupId> <artifactId>HelloSpark</artifactId> <version>1.0</version> <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.10.6</scala.version> <spark.version>1.6.3</spark.version> <hadoop.version>2.6.4</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-make:transitive</arg> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <!-- 不指定main方法,则后续运行时可以动态给出,程序也可以有多个main方法--> <!-- <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>cn.itcast.spark.WordCount</mainClass> </transformer> </transformers> --> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
3.编写wordcount程序
package cn.jiangbei.spark
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wc")
// 通向spark的入口,非常重要
val sc = new SparkContext(conf)
// 完成wordCount
sc.textFile(args(0)).flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).sortBy(_._2, false).saveAsTextFile(args(1))
sc.stop()
}
}
4.打包
这里打包老是会出现一个奇怪的问题:zk01明明是另外的一个项目,也是毫无关联的
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile (default) on project HelloSpark:
Execution default of goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile failed:
For artifact {com.jiangbei:zk01:null:war}: The version cannot be empty. -> [Help 1]
已解决:
通过-X选项查看DEBUG日志:mvn -X package(IDEA右键直接可以DEBUG打包),结合网友博文:https://blog.csdn.net/xktxoo/article/details/78005817
删除WARN里面的invlid的jar,重新导入(maven 项目 reimport),打包即可(不过此处依然出现很多其他WARNING,待跟进)
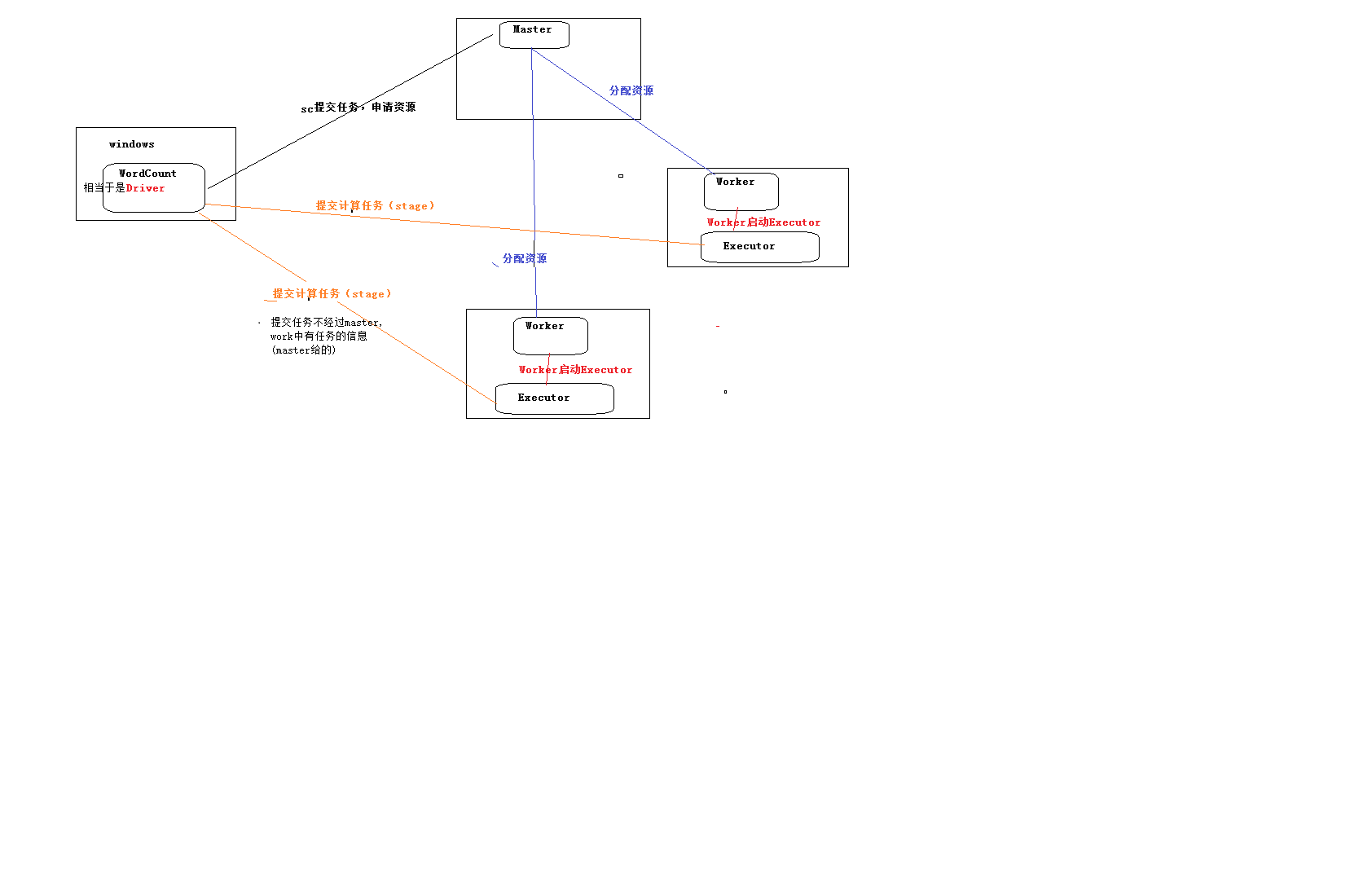
WC执行流程:

Spark提交任务流程:
远程DEBUG(简单的方法):
object WordCount {
def main(args: Array[String]) {
//非常重要,是通向Spark集群的入口
val conf = new SparkConf().setAppName("WC")
// 需要先使用Maven打包,使用shade打的比较大而全的包
.setJars(Array("C:\\HelloSpark\\target\\hello-spark-1.0.jar"))
.setMaster("spark://node-1.itcast.cn:7077")
val sc = new SparkContext(conf)
//textFile会产生两个RDD:HadoopRDD -> MapPartitinsRDD
sc.textFile(args(0)).cache()
// 产生一个RDD :MapPartitinsRDD
.flatMap(_.split(" "))
//产生一个RDD MapPartitionsRDD
.map((_, 1))
//产生一个RDD ShuffledRDD
.reduceByKey(_+_)
//产生一个RDD: mapPartitions
.saveAsTextFile(args(1))
sc.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号