大数据入门第十二天——azkaban入门
一、概述
1.azkaban是什么
通过官方文档:https://azkaban.github.io/
Azkaban is a batch workflow job scheduler created at LinkedIn to run Hadoop jobs. Azkaban resolves the ordering through job dependencies and provides an easy to use web user interface to maintain and track your workflows.
中文翻译:
Azkaban是在LinkedIn上创建的批处理工作流作业调度程序,用于运行Hadoop作业。Azkaban通过作业依赖性解决了排序问题,并提供易于使用的Web用户界面来维护和跟踪您的工作流程。
2.为什么需要工作流调度系统
l 一个完整的数据分析系统通常都是由大量任务单元组成:
shell脚本程序,java程序,mapreduce程序、hive脚本等
l 各任务单元之间存在时间先后及前后依赖关系
l 为了很好地组织起这样的复杂执行计划,需要一个工作流调度系统来调度执行;
3.实现方式
简单的任务调度:直接使用linux的crontab来定义;
复杂的任务调度:开发调度平台
或使用现成的开源调度系统,比如ooize、azkaban等


对市面上最流行的两种调度器,给出以下详细对比,以供技术选型参考。总体来说,ooize相比azkaban是一个重量级的任务调度系统,功能全面,但配置使用也更复杂。如果可以不在意某些功能的缺失,轻量级调度器azkaban是很不错的候选对象。 详情如下: 功能 两者均可以调度mapreduce,pig,java,脚本工作流任务 两者均可以定时执行工作流任务 工作流定义 Azkaban使用Properties文件定义工作流 Oozie使用XML文件定义工作流 工作流传参 Azkaban支持直接传参,例如${input} Oozie支持参数和EL表达式,例如${fs:dirSize(myInputDir)} 定时执行 Azkaban的定时执行任务是基于时间的 Oozie的定时执行任务基于时间和输入数据 资源管理 Azkaban有较严格的权限控制,如用户对工作流进行读/写/执行等操作 Oozie暂无严格的权限控制 工作流执行 Azkaban有两种运行模式,分别是solo server mode(executor server和web server部署在同一台节点)和multi server mode(executor server和web server可以部署在不同节点) Oozie作为工作流服务器运行,支持多用户和多工作流 工作流管理 Azkaban支持浏览器以及ajax方式操作工作流 Oozie支持命令行、HTTP REST、Java API、浏览器操作工作流
oozie暂不展开
二、安装与配置
1.准备
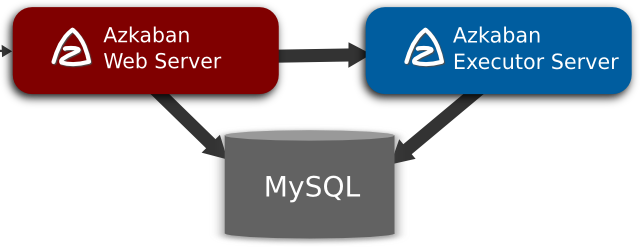
目前azkaban只支持 mysql,需安装mysql服务器,并且需要特定的表结构进行存储(这里不像hive会自动创建,需要手动运行SQL脚本)
Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
以上的文件是通过自己用gradle构建而来,具体参考:这里
2.安装
在家目录(与apps/同级)下建立专门的文件夹
[hadoop@mini1 ~]$ mkdir azkaban
解压
[hadoop@mini1 ~]$ tar -zxvf azkaban-web-server-2.5.0.tar.gz -C azkaban
[hadoop@mini1 ~]$ tar -zxvf azkaban-executor-server-2.5.0.tar.gz -C azkaban
[hadoop@mini1 ~]$ tar -zxvf azkaban-sql-script-2.5.0.tar.gz -C azkaban
重命名(方便管理,可自定义)
[hadoop@mini1 azkaban]$ mv azkaban-web-2.5.0/ server
[hadoop@mini1 azkaban]$ mv azkaban-executor-2.5.0/ executor
导入Mysql脚本
[hadoop@mini1 azkaban]$ mysql -uroot -pZcc170821#
mysql> create database azkaban;
Query OK, 1 row affected (0.01 sec)
mysql> use azkaban;
Database changed
mysql> source /home/hadoop/azkaban/azkaban-2.5.0/create-all-sql-2.5.0.sql;
配置SSL(azkaban需要https访问)
参考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,输入的密码请劳记,信息如下:
输入keystore密码: 123456(纯粹为了方便记忆这里)
再次输入新密码:
# 以下可以不填(直接enter),这样就是Unknown,当然也可以自定义填入
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入<jetty>的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore
考贝到 azkaban web服务器根目录中.如:cp keystore server/
统一时区
拷贝该时区文件,覆盖系统本地时区配置(最好3台机器都统一)
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
//如果文件不存在,通过tzselect 命令生成即可
如果用ntp做时间同步,参考:https://www.cnblogs.com/zwingblog/p/6110588.html
简单的时间同步:
sudo date -s '2018-02-26 19:41:58'
hwclock -w
web服务器配置
进入web服务器目录,修改conf/azkaban.properties,下面红色的即为本次需要调整的,按需调整!
#Azkaban Personalization Settings
azkaban.name=Test #服务器UI名称,用于服务器上方显示的名字
azkaban.label=My Local Azkaban #描述
azkaban.color=#FF3601 #UI颜色
