大数据入门第二十天——scala入门(二)scala基础01
一、基础语法
1.变量类型

// 上表中列出的数据类型都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。
2.变量声明——能用val的尽量使用val!!!
//使用val定义的变量值是不可变的,相当于java里用final修饰的变量 val i = 3 //使用var定义的变量是可变得,在Scala中鼓励使用val var j = "hello" //Scala编译器会自动推断变量的类型,必要的时候可以指定类型 var k: String = "world"
3.条件表达式
常规判断
val i = 10
if (i < 100) {
println("i<100")
}
//支持混合类型表达式,将结果返回给变量
val z = if (x > 1) 1 else "error"
4.块表达式
//在scala中{}中课包含一系列表达式,块中最后一个表达式的值就是块的值
//下面就是一个块表达式
val result = {
if (x < 0){
-1
} else if(x >= 1) {
1
} else {
"error"
}
}
5.循环

to是闭区间;until是左闭右开
//for(i <- 表达式),表达式1 to 10返回一个Range(区间)
//每次循环将区间中的一个值赋给i
for (i <- 1 to 3) {
println(i)
}
//for(i <- 数组)
for (i <- Array(1,3,5)) {
println(i)
}
//高级for循环
//每个生成器都可以带一个条件,注意:if前面没有分号
for (i <- 1 to 3; if i > 2) {
println(i)
}
//for推导式:如果for循环的循环体以yield开始,则该循环会构建出一个集合
//每次迭代生成集合中的一个值
val j = for (i <- 1 to 3) yield i * 2
println(j)
6.方法/函数声明
方法
def functionName ([参数列表]) : [return type]
def m1(x: Int, y: String): String = {
// 可以省略return,编译器会自动推断
x + y
}
函数(有点儿像拉姆达表达式)
val f = (x:Int) => 2*x
在函数式编程语言中,函数是“头等公民”,它可以像任何其他数据类型一样被传递和操作
结合Java8中拉姆达表达式,还是阔以理解的
def m1(f: (Int, Int) => Int): Int = {
f(1,2)
}
val f = (x:Int, y:Int) => x +y
m1(f)
方法与函数的转换:
def m1(x:Int, y:Int): Int = {
x + y
}
// 使用下划线进行方法与函数的转换
val f = m1 _
使用的话,例如Java8中的集合的使用,list.map(),里边可以传入一个拉姆达表达式
二、数组、映射、元组、集合
1.数组
Scala 语言中提供的数组是用来存储固定大小的同类型元素,数组对于每一门编辑应语言来说都是重要的数据结构之一。
声明数组变量并不是声明 number0、number1、...、number99 一个个单独的变量,而是声明一个就像 numbers 这样的变量,然后使用 numbers[0]、numbers[1]、...、numbers[99] 来表示一个个单独的变量。数组中某个指定的元素是通过索引来访问的。
数组的第一个元素索引为0,最后一个元素的索引为元素总数减1。
声明:
// 初始化一个长度为8的定长数组,其所有元素均为0
// 注意:如果new,相当于调用了数组的apply方法,直接为数组赋值
val arr = new Array[Int](3)
arr(0) = 3
// 调用toBuffer,可以看到数组的内容,才不会打印hashCode值,其他类型类似
println(arr.toBuffer)
// 声明时直接赋值
val arr2 = Array("i","love","china")
println(arr2.toBuffer)
遍历:
// 遍历数组
for (x <- arr2) {
print(x)
}
var total = 0
// 遍历并求和(类似于0 until arr.length),这里使用的是IDEA的提示
for (i <- arr.indices) {
total += arr(i)
}
println(total)
// 求最大值
var max = arr(0)
for (i <- 1 until arr.length) {
if (arr(i) > max) max = arr(i)
}
转换:

常用操作:
//sum求和(数组与阿奴必须是数值型数据)
