大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一、mapTask并行度的决定机制
1.概述
一个job的map阶段并行度由客户端在提交job时决定
而客户端对map阶段并行度的规划的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split,然后每一个split分配一个mapTask并行实例处理
这段逻辑及形成的切片规划描述文件,由FileInputFormat实现类的getSplits()方法完成,其过程如下图:
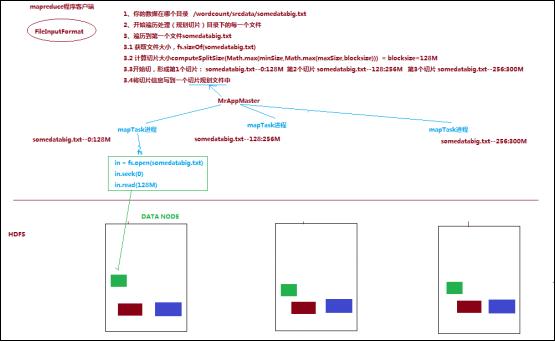
// 完整的笔记介绍,参考:http://blog.csdn.net/qq_26442553/article/details/78774061
2.FileInputFormat切片机制
结论:
a) 简单地按照文件的内容长度进行切片
b) 切片大小,默认等于block大小
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
参数:
通过源码分析,我们跟进FileInputFormat的getSplit()方法,


/** * Generate the list of files and make them into FileSplits. * @param job the job context * @throws IOException */ public List<InputSplit> getSplits(JobContext job) throws IOException { Stopwatch sw = new Stopwatch().start(); long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); long maxSize = getMaxSplitSize(job); // generate splits List<InputSplit> splits = new ArrayList<InputSplit>(); List<FileStatus> files = listStatus(job); for (FileStatus file: files) { Path path = file.getPath(); long length = file.getLen(); if (length != 0) { BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length); } if (isSplitable(job, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(blockSize, minSize, maxSize); long bytesRemaining = length; while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { // not splitable splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.elapsedMillis()); } return splits; }
可以看到切片参数配置:
Math.max(minSize, Math.min(maxSize, blockSize));
参数:可以通过客户端的conf.set方法进行设置!
minsize:默认值:1
配置参数: mapreduce.input.fileinputformat.split.minsize
maxsize:默认值:Long.MAXValue
配置参数:mapreduce.input.fileinputformat.split.maxsize blocksize
另外一个参数blocksize可以通过hdfs-site.xml的dfs.blocksize查看配置,这里2.6.4版本的默认大小是128M(可以在官网或者下载包的doc里看到!)
实际上,在源码中有一个细节:
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP)
这表明,例如当文件为260M时,切完一次后,还剩132,由于132/128<1.1,故不会再切片了,不会把剩下的4M单独切一片!
相关的切片机制,可以参考相关博文:http://blog.csdn.net/m0_37746890/article/details/78834603
http://blog.csdn.net/Dr_Guo/article/details/51150278
这样,整个客户端提交job的流程梳理如下: 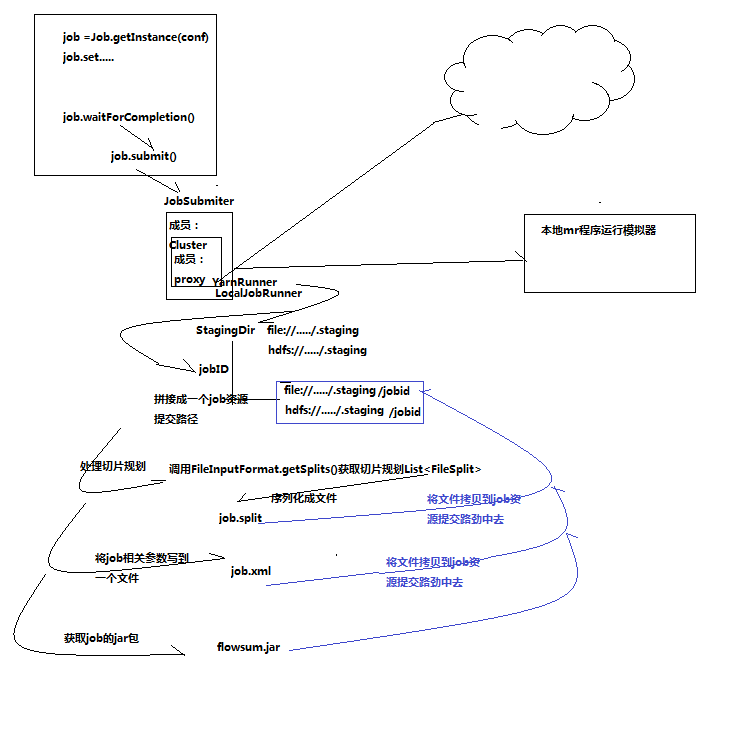
小文件的处理,可以在Driver中设置切片的类:
//如果不设置InputFormat,它默认用的是TextInputformat.class
job.setInputFormatClass(CombineTextInputFormat.class);
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);
这只是简单用法,更多分析与实践,参考网友博客:https://www.iteblog.com/archives/2139.html
二、自定义partition编程
编码之前,参考原理讲解:http://blog.csdn.net/gamer_gyt/article/details/47339755
1.需求
根据归属地输出流量统计数据结果到不同文件,以便于在查询统计结果时可以定位到省级范围进行(上篇示例2拓展)
2.引入分区
Mapreduce中会将map输出的kv对,按照相同key分组,然后分发给不同的reducetask
默认的分发规则为:根据key的hashcode%reducetask数来分发
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
可以看到,之前分3个mapTask的时候,默认是按照上文的逻辑分区!
