大数据入门第七天——MapReduce详解(一)入门与简单示例
一、概述
1.map-reduce是什么


Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner. A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks. Typically the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster. The MapReduce framework consists of a single master ResourceManager, one worker NodeManager per cluster-node, and MRAppMaster per application (see YARN Architecture Guide). Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes. These, and other job parameters, comprise the job configuration. The Hadoop job client then submits the job (jar/executable etc.) and configuration to the ResourceManager which then assumes the responsibility of distributing the software/configuration to the workers, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client. Although the Hadoop framework is implemented in Java™, MapReduce applications need not be written in Java. Hadoop Streaming is a utility which allows users to create and run jobs with any executables (e.g. shell utilities) as the mapper and/or the reducer. Hadoop Pipes is a SWIG-compatible C++ API to implement MapReduce applications (non JNI™ based).
中文翻译:
概观
Hadoop MapReduce是一个用于轻松编写应用程序的软件框架,它以可靠的容错方式在大型群集(数千个节点)的商品硬件上并行处理海量数据(多TB数据集)。
MapReduce 作业通常将输入数据集分割为独立的块,由地图任务以完全平行的方式进行处理。框架对映射的输出进行排序,然后输入到reduce任务。通常,作业的输入和输出都存储在文件系统中。该框架负责调度任务,监视它们并重新执行失败的任务。
通常,计算节点和存储节点是相同的,即MapReduce框架和Hadoop分布式文件系统(请参阅HDFS体系结构指南)在同一组节点上运行。此配置允许框架在数据已经存在的节点上有效地调度任务,从而在整个群集中带来非常高的聚合带宽。
MapReduce框架由单个主资源管理器,每个集群节点的一个工作者NodeManager和每个应用程序的MRAppMaster组成(参见YARN体系结构指南)。
最小程度上,应用程序通过实现适当的接口和/或抽象类来指定输入/输出位置并提供映射和减少函数。这些和其他作业参数组成作业配置。
然后,Hadoop 作业客户端将作业(jar /可执行文件等)和配置提交给ResourceManager,然后负责将软件/配置分发给工作人员,安排任务并对其进行监控,向作业提供状态和诊断信息客户。
虽然Hadoop框架是用Java™实现的,但MapReduce应用程序不需要用Java编写。
Hadoop Streaming是一个实用程序,它允许用户使用任何可执行文件(例如shell实用程序)作为映射器和/或reducer来创建和运行作业。
Hadoop Pipes是SWIG兼容的C ++ API来实现MapReduce应用程序(基于非JNI™)。
mapreduce自身的角色是作为HDFS的一个客户端!
用网友的小结来说:
MapReduce的处理过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自行指定。map阶段对切分好的数据进行并行处理,处理结果传输给reduce,由reduce函数完成最后的汇总。
2.为什么会有mapreduce
(1)海量数据在单机上处理因为硬件资源限制,无法胜任 (2)而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度 (3)引入mapreduce框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
wordcount的场景案例:
单机版:内存受限,磁盘受限,运算能力受限
分布式:
1、文件分布式存储(HDFS)
2、运算逻辑需要至少分成2个阶段(一个阶段独立并发,一个阶段汇聚)
3、运算程序如何分发
4、程序如何分配运算任务(切片)
5、两阶段的程序如何启动?如何协调?
整个程序运行过程中的监控?容错?重试?
3.mapreduce角色与架构
最朴素的说,分为3个角色:
1、MRAppMaster(mapreduce application master)
2、MapTask
3、ReduceTask
详细介绍,参考:https://www.cnblogs.com/gw811/p/4077315.html
4.流程浅析
1、一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程 2、maptask进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为: a)利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对 b)将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存 c)将缓存中的KV对按照K分区排序后不断溢写到磁盘文件 3、MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据范围(数据分区) 4、Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,
并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储
5.数据类型
MR的数据类型以及自定义数据类型,参考:https://www.cnblogs.com/cenzhongman/p/7133904.html
当然,既然已经有一些默认的实现类型了,我们要自定义类型也可以打开例如LongWritable的进行源码查看!自定义类型的实例,参考下文流量统计
实例处相关Bean的写法!