println(change.sum)
//min max 输出数组中最小和最大元素
println(change.min)
println(change.max)
//使用sorted方法对数组或数组缓冲进行升序排序,这个过程不会修改原始数组
val sortArr = ab.sorted
for(elem <- sortArr)
print(elem + ", ")
//使用比较函数sortWith进行排序
val sortArr = ab.sortWith(_>_)
//数组显示
println(sortArr.mkString("|"))
println(sortArr.mkString("startFlag","|","endFlag"))
可变数组ArrayBuffer,参考:https://blog.csdn.net/wild46cat/article/details/53820349
2.映射
Map在scala中就叫映射
Map 有两种类型,可变与不可变,区别在于可变对象可以修改它,而不可变对象不可以。
默认情况下 Scala 使用不可变 Map。如果你需要使用可变集合,你需要显式的引入 import scala.collection.mutable.Map 类
在 Scala 中 你可以同时使用可变与不可变 Map,不可变的直接使用 Map,可变的使用 mutable.Map。
赋值取值也是很直观方便的:
package com.jiangbei
import scala.collection.mutable
object ScalaDemo {
def main(args: Array[String]): Unit = {
// 定义Map
val score = mutable.Map("小明" -> 100, "小红" -> 99, "小强" -> 65)
// 追加内容
score += ("小方" -> 61)
// 取值
println(score("小明"))
println(score.get("小明"))
val high = mutable.Map("a" -> 1)
// 赋值 high("a") = 2 println(high) } }
常用基本操作:
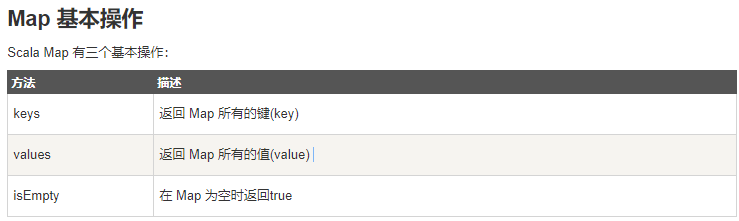
// 定义Map
val score = mutable.Map("小明" -> 100, "小红" -> 99, "小强" -> 65)
// 追加内容
score += ("小方" -> 61)
// 遍历key
score.keys.foreach(println)
// 遍历value
score.values.foreach(println)
score.keys.foreach { k =>
print(k)
println(score(k))
}
Map合并:
// 合并
val score3 = score ++ score2
3.元组
映射是K/V对偶的集合,对偶是元组的最简单形式,元组可以装着多个不同类型的值。
定义:
// 定义元组
val t = (1, "love", 3.14)
// 也可以通过如下方式定义元组
/*元组的实际类型取决于它的元素的类型,比如 (99, "runoob") 是 Tuple2[Int, String]。
('u', 'r', "the", 1, 4, "me") 为 Tuple6[Char, Char, String, Int, Int, String]。
目前 Scala 支持的元组最大长度为 22。对于更大长度你可以使用集合,或者扩展元组。*/
val t3 = new Tuple3(3.15, 100, "love")
// 访问元组,通过下标的形式,下标从1开始
println(t._1)
迭代:
// 迭代元组
t.productIterator.foreach{e => println(e)}
拉链:
可以通过arr.zip(arr2);完成两个数组的绑定,结合成一个映射
4.集合
Scala的集合有三大类:序列Seq、集Set、映射Map,所有的集合都扩展自Iterable特质
在Scala中集合有可变(mutable)和不可变(immutable)两种类型,immutable类型的集合初始化后就不能改变了(注意与val修饰的变量进行区别)
1.Seq,是一组有序的元素。
2.Set,是一组没有重复元素的集合。
3.Map,是一组k-v对。
更多介绍,参考:https://blog.csdn.net/bitcarmanlee/article/details/72795013
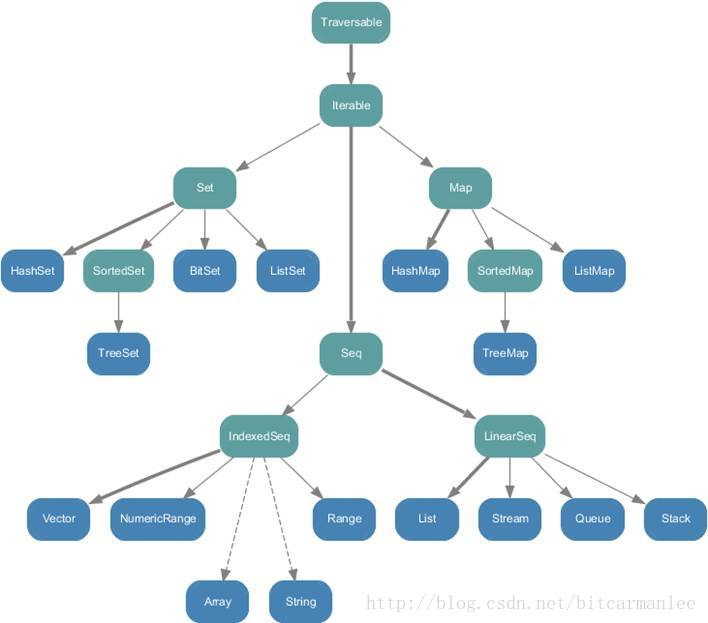
序列:
在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。
