大数据入门第二天——基础部分之zookeeper(上)
一、概述
1.是什么?
根据凡技术必登其官网的原则,我们先去官网瞅一瞅:http://zookeeper.apache.org/
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
形象的说:
作者:张鹏飞
链接:https://www.zhihu.com/question/20004877/answer/112124929
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Zookeeper是一个分布式协调服务;就是为用户的分布式应用程序提供协调服务
A、zookeeper是为别的分布式程序服务的
B、Zookeeper本身就是一个分布式程序(只要有半数以上节点存活,zk就能正常服务)
C、Zookeeper所提供的服务涵盖:主从协调、服务器节点动态上下线、统一配置管理、分布式共享锁、统一名称服务……
D、虽然说可以提供各种服务,但是zookeeper在底层其实只提供了两个功能:
管理(存储,读取)用户程序提交的数据;
并为用户程序提供数据节点监听服务;
更多的深入浅出的介绍,参考:https://www.cnblogs.com/wuxl360/p/5817471.html
zookeeper的W3C教程,参考:https://www.w3cschool.cn/zookeeper/zookeeper_overview.html
选举重点清晰讲解,参考:http://blog.csdn.net/gaoshan12345678910/article/details/67638657
2.集群中的角色
Zookeeper集群的角色: Leader 和 follower (Observer)
只要集群中有半数以上节点存活,集群就能提供服务
二、安装
以下请使用hadoop用户!并配置hosts安装为好!
###zk有相关的可视化工具,详情参考IDEA插件章节篇
通过克隆复制好3台机器后,使用rz命令先上传文件
(安装前提需要有JDK)
解压:
tar -zxvf zookeeper-3.4.5.tar.gz -C /opt/zookeeper
配置环境变量:
sudo vi /etc/profile
export ZOOKEEPER_HOME=/opt/zookeeper/zookeeper-3.4.5
export PATH=$PATH:$ZOOKEEPER_HOME/bin
生效环境变量:
source /etc/profile
以上配环境步骤3台机器均需要更改!
修改配置文件:
cd zookeeper-3.4.5/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
增加以下内容:
dataDir=/opt/zookeeper/zookeeper-3.4.5/data
dataLogDir=/opt/zookeeper/zookeeper-3.4.5/log
#主机名:心跳端口:数据端口
server.1=192.168.137.128:2888:3888
server.2=192.168.137.138:2888:3888
server.3=192.168.137.148:2888:3888
创建文件夹:
cd /opt/zookeeper/zookeeper-3.4.5
mkdir -m 755 data
mkdir -m 755 log
创建myid:
cd data
vim myid
myid内容:
1
下发集群到其他机器上:
scp -r /opt/zookeeper/zookeeper-3.4.5 root@192.168.137.138:/opt/zookeeper/
scp -r /opt/zookeeper/zookeeper-3.4.5 root@192.168.137.148:/opt/zookeeper/
其实应当使用hadoop用户,并配置hosts,换成如下命令:
scp -r zookeeper-3.4.5/ mini2:/home/hadoop/apps/
到两台机器上分别修改myid为2 3
启动机器:
zkServer.sh start
查看状态:
zkServer.sh status
出现报错请关闭防火墙重试!
三、命令行客户端的使用
1.命令行客户端

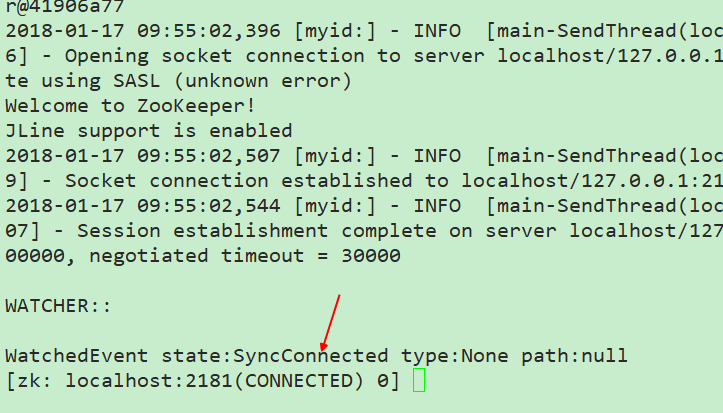
可以看到连接上了自己这一台
打开帮助信息,可以 看到如果想要连接其他的服务器,可以使用-server host:port的形式,或者在当前使用connect host:port的形式
[zk: localhost:2181(CONNECTED) 0] help
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
切换服务器:
[zk: localhost:2181(CONNECTED) 0] connect 192.168.137.138:2181
这样就切换过来了:

2.zookeeper的数据的结构
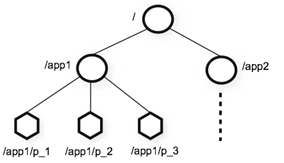
1、层次化的目录结构,命名符合常规文件系统规范(见下图)
2、每个节点在zookeeper中叫做znode,并且其有一个唯一的路径标识
3、节点Znode可以包含数据和子节点(但是EPHEMERAL类型的节点不能有子节点,下一页详细讲解)
4、客户端应用可以在节点上设置监视器(后续详细讲解)
如图所示:
节点类型:
1、Znode有两种类型:
短暂(ephemeral)(断开连接自己删除)
持久(persistent)(断开连接不删除)
2、Znode有四种形式的目录节点(默认是persistent )
PERSISTENT
PERSISTENT_SEQUENTIAL(持久序列/test0000000019 )
EPHEMERAL
EPHEMERAL_SEQUENTIAL
3、创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
4、在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
3.客户端操作
基本上操作可以在help列出的命令中查看
1.查看
[zk: 192.168.137.138:2181(CONNECTED) 2] ls /
[zookeeper]
//可以看到只有一个根节点
2.创建znode
-e参数:短暂节点
-s节点:是否带序号(SEQUENTIAL)
主要短暂节点下不能有子节点!
[zk: 192.168.137.138:2181(CONNECTED) 3] create /app1 "this is app1"
Created /app1
[zk: 192.168.137.138:2181(CONNECTED) 4] ls /
[zookeeper, app1]
//可以看到这里创建了一个示例的字符串节点,由于默认是持久节点,如果需要创建短暂节点,请使用-e参数!
创建带序号的znode:
[zk: 192.168.137.138:2181(CONNECTED) 9] create /test 666
Created /test
[zk: 192.168.137.138:2181(CONNECTED) 10] create -s /test/aaa 777
Created /test/aaa0000000000
[zk: 192.168.137.138:2181(CONNECTED) 11] create -s /test/aaa 777
Created /test/aaa0000000001
//可以看到节点自动带了编号,所以即使重名也是允许的!当然只在次目录从0开始标序号,切换目录创建带序号的将会重新从0开始
当然,/app1还可以有子节点
[zk: 192.168.137.138:2181(CONNECTED) 5] create /app1/server01 "192.168.137.138,100"
Created /app1/server01
3.查看znode数据
[zk: 192.168.137.138:2181(CONNECTED) 6] ls /app1
[server01]
[zk: 192.168.137.138:2181(CONNECTED) 7] get /app1
"this
cZxid = 0x100000008
ctime = Wed Jan 17 10:12:18 CST 2018
mZxid = 0x100000008
mtime = Wed Jan 17 10:12:18 CST 2018
pZxid = 0x100000009
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 1
//可以看到它这里直接以空格就给分割了,不直接把引号内容当作数据;当然,我们写Java API的时候肯定是不会以空格就分断的,这仅仅是客户端的问题
4.修改znode数据
修改的数据在各个节点之间基本上是实时同步的!
[zk: 192.168.137.138:2181(CONNECTED) 12] set /app1 yyy
cZxid = 0x100000008
ctime = Wed Jan 17 10:12:18 CST 2018
mZxid = 0x10000000d
mtime = Wed Jan 17 10:37:08 CST 2018
pZxid = 0x100000009
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 1
5.删除znode
znode 删除(只能删除没有子节点的)
[zk: 202.115.36.251:2181(CONNECTED) 5] delete /zk
删除节点:rmr(整个节点和子节点全部删除)
[zk: 202.115.36.251:2181(CONNECTED) 5] rmr /zk
更多增删改查的实例,参考:https://www.cnblogs.com/sherrykid/p/5813148.html
6.监听
其他机器发生修改了,本机立马可以收到通知!
其中get监听是监听内容的变化(子节点变化不会影响)
使用ls /app1 watch时,再创建子节点就会有监听了!
[zk: 192.168.137.138:2181(CONNECTED) 14] get /app1 watch
yyy
cZxid = 0x100000008
ctime = Wed Jan 17 10:12:18 CST 2018
mZxid = 0x10000000d
mtime = Wed Jan 17 10:37:08 CST 2018
pZxid = 0x100000009
cversion = 1
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 1
[zk: 192.168.137.138:2181(CONNECTED) 15]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDataChanged path:/app1
更多znode详解,参考:http://blog.csdn.net/lihao21/article/details/51810395

 浙公网安备 33010602011771号
浙公网安备 33010602011771号