azkaban.default.servlet.path=/index #
web.resource.dir=web/ #默认根web目录
default.timezone.id=Asia/Shanghai #默认时区,已改为亚洲/上海 默认为美国
#Azkaban UserManager class
user.manager.class=azkaban.user.XmlUserManager #用户权限管理默认类
user.manager.xml.file=conf/azkaban-users.xml #用户配置,具体配置参加下文
#Loader for projects
executor.global.properties=conf/global.properties # global配置文件所在位置
azkaban.project.dir=projects #
database.type=mysql #数据库类型
mysql.port=3306 #端口号
mysql.host=hadoop03 #数据库连接IP
mysql.database=azkaban #数据库实例名
mysql.user=root #数据库用户名
mysql.password=root #数据库密码
mysql.numconnections=100 #最大连接数
# Velocity dev mode
velocity.dev.mode=false
# Jetty服务器属性.
jetty.maxThreads=25 #最大线程数
jetty.ssl.port=8443 #Jetty SSL端口
jetty.port=8081 #Jetty端口
jetty.keystore=keystore #SSL文件名
jetty.password=123456 #SSL文件密码
jetty.keypassword=123456 #Jetty主密码 与 keystore文件相同
jetty.truststore=keystore #SSL文件名
jetty.trustpassword=123456 # SSL文件密码
# 执行服务器属性
executor.port=12321 #执行服务器端口
# 邮件设置
mail.sender=xxxxxxxx@163.com #发送邮箱
mail.host=smtp.163.com #发送邮箱smtp地址
mail.user=xxxxxxxx #发送邮件时显示的名称
mail.password=********** #邮箱密码
job.failure.email=xxxxxxxx@163.com #任务失败时发送邮件的地址
job.success.email=xxxxxxxx@163.com #任务成功时发送邮件的地址
lockdown.create.projects=false #
cache.directory=cache #缓存目录
再修改azkaban-users.xml,配置web页面的用户
<azkaban-users>
<user username="azkaban" password="azkaban" roles="admin" groups="azkaban" />
<user username="metrics" password="metrics" roles="metrics"/>
<user username="admin" password="admin" roles="admin,metrics" />
<role name="admin" permissions="ADMIN" />
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
executor执行服务器配置
进入执行服务器安装目录conf,修改azkaban.properties
#Azkaban
default.timezone.id=Asia/Shanghai #时区
# Azkaban JobTypes 插件配置
azkaban.jobtype.plugin.dir=plugins/jobtypes #jobtype 插件所在位置
#Loader for projects
executor.global.properties=conf/global.properties
azkaban.project.dir=projects
#数据库设置
database.type=mysql #数据库类型(目前只支持mysql)
mysql.port=3306 #数据库端口号
mysql.host=192.168.20.200 #数据库IP地址
mysql.database=azkaban #数据库实例名
mysql.user=azkaban #数据库用户名
mysql.password=oracle #数据库密码
mysql.numconnections=100 #最大连接数
# 执行服务器配置
executor.maxThreads=50 #最大线程数
executor.port=12321 #端口号(如修改,请与web服务中一致)
executor.flow.threads=30 #线程数
3.启动
都需要在根目录启动:
web服务器
bin/azkaban-web-start.sh
//启动后敲一个回车也是可以自动到后台
启动到后台:
nohub bin/azkaban-web-start.sh 1>/tmp/az.out 2>/tmp/azerr.out &
执行服务器
bin/azkaban-executor-start.sh
访问:
https://服务器IP地址:8443
//输入上面配置的web用户即可!
4.停止
[hadoop@mini1 executor]$ bin/azkaban-executor-shutdown.sh
[hadoop@mini1 server]$ bin/azkaban-web-shutdown.sh
三、azkaban实战
Azkaba内置的任务类型支持command、java
1、command类型单一job
1、创建job描述文件
vi command.job
如果报错配置文件不合法,需要修改为UTF-8格式!
#command.job
type=command
command=echo 'hello'
2、将job资源文件打包成zip文件
zip command.zip command.job
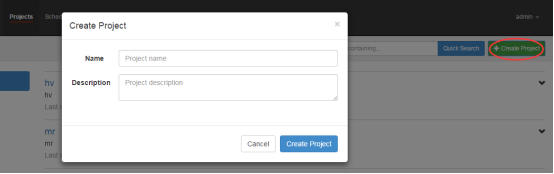
3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
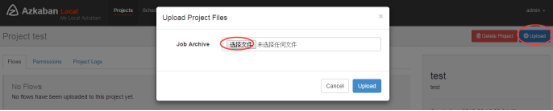
上传zip包
4.启动job