所以:如果要按照我们自己的需求进行分组,则需要改写数据分发(分组)组件Partitioner
自定义一个CustomPartitioner继承抽象类:Partitioner
然后在job对象中,设置自定义partitioner: job.setPartitionerClass(CustomPartitioner.class)
3.自定义分区
主要的步骤是:
建立自定义分区类:(建议从0号分区开始...)
package com.mr.flowsum; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; import java.util.HashMap; import java.util.Map; /** * 自定义分区 * 泛型对应Map的输出类型 * * @author zcc ON 2018/2/1 **/ public class ProvincePartitioner extends Partitioner<Text, FlowBean> { /** * 存储省份字典表,加载在内存中方便快速读取 */ private static Map<String, Integer> provinceMap = new HashMap<>(); static { provinceMap.put("136", 1); provinceMap.put("137", 2); provinceMap.put("138", 3); provinceMap.put("138", 4); } @Override public int getPartition(Text text, FlowBean flowBean, int numPartitions) { // 应该有个归属地字典进行匹配(这里使用HashMap模拟) String prefix = text.toString().substring(0, 3); Integer provinceID = provinceMap.get(prefix); return provinceID == null ? 4 : provinceID; } }
修改Driver分区器和reduceTask数量
package com.mr.flowsum; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 主类,用于加载配置 * * @author zcc ON 2018/1/31 **/ public class FlowCountDriver { public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置本程序jar包本地位置 job.setJarByClass(FlowCountDriver.class); // 指定本业务job要使用的mapper/reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 指定map输出的数据类型(由于可插拔的序列化机制导致) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 设置自定义分区器 job.setPartitionerClass(ProvincePartitioner.class); // 设置相应分区数量的reduceTask job.setNumReduceTasks(5); // 指定最终输出(reduce)的的数据类型(可选,因为有时候不需要reduce) job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 指定job的原始输入/输出目录(可以改为由外面输入,而不必写死) FileInputFormat.setInputPaths(job, new Path("/flowcount/input")); FileOutputFormat.setOutputPath(job, new Path("/flowcount/output")); // 提交(将job中的相关参数以及java类所在的jar包提交给yarn运行) // job.submit(); // 反馈集群信息 boolean b = job.waitForCompletion(true); System.exit(b ? 0 :1); } }
其他不变(与流量统计类同)
package com.mr.flowsum; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 这里选择实现Writable接口则不必实现排序的逻辑,后续有相关需求时可以考虑 * @author zcc ON 2018/1/31 **/ public class FlowBean implements Writable{ private long upFlow; private long downFlow; private long sumFlow; /** * 反序列化时需要显式调用空参 */ public FlowBean() { } public FlowBean(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /** * 序列化 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } /** * 反序列化,注意序列化与反序列化的顺序必须一致! * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } @Override public String toString() { return "FlowBean{" + "upFlow=" + upFlow + ", downFlow=" + downFlow + ", sumFlow=" + sumFlow + '}'; } }
package com.mr.flowsum; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * mapper * * @author zcc ON 2018/1/31 **/ public class FlowCountMapper extends Mapper<LongWritable,Text,Text,FlowBean>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); // 按制表符切分每行数据,可以进一步做筛选过滤等处理 String[] fields = line.split("\t"); // 取出手机号 String phoneNum = fields[1]; // 上下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]); // 写入上下文 context.write(new Text(phoneNum), new FlowBean(upFlow, downFlow)); } }
package com.mr.flowsum; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * reducer * * @author zcc ON 2018/1/31 **/ public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean>{ @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sum_upFlow = 0; long sum_downFlow = 0; // 遍历所有bean,累加所有上下行流量 for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); } FlowBean result = new FlowBean(sum_upFlow, sum_downFlow); // 将结果以<手机号(传递来的参数),包装的结果bean>的形式写出(底层是写出到文本文件,需要用到toString()方法) context.write(key, result); } }
内容小结:
1、mapreduce框架的设计思想
2、mapreduce框架中的程序实体角色:maptask reducetask mrappmaster
3、mapreduce程序运行的整体流程
4、mapreduce程序中maptask任务切片规划的机制(掌握整体逻辑流程,看day03_word文档中的“maptask并行度”)
5、mapreduce程序提交的整体流程(看图:"客户端提交mr程序job的流程")
6、编码:
wordcount
流量汇总统计(hadoop的序列化实现)
流量汇总统计并按省份区分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号