二、起步:wordcount实例
1.引入依赖
依赖在share目录下确实都有,这里采用maven进行构建,参考博文:https://www.cnblogs.com/Leo_wl/p/4862820.html
<!-- hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.4</version>
</dependency>
<!-- hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.4</version>
<scope>provided</scope>
</dependency>
<!-- hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.4</version>
</dependency>
<!-- hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.4</version>
</dependency>
<!-- hadoop-mapreduce-client-jobclient -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.4</version>
<scope>provided</scope>
</dependency>
<!-- hadoop-mapreduce-client-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.6.4</version>
</dependency>
关于为什么会有provided范围的jar,请先复习maven的scope,再参考:https://book.2cto.com/201511/58367.html
2.编程规范
(1)用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(4)Mapper中的业务逻辑写在map()方法中
(5)map()方法(maptask进程)对每一个<K,V>调用一次
(6)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(7)Reducer的业务逻辑写在reduce()方法中
(8)Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
(9)用户自定义的Mapper和Reducer都要继承各自的父类
(10)整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
3.代码
简单的基本数据类型(Writable接口的实现类)等参见代码中注释
Map中的输入KEYIN代表的是偏移量,例如第一次执行时,偏移量是0,执行完一次(以行分割),到达第二行,此时偏移量就是第一行的字符数量
例如第一行有13个,则偏移量到了14处(13字符加一个回车)
代码中输入输出参数的详解,参考:http://www.aboutyun.com/thread-7557-1-1.html
package com.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * mapper * Mapper的四个泛型: * KEYIN:输入key类型,默认情况下,是mr框架所读到一行文本的偏移量,Long。 * 在hadoop中有自己的精简化序列化接口,LongWritable来代替Long * VALUEIN:输入VALUE类型,默认情况下,是mr框架读到一行文本的值,String * 同上,为了序列化的精简,使用Text,下同 * KEYOUT:用户自定义逻辑处理完成后输出的key类型,在统计单词案例中,是String * VALUEOUT:输出数据中的VALUE,在此处是单词数量,Integer。同上,使用IntWritable * 所有常用类型如下: * ByteWritable:单字节数值 IntWritable:整型数 LongWritable:长整型数 FloatWritable:浮点数 DoubleWritable:双字节数值 BooleanWritable:标准布尔型数值 Text:使用UTF8格式存储的文本 NullWritable:当<key,value>中的key或value为空时使用 * @author zcc ON 2018/1/31 **/ public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> { /** * map阶段的逻辑就在map()方法中,每行数据调用一次map()方法 * @param key 起始偏移量 * @param value 此处是单词的内容 * @param context 上下文 * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 转换为易操作的string String line = value.toString(); // 切割单词 String[] words = line.split(" "); // 将单词输出为键值对<word,1> for (String word : words) { // 将单词作为key,value作为1便于分发,这样相同单词到相同reduce,(注意泛型限定了输出的类型) context.write(new Text(word), new IntWritable(1)); } } }
package com.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; /** * reducer * KEYIN/VALUEIN对应mapper的KEYOUT/VALUEOUT * KEYOUT/VALUEOUT是自定义逻辑输出类型,这里KEYOUT是单词,VALUEOUT是总次数 * @author zcc ON 2018/1/31 **/ public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ /** * * @param key 一组相同单词KV对的key * 例如map阶段存在<hello,1><hello,1><hello,1><hello,1> * <world,1><world,1><world,1><world,1> * 那么传过来的第一组键值对的key,就是第一个hello * @param values * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; // 可以使用迭代器,结合while,或者直接使用封装的for循环 // Iterator<IntWritable> iterator = values.iterator(); for (IntWritable value : values) { count += value.get(); } // 默认写到HDFS文件中去,每一个单词的统计都调用一次,写一次文件 context.write(key,new IntWritable(count)); } }
package com.mr.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * wordcount的任务配置类 * 相当于yarn集群的客户端,在此封装MR配置参数 * @author zcc ON 2018/1/31 **/ public class WordCountDriver { public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置本程序jar包本地位置 job.setJarByClass(WordCountDriver.class); // 指定本业务job要使用的mapper/reducer业务类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 指定map输出的数据类型(由于可插拔的序列化机制导致) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 指定最终输出(reduce)的的数据类型(可选,因为有时候不需要reduce) job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 指定job的原始输入/输出目录(可以改为由外面输入,而不必写死) FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); // 提交(将job中的相关参数以及java类所在的jar包提交给yarn运行) // job.submit(); // 反馈集群信息 boolean b = job.waitForCompletion(true); System.exit(b ? 0 :1); } }
运行:
将项目打成jar包(详细操作方法参考maven补充拓展篇)
如果不使用maven的打包功能,也可以自己打包:https://www.cnblogs.com/blog5277/p/5920560.html
在程序Driver的main()方法中,也可以通过setJar()来指定jar的位置,,而不使用class
先使用-put上传一些测试数据(这里上传几个hadoop里面的README.txt,NOTECE.txt等测试文件)到新建的目录/wordcount/input(/wordcount/output无需创建,会自动创建)
hadoop jar zk01.jar com.mr.wordcount.WordCountDriver
如果main方法需要参数,直接在后面以空格分隔给出参数即可!(这些基础命令请参考基础随笔)

// 注意这里不能使用
java -cp zk01.jar com.mr.wordcount.WordCountDriver
来运行,这样会缺少hadoop的jar依赖等,使用hadoop jar则会自动帮我们设置一些环境变量!
