尚硅谷-flink
一、介绍
1.简介
flink是一个开源的分布式流处理框架
优势:高性能处理、高度灵活window操作、有状态计算的Exactly-once等
详情简介,参考官网:https://flink.apache.org/flink-architecture.html
中文参考:https://flink.apache.org/zh/flink-architecture.html
flink组件介绍:
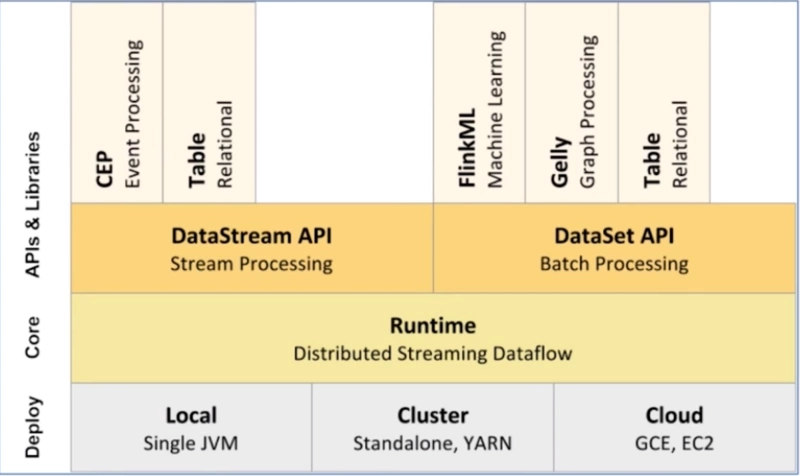
1)部署:支持本地、集群(支持yarn资源管理)、云
flink作业部署:https://blog.csdn.net/qq_42881421/article/details/138524682
2)核心层:提供了计算的核心
3)API:提供了面向流处理的DataStream和面向批处理的DataSet
4)类库:支持Table/SQL
基本架构为 DataSource(数据源) -> Transfromation(算子处理数据) ->DataSink(数据目的)
分层API:

··
二、快速上手
wordcount:
1.新建maven项目:
2.导入依赖(提交到服务区的,可以对flink的依赖使用<provided>)
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <flink.version>1.17.0</flink.version> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> </dependency> </dependencies>
3.创建用于测试的txt文件
4.执行步骤
1、创建流处理环境:
2、从文件中读取数据:
3、进行WordCount操作:
4、打印结果到控制台:
5、执行任务:
代码如下:
package org.example; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * Hello world! */ public class App { public static void main(String[] args) throws Exception { // 创建flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 从文件读取数据 DataStreamSource<String> source = env.readTextFile("input/word.txt"); // 处理数据,执行wordcount操作 SingleOutputStreamOperator<Tuple2<String, Integer>> summed = source.flatMap(new Tokenizer()) .keyBy(0) .sum(1); // 打印结果 summed.print(); // 启动执行 env.execute("WordCount"); } // 自定义FlatMapFunction,用于分词 public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // 将输入的字符串按空格分割 String[] words = value.split("\\s+"); // 遍历每个单词,并生成 (word, 1) 的元组 for (String word : words) { out.collect(new Tuple2<>(word, 1)); } } } }
三、flink集群
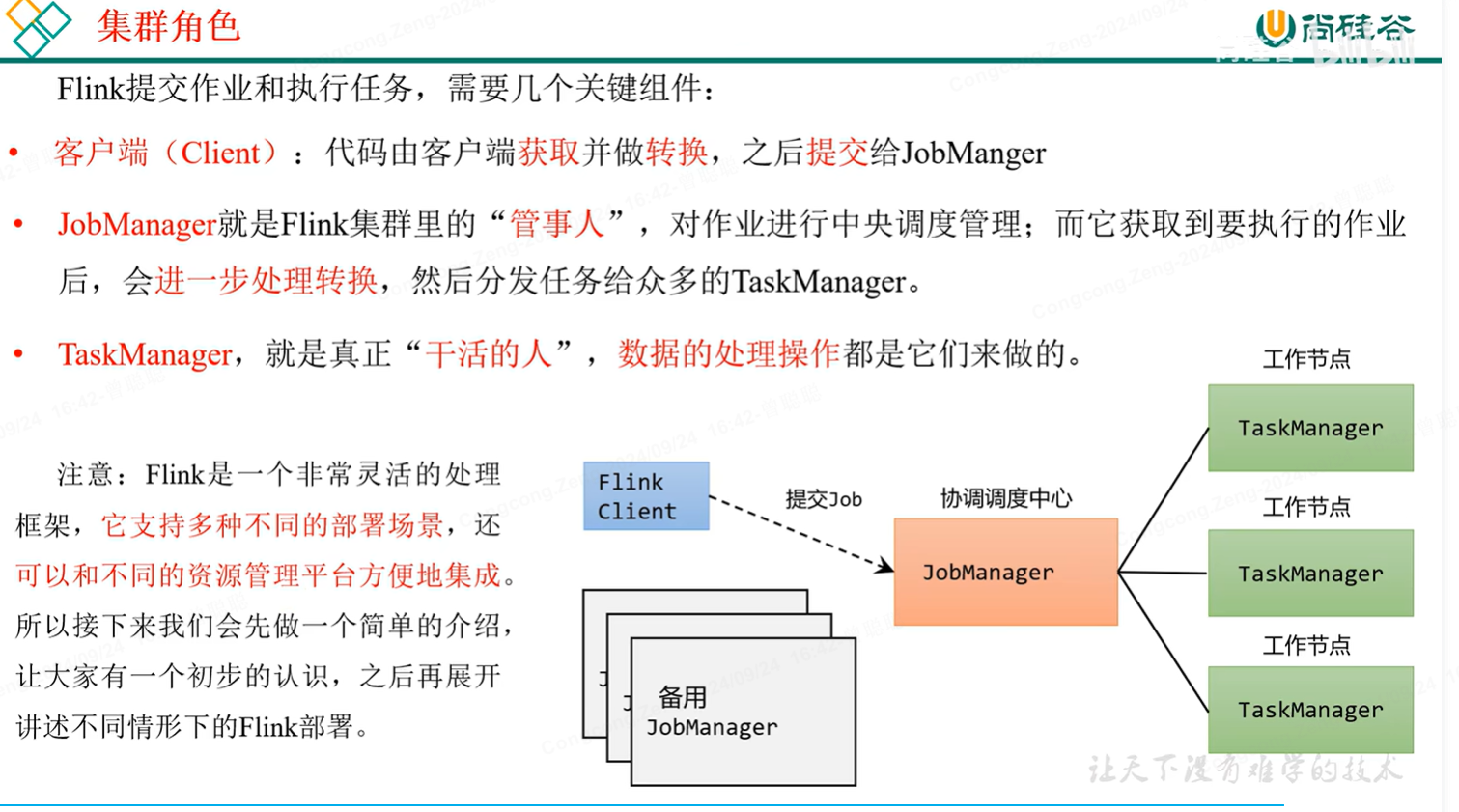
集群角色:
四、运行时核心概念
并行度:特定算子的子任务的并行度,
并行度设置:
1.代码中设置:
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = source.flatMap(new Tokenizer()) .setParallelism(2) .keyBy(0) .sum(1);
还可以通过env和提交时指定
算子 > env > 提交时设置
插槽、运行提交流程等。。。
五、DataStream API
是flink的核心API,flink的运行流程:
1、创建流处理环境:
2、读取数据:
3、转换操作:
4、输出结果:
5、执行任务:(程序是懒执行)
DS主要负责1和5
fromSource是新API
算子后面.name()增加一个名字,方便在ui上监控
算子:
map-一进一出,改造完出来重新做人
// 获取运行环境(可以通过conf配置) StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 从集合中读取数据 DataStreamSource<WaterSenor> source = env.fromElements(new WaterSenor("sensor_1", 1547718199L, 35), new WaterSenor("sensor_2", 1547718191L, 31), new WaterSenor("sensor_3", 1547718192L, 32)); // 转换数据 SingleOutputStreamOperator<String> map = source.map(s -> s.getId()); map.print(); // 执行 env.execute();
记得执行的步骤!