// 定义List,ListBuffer为可变的,当然,List[String]这个类型是可以省略的,因为Scala会进行类型推导
val names: List[String] = List("i", "love", "china")
val score = 1 :: 2 :: 3
val ages: ListBuffer[Int] = ListBuffer(1, 2, 3, 4)
// ListBuffer可变
ages(0) = 2
// 追加元素
ages.append(5)
ages += 6
Set:
package cn.itcast.collect
import scala.collection.immutable.HashSet
object ImmutSetDemo extends App{
val set1 = new HashSet[Int]()
//将元素和set1合并生成一个新的set,原有set不变
val set2 = set1 + 4
//set中元素不能重复
val set3 = set1 ++ Set(5, 6, 7)
val set0 = Set(1,3,4) ++ set1
println(set0.getClass)
}
package cn.itcast.collect
import scala.collection.mutable
object MutSetDemo extends App{
//创建一个可变的HashSet
val set1 = new mutable.HashSet[Int]()
//向HashSet中添加元素
set1 += 2
//add等价于+=
set1.add(4)
set1 ++= Set(1,3,5)
println(set1)
//删除一个元素
set1 -= 5
set1.remove(2)
println(set1)
}
通过 +=新增元素(-=减去元素)
通过max min查找最大值 最小值
通过.& .intersect查找交集
更多参阅API
Map:
package cn.itcast.collect
import scala.collection.mutable
object MutMapDemo extends App{
val map1 = new mutable.HashMap[String, Int]()
//向map中添加数据
map1("spark") = 1
map1 += (("hadoop", 2))
map1.put("storm", 3)
println(map1)
//从map中移除元素
map1 -= "spark"
map1.remove("hadoop")
println(map1)
}
都是通过+=进行元素的新增
更多集合相关操作,参考:http://www.runoob.com/scala/scala-collections.html
5.WordCount示例练习
使用上面的知识编写WC代码,先导复习知识:https://blog.csdn.net/springlustre/article/details/52882205
def main(args: Array[String]): Unit = {
// 定义单词列表
val words = List("i love china", "i am alone")
// map方法中_有神奇的效果,其中的flatten压平方法,将map中切割产生的2个数组进行压平
// words.map(_.split(" ")).flatten
// 使用IDEA的建议,通过flatMap一步到位
val allWords = words.flatMap(_.split(" "))
println(allWords)
// 将元素和1进行绑定成为map
val wordsAndOne = allWords.map((_, 1))
println(wordsAndOne)
// 进行分组操作(返回一个映射),注意上一步得到是一个元组的集合,对元组访问采用_的形式
val groupWords = wordsAndOne.groupBy(_._1)
println(groupWords)
// 进行最后的统计操作,注意对元素进行map操作时拿到的每个元素是元组,对于上一步的映射结果,每一个元组含2个元素
// 使用匿名函数,返回新元组,这里不能使用_._1,_._2了,多个参数不能同时用_
val res = groupWords.map(x => (x._1, x._2.size))
println(res)
// 排序,只有List有,所以必须先转换
val res_sort = res.toList.sortBy(_._2).reverse
println(res_sort)
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号