立刻执行:

定时调度:
5.执行结果

由于是通过shell去执行的,所以在我们的shell的窗口是看不到的,但是可以在details里面看到!
2.多job类型command
创建多个有依赖关系的Job描述
foo.job
# foo.job
type=command
command=echo foo
bar.job
# bar.job
type=command
dependencies=foo
command=echo bar
将多个Job打成一个zip包
foobar.zip
上传zip包
同上文上传,新建工程上传即可
启动工作流
3.HDFS操作任务
由于要执行hadoop命令,应该先找出hadoop命令的位置:(hadoop程序请先开启)
[hadoop@mini1 ~]$ which hadoop
~/apps/hadoop-2.6.4/bin/hadoop
创建Job描述文件
# fs.job
type=command
command=/home/hadoop/apps/hadoop-2.6.4/bin/hadoop fs -mkdir /azaz
添加到压缩包
fs.zip
新建项目,上传zip
启动Job
4.跑MapReduce程序
创建Job描述文件
和上面一样,先找出Hadoop命令的绝对路径
# mrwc.job type=command command=/home/hadoop/apps/hadoop-2.6.4/bin/hadoop jar hadoop-mapreduce-examples-2.6.1.jar wordcount /wordcount/input /wordcount/azout
// 如果没有相关的input目录与要统计的文件,请提前建立目录hadoop fs -mkidr -p /xxx
将mrwc的job文件与相应的Jar打包

新建project,上传zip包
启动job
5.hive脚本任务
1.创建job描述文件与hive脚本
hive脚本:test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
// 如果缺少相关的目录与数据,请先在HDFS上创建-mkdir -p / -put等
[hadoop@mini1 ~]$ hadoop fs -mkdir -p /aztest/hiveinput
[hadoop@mini1 ~]$ hadoop fs -put user2.dat /aztest/hiveinput
job描述文件:hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/hive-1.2.1/bin/hive -f 'test.sql'
// 同样,先通过which hive定位
2.将所有资源文件:test.sql和hivef.job打成zip
3.新建工程,上传zip
4.执行Job

 浙公网安备 33010602011771号
浙公网安备 33010602011771号