4.小结
运行完成功以后,可以再次回顾一下第2点编程规范
对于一个MR任务,它的输入、输出以及中间结果都是<key, value>键值对:
- Map:
<k1, v1>——>list(<k2, v2>) - Reduce:
<k2, list(v2)>——>list(<k3, v3>)
详细wordcount流程如下:
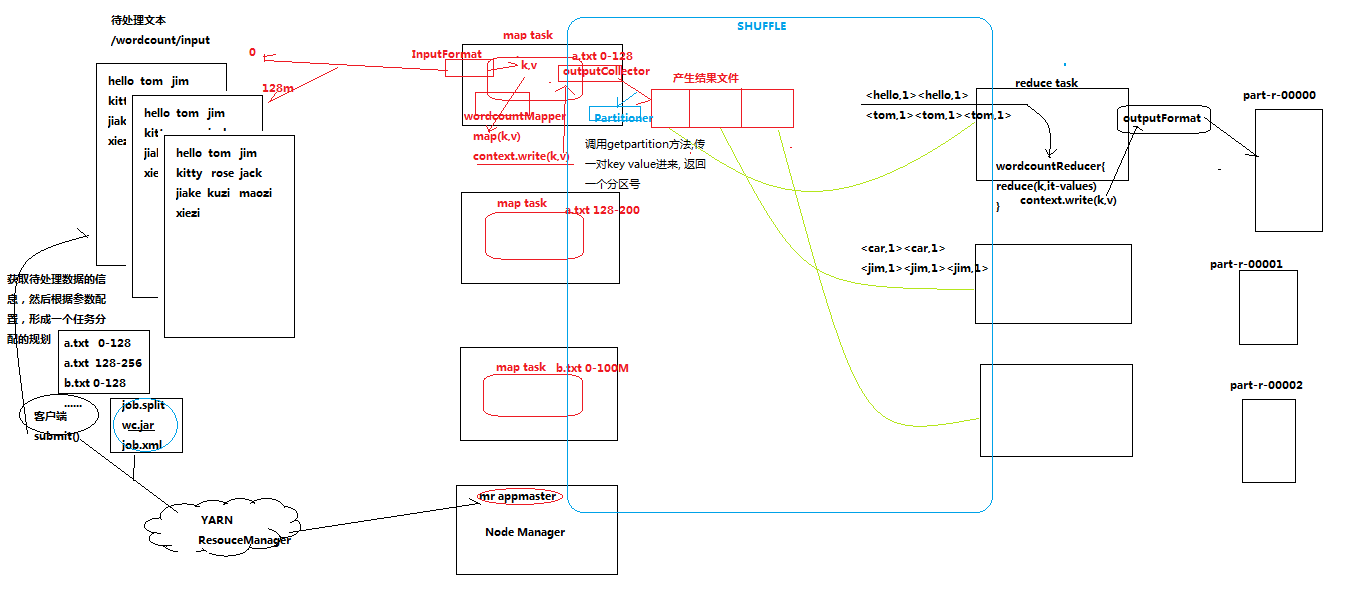 中间会有更多细节,后文补充!
中间会有更多细节,后文补充!