当然,工作中一般建议定义一个类来实现,如果通过lambda表达式,很难通用,且改起来费劲。推荐的用法如下(用一个service包来进行算子转换)
实现MapFunction接口,两个泛型分别是输入输出类型:
package service; import bean.WaterSenor; import org.apache.flink.api.common.functions.MapFunction; public class MyMapFunction implements MapFunction<WaterSenor, String> { @Override public String map(WaterSenor value) throws Exception { return value.getId() + ":" + value.getVc(); } }
使用的话new一个就行:
// 获取运行环境(可以通过conf配置) StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 从集合中读取数据 DataStreamSource<WaterSenor> source = env.fromElements(new WaterSenor("sensor_1", 1547718199L, 35), new WaterSenor("sensor_2", 1547718191L, 31), new WaterSenor("sensor_3", 1547718192L, 32)); // 转换数据 SingleOutputStreamOperator<String> map = source.map(new MyMapFunction()); map.print(); // 执行 env.execute();
filter过滤,为true则保留,否则过滤掉
同理,实现一个接口,泛型是要过滤的数据的类型:
package service; import bean.WaterSenor; import org.apache.flink.api.common.functions.FilterFunction; public class MyFilterFunction implements FilterFunction<WaterSenor> { @Override public boolean filter(WaterSenor value) throws Exception { return "sensor_1".equalsIgnoreCase(value.getId()); } }
使用的时候使用.filter传入函数即可:
// 获取运行环境(可以通过conf配置) StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 从集合中读取数据 DataStreamSource<WaterSenor> source = env.fromElements(new WaterSenor("sensor_1", 1547718199L, 35), new WaterSenor("sensor_2", 1547718191L, 31), new WaterSenor("sensor_3", 1547718192L, 32)); // 转换数据 SingleOutputStreamOperator<WaterSenor> map = source.filter(new MyFilterFunction()); map.print(); // 执行 env.execute();
flatMap,扁平映射,一进多出,比如wordcount的时候,一行返回多个单词
也是实现一个类,泛型表示输入输出类型:
package service; import bean.WaterSenor; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.util.Collector; public class MyFlatMapFunction implements FlatMapFunction<WaterSenor, String> { @Override public void flatMap(WaterSenor value, Collector<String> out) throws Exception { if ("sensor_1".equalsIgnoreCase(value.getId())) { out.collect(value.getTs().toString()); } else if ("sensor_2".equalsIgnoreCase(value.getId())){ out.collect(value.getTs().toString()); out.collect(value.getVc().toString()); } } }
使用的时候,new一个类,这里flatmap可以0输出,所以这里的sensor_3不输出,不处理:
// 获取运行环境(可以通过conf配置) StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 从集合中读取数据 DataStreamSource<WaterSenor> source = env.fromElements(new WaterSenor("sensor_1", 1547718199L, 35), new WaterSenor("sensor_2", 1547718191L, 31), new WaterSenor("sensor_3", 1547718192L, 32)); // 转换数据 SingleOutputStreamOperator<String> map = source.flatMap(new MyFlatMapFunction()); map.print(); // 执行 env.execute();
侧输出:
package com.sumatra.rt.dw.tsp.app; import java.util.List; import org.apache.commons.collections.CollectionUtils; import org.apache.commons.lang3.StringUtils; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.ecarx.sumatra.data.common.AppContext; import com.ecarx.sumatra.data.common.GsonFactory; import com.ecarx.sumatra.data.common.MessageImport; import com.ecarx.sumatra.data.common.constant.RealtimeDwConstant; import com.ecarx.sumatra.data.common.constant.RealtimeDwConstant.DataType; import com.ecarx.sumatra.data.common.constant.RealtimeDwConstant.Databases; import com.ecarx.sumatra.data.common.constant.RealtimeDwConstant.TableEvent; import com.ecarx.sumatra.data.dto.BaseFieldDTO; import com.ecarx.sumatra.data.es.IndexDocument; import com.ecarx.sumatra.data.sink.ElasticSearchDataSink; import com.ecarx.sumatra.data.sink.KafkaMessageSink; import com.ecarx.sumatra.data.tab.conf.EnvConfig; import com.ecarx.sumatra.data.tab.conf.TspTableEntityMapping; import com.google.gson.JsonObject; import com.sumatra.rt.dw.tsp.process.AbstractTspDataProcess; /** * * @author ecamrx HF CN 二代云宽表 */ public class EcarxCloud2TspDataProcessApp extends MessageImport { private static final long serialVersionUID = 4962380402534817613L; private static final Logger LOG = LoggerFactory.getLogger(EcarxCloud2TspDataProcessApp.class); private static final OutputTag<String> BASE_FIELD_TAG = new OutputTag<>(BaseFieldDTO.class.getName(), TypeInformation.of(String.class)); private KafkaMessageSink kafkaSink; private static final int parallelism = 4 * 6; public static void main(String[] args) { // TODO Auto-generated method stub runOnEnv(); } private static void runOnEnv() { EnvConfig.init(); AppContext context = new AppContext(EnvConfig.getEnvConfig(), true); context.setTaskName("EcarxCloud2TspDataProcessApp-" + EnvConfig.getEnvName()); EcarxCloud2TspDataProcessApp app = new EcarxCloud2TspDataProcessApp(context); try { app.start(); } catch (Exception e) { LOG.error("submit {} failed.{}", app.getClass().getSimpleName(), e.getMessage()); e.printStackTrace(); } } public EcarxCloud2TspDataProcessApp(AppContext appContext) { super(appContext); // TODO Auto-generated constructor stub this.kafkaSink = new KafkaMessageSink(appContext); } @Override protected void dataProcess(DataStream<String> dataStream) { // TODO Auto-generated method stub SingleOutputStreamOperator<String> filterStream = dataStream.filter(new TspDataStreamFilter()) .setParallelism(parallelism).name(super.operateName("filter")); SingleOutputStreamOperator<IndexDocument> mappedStream = filterStream .process(new TspDataStreamProcessFunction()).setParallelism(parallelism).name(super.operateName("map")); mappedStream.addSink(new ElasticSearchDataSink()).setParallelism(parallelism).name(super.operateName("sink")); mappedStream.getSideOutput(BASE_FIELD_TAG).sinkTo(this.kafkaSink.getSink()).setParallelism(parallelism / 8) .name(super.operateName("kafka-sink")); } // inner class class TspDataStreamProcessFunction extends ProcessFunction<String, IndexDocument> { private static final long serialVersionUID = 8633184485261223320L; private AbstractTspDataProcess processor = AbstractTspDataProcess.newInstance(); @Override public void processElement(String input, ProcessFunction<String, IndexDocument>.Context ctx, Collector<IndexDocument> collector) throws Exception { // TODO Auto-generated method stub // LOG.info("input value is {}", input); IndexDocument indexDoc = IndexDocument.parseDocument(input); if (indexDoc == null || indexDoc.valid() == false) { LOG.error("input value is invalid.{}", input); return; } if (DataType.BDP_DATA != indexDoc.dataType()) { collector.collect(indexDoc); } else { LOG.info("bdp data:{},{}", input, indexDoc); } if (TspTableEntityMapping.verifyTable(indexDoc.getDatabase(), indexDoc.getTable())) { List<IndexDocument> docList = processor.process(indexDoc); if (CollectionUtils.isNotEmpty(docList)) { for (IndexDocument indexDocment : docList) { try { List<BaseFieldDTO> dtoList = BaseFieldDTO.parse(indexDocment); if (CollectionUtils.isNotEmpty(dtoList)) { for (BaseFieldDTO dto : dtoList) { LOG.info("Emit BaseFieldDTO {}", dto.toString()); ctx.output(BASE_FIELD_TAG, dto.toString()); } } } catch (Exception e) { LOG.error("Emit BaseFieldDTO error {}", indexDocment, e); e.printStackTrace(); } finally { collector.collect(indexDocment); } } } } } } // inner class class TspDataStreamFilter implements FilterFunction<String> { private static final long serialVersionUID = -1607394751777512119L; @Override public boolean filter(String value) throws Exception { // True for values that should be retained, false for values to be filtered out. try { if (StringUtils.isEmpty(value)) { return false; } JsonObject gson = GsonFactory.getInstance().fromJson(value, JsonObject.class); if (gson.has("index") && gson.get("index").isJsonNull() == false && RealtimeDwConstant.BDP_ES_TSP_WIDE_TABLE.equals(gson.get("index").getAsString())) { // bdp data return true; } if (gson.get("database").isJsonNull() || StringUtils.isEmpty(gson.get("database").getAsString())) { return false; } if (gson.get("table").isJsonNull() || StringUtils.isEmpty(gson.get("table").getAsString())) { return