MySQL高级第三章——查询截取分析
一、查询分析
1.永远小表驱动大表
使用小的数据集驱动大的数据集。
//复习 EXISTS 的知识:SELECT ... FROM tb WHERE EXISTS (subquery) 是因为前后数据集不一致时EXISTS比IN性能更高。
(子查询可以改写IN的写法为SELECT 1 FROM tb WHERE ...等)
对EXISTS的理解:
将主查询的数据,放到子查询中作条件验证,根据验证结果(TRUE | FALSE)来决定主查询的数据结果是否得以保留。
2.ORDER BY排序优化
现在我们关心的的不再是是WHERE后的(之前几节已经做过分析),我们关系的是ORDER BY后的,也就是是否产生了 filesort
排序有两种情况:use index use filesort,由前面一章已经知道,最好不要有 filesort,Index的排序效率更高
ORDER BY的排序依旧是使用索引的最左前列,也就是最左前缀原则依旧适用。并且,使用WHERE 和 ORDER BY来匹配最左前缀原则。
所以说,应当尽可能的在索引列上完成排序操作,并遵循最左前缀原则。
如果需求确实使得排序不在索引列上,Mysql就要启动filesort,其中存在两种算法:双路排序和单路排序
关于排序算法,可以参见:http://www.cnblogs.com/zhoujinyi/p/5437289.html (mysql4.1之前都是需要两次IO的双路排序)
一些ORDER BY的排序优化实例,请参见:http://blog.csdn.net/z69183787/article/details/53389773
关于如何进行ORDER BY的调优:
增大sort_buffer_size参数的设置
增大max_length_for_data参数的设置
在排序时请尽量避免SELECT *,避免ASC DESC同时出现(都是ASC DESC都能用到索引,但不能同时存在升降序)
3.GROUP BY的优化
GROUP BY实质是先排序,后分组;并且遵循索引的最左前缀原则。
参数的设置与ORDER BY的调优一致。
能使用WHERE 限定就不要使用HAVING
二、慢查询日志
1.是什么?
慢查询日志是将mysql服务器中影响数据库性能的相关SQL语句记录到日志文件,通过对这些特殊的SQL语句分析,改进以达到提高数据库性能的目的。
通过使用--slow_query_log[={0|1}]选项来启用慢查询日志。所有执行时间超过long_query_time秒(可以看到,默认是10s,可自定义)的SQL语句都会被记录到慢查询日志。
缺省情况下hostname-slow.log为慢查询日志文件安名,存放到数据目录,同时缺省情况下未开启慢查询日志。
// 通过抓取慢的SQL,结合之前的起手式 EXPLAIN 就可以进行慢日志的分析
2.怎么玩?
查看是否开启:show variables like '%slow_query%'

//这里显示了位置与开启状态。
设置位置:set global slow_query_log_file="/var/lib/mysql/mysql_slow_query.log";
如何开启:set global slow_query_log=1;

//注意,这只是临时开启,并且仅仅针对本数据库有效,重启后便失效。(当然,慢日志应当是尽量避免开启,只在需要分析时开启)
若要永久开启慢日志,需要修改配置文件,请参见:https://jingyan.baidu.com/article/0aa223755476db88cc0d6492.html
查看慢查询时间:show variables like "long_query_time";

//默认为10秒,并且,是 >而非 >=
设置慢查询时间阈值:set global long_query_time=3;(设置阈值为3秒)

//神奇的发现,还是10秒。需要重新建立一次连接才能看到!或者通过查看全局变量的形式查看:

模拟慢查询的SQL:通过sleep(),类似线程

找到慢日志:
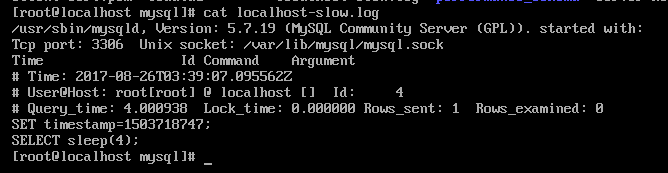
查看慢日志:
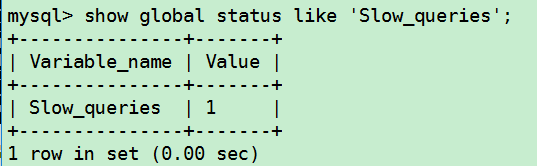
查看出现慢查询日志的累计值:
3.日志分析工具——mysqldumpslow
手工查看日志显然不科学,mysql提供了日志分析工具:mysqldumpsolw
查看帮助信息(之前命令复习):


各参数简述:

实例如下:(分析命令+日志位置)

参数使用可以参见:http://www.cnblogs.com/cyt1153/p/6569124.html
三、批量数据脚本
大致步骤如下:
(详细步骤可以参见:http://www.cnblogs.com/Onlywjy/archive/2017/08/13/7354865.html)
建表(员工部门表);
为了防止插入大数据报错,开启参数:log_bin_trust_function_creators=1;
创建产生随机字符串的函数(用于插入不重复的数据);
同理,创建产生随机部门编号的函数;
创建存储过程,调用函数插入记录(一次50W条,调用20次);
调用存储过程,插入记录;
四、show profile
1.是什么
SHOW PROFIL命令是MySQL提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量。
与之前的功能一样,mysql为了提高自身性能,很多高级功能都是关闭的,需要手动开启。
2.分析步骤:
查看是否支持

//可以看到,默认是关闭的。
开启show profile——SET profiling=1;或 SET profiling=on;

//默认保存15条
运行SQL
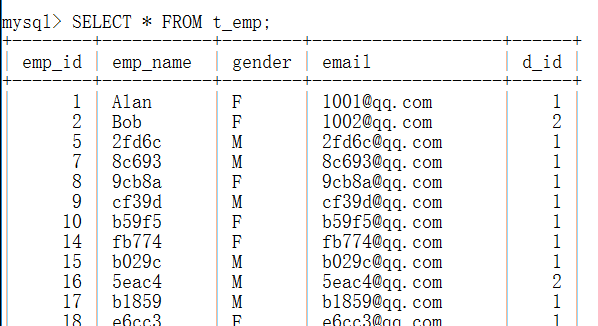
查看总体结果——show profiles;

//显示了详细的查询ID,持续时间,查询语句
查看详细结果——SHOW PROFILE FOR QUERY n | show profile cpu,block io fro query n;
当然除了常用的cpu block io等信息,还可以选择其它信息

//列出了完整的生命周期。(n代表query ID)
//可以看出,发送数据比执行更长等信息
以上繁杂的信息中,出现以下信息:危险!
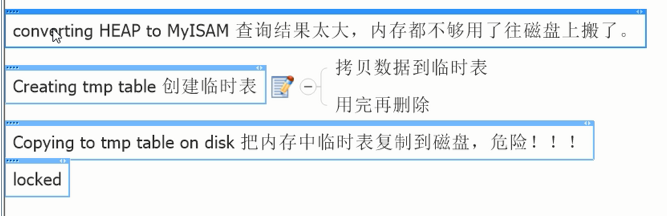
//出现了临时表等信息,慎重!
五、全局查询日志
强烈建议:只能测试环境使用,慎用!生产环境严禁使用!
开启:
Set global general_log=1;
Set global log_output=’TABLE’;
此后,你所编写的sql语句 都会被记录到mysql 库里的general_log表,可以用以下命令查看:
Select * from mysql.general_log;
这样,就可以根据时间来定位收集发生问题的SQL

 浙公网安备 33010602011771号
浙公网安备 33010602011771号