简单的wordcount的流程,我们可以参考这里:http://blog.csdn.net/bingduanlbd/article/details/51924398
三、流量汇总示例
需求:
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200 1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200 1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200 1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200 1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200 1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200 1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200 1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200 1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200 1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200 1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash2-http.qq.com 综合门户 15 12 1938 2910 200 1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200 1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200 1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200 1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200 1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200 1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 作业:1/统计每一个用户(手机号)所耗费的总上行流量、下行流量,总流量 map 读一行,切分字段 抽取手机号,上行流量 下行流量 context.write(手机号,bean) reduce 2/得出上题结果的基础之上再加一个需求:将统计结果按照总流量倒序排序
// 实质也是与wordcount类似的
1.代码
package com.mr.flowsum; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; /** * 这里选择实现Writable接口则不必实现排序的逻辑,后续有相关需求时可以考虑 * @author zcc ON 2018/1/31 **/ public class FlowBean implements Writable{ private long upFlow; private long downFlow; private long sumFlow; /** * 反序列化时需要显式调用空参 */ public FlowBean() { } public FlowBean(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /** * 序列化 * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } /** * 反序列化,注意序列化与反序列化的顺序必须一致! * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } @Override public String toString() { return "FlowBean{" + "upFlow=" + upFlow + ", downFlow=" + downFlow + ", sumFlow=" + sumFlow + '}'; } }
package com.mr.flowsum; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * mapper * * @author zcc ON 2018/1/31 **/ public class FlowCountMapper extends Mapper<LongWritable,Text,Text,FlowBean>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); // 按制表符切分每行数据,可以进一步做筛选过滤等处理 String[] fields = line.split("\t"); // 取出手机号 String phoneNum = fields[1]; // 上下行流量 long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]); // 写入上下文 context.write(new Text(phoneNum), new FlowBean(upFlow, downFlow)); } }
package com.mr.flowsum; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * reducer * * @author zcc ON 2018/1/31 **/ public class FlowCountReducer extends Reducer<Text,FlowBean,Text,FlowBean>{ @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException { long sum_upFlow = 0; long sum_downFlow = 0; // 遍历所有bean,累加所有上下行流量 for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); } FlowBean result = new FlowBean(sum_upFlow, sum_downFlow); // 将结果以<手机号(传递来的参数),包装的结果bean>的形式写出(底层是写出到文本文件,需要用到toString()方法) context.write(key, result); } }
package com.mr.flowsum; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 主类,用于加载配置 * * @author zcc ON 2018/1/31 **/ public class FlowCountDriver { public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置本程序jar包本地位置 job.setJarByClass(FlowCountDriver.class); // 指定本业务job要使用的mapper/reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 指定map输出的数据类型(由于可插拔的序列化机制导致) job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 指定最终输出(reduce)的的数据类型(可选,因为有时候不需要reduce) job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 指定job的原始输入/输出目录(可以改为由外面输入,而不必写死) FileInputFormat.setInputPaths(job, new Path("/flowcount/input")); FileOutputFormat.setOutputPath(job, new Path("/flowcount/output")); // 提交(将job中的相关参数以及java类所在的jar包提交给yarn运行) // job.submit(); // 反馈集群信息 boolean b = job.waitForCompletion(true); System.exit(b ? 0 :1); } }
运行的方法与wordcount示例类似,上传文件,使用hadoop jar运行即可!
结果:
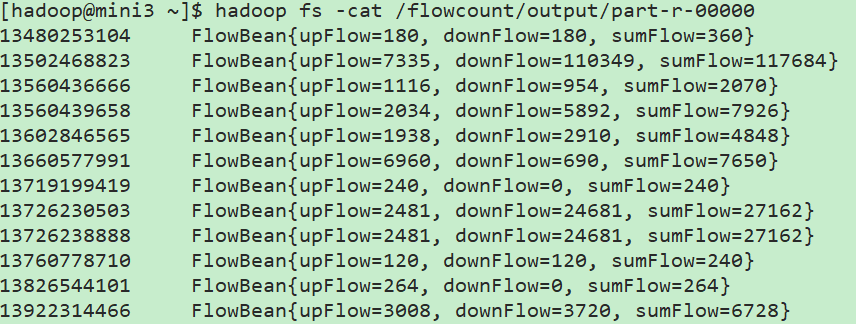
// 至于何时调用toString(),中间shuffer等过程,后文解析!
【更新】:
在FlowReducer中,调用reduce()方法时每次都进行了new的操作,这样数据量大的话是不可行的,应该改为只new一次,后面修改属性值即可!
当然,必须考虑以下问题:
List<Bean> list = new ArrayList<>();
Bean bean = new Bean();
bean.setAge(18);
list.add(bean);
bean.setAge(19);
list.add(bean);
bean.setAge(20);
list.add(bean);
以上代码执行后,list中的size是3;但是3个bean的age都为20!原因是List中存的是对象的引用!最后一次修改内容之后,前两个引用指向的是修改后的内容!
不过在mapreduce这里由于是write()是通过序列化写出去的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号