false; } if (gson.get("type").isJsonNull() || StringUtils.isEmpty(gson.get("type").getAsString())) { return false; } if (gson.get("data").isJsonNull() || gson.get("data").getAsJsonArray().size() == 0) { return false; } if (gson.get("pkNames").isJsonNull() || gson.get("pkNames").getAsJsonArray().size() == 0) { return false; } if (Databases.getDatabase(gson.get("database").getAsString()) == null) { return false; } if (TableEvent.getEvent(gson.get("type").getAsString()) == null) { return false; } if (TableEvent.getEvent(gson.get("type").getAsString()) == TableEvent.UPDATE && gson.get("old").isJsonNull() && gson.getAsJsonArray("old").size() == 0) { return false; } if (TspTableEntityMapping.verifyTable(gson.get("database").getAsString(), gson.get("table").getAsString())) { // only this tables return true; } } catch (Exception e) { e.printStackTrace(); LOG.error(value, e); } return false; } } }
序列化:
SimpleStringSchema 是一个简单但非常实用的类,主要用于处理字符串类型的流数据。它在 Flink 应用程序中与 Kafka 连接器集成时特别有用,能够方便地进行字符串的序列化和反序列化操作。
详细:

https://cloud.tencent.com/developer/article/1505275
双流联结-略
类型:
内置类型:直接使用 TypeInformation.of(类型.class)。-- 如string
POJO 类型:确保类符合 Flink 序列化要求,并使用 TypeInformation.of(POJO.class)。
简化工具:利用 Types 工具类简化常见类型的 TypeInformation 创建。
处理算子process:比map filter等更底层,可以侧输出等,拿得到上下文
基本处理函数提供了一个“定时服务”(TimerService),我们可以通过它访问流中的事件(event)、时间戳(timestamp)、水位线(watermark),甚至可以注册“定时事件”。
根据不同场景分位不同的方法类:
process算子有4个方法类,包括
- ProcessFunction、
- KeyedProcessFunction、
- BroadcastProcessFunction、
- KeyedBroadcastProcessFunction。其中KeyedProcessFunction及KeyedBroadcastProcessFunction只能处理keyedStream,ProcessFunction及BroadcastProcessFunction只能处理DataSteam
最原始的process实现以下方法就行:
/** * 用于处理元素 * value:当前流中的输入元素,也就是正在处理的数据,类型与流中数据类 * ctx:类型是 ProcessFunction 中定义的内部抽象类 Context,表示当前运行的上下文,可以获取到当前的时间戳, * 并提供了用于查询时间和注册定时器的“定时服务”(TimerService),以及可以将数据发送到“侧输出流”(side output)的方法.output()。 * out:"收集器"(类型为 Collector),用于返回输出数据。使用方式与 flatMap算子中的收集器完全一样,直接调用 out.collect()方法就可以向下游发出一个数据。 */ @Override public void processElement(I value, Context ctx, Collector<O> out) throws Exception {}
flink状态:
状态可以认为是一个本地变量:

一般都用托管状态,按照是否Keyby可以分位算子状态和键控状态,状态管理和任务是绑定的,同一算子不同并行度是各自维护状态的,
键控任务则是同一个key维护同一份状态
开发用的最多的是键控状态!
可以分为如下种类的键控状态:

值状态:
// 获取flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行度为1 env.setParallelism(1); // 从集合获取数据 DataStreamSource<WaterSenor> streamSource = env.fromElements(new WaterSenor("i_sensor", 1547718199L, 5), new WaterSenor("u_sensor", 1547718201L, 16), new WaterSenor("u_sensor", 1547718202L, 12)); SingleOutputStreamOperator<String> processed = streamSource.keyBy(WaterSenor::getId) .process(new MyKeyedProcessFucntion()); processed.print(); // 启动执行 env.execute();
package service; import bean.WaterSenor; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; public class MyKeyedProcessFucntion extends KeyedProcessFunction<String, WaterSenor, String> { // 定义值状态 ValueState<Integer> valueState; @Override public void open(Configuration parameters) throws Exception { valueState = getRuntimeContext().getState(new ValueStateDescriptor<>("valueState", Types.INT)); } @Override public void processElement(WaterSenor value, KeyedProcessFunction<String, WaterSenor, String>.Context ctx, Collector<String> out) throws Exception { // 取出上一条的水位值 Integer lastVc = valueState.value() == null ? 0 : valueState.value(); Integer vc = value.getVc(); if(Math.abs(vc -lastVc) > 10){ out.collect(String.format("当前水位值与上一次水位值大于10,当前水位值:%s,上一次水位值:%s", vc, lastVc)); } // 更新状态 valueState.update(vc); } }
列表状态:
package env; import bean.WaterSenor; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import service.MyKeyedProcessFunction2; public class Demo2 { public static void main(String[] args) throws Exception { // 获取flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行度为1 env.setParallelism(1); // 从集合获取数据 DataStreamSource<WaterSenor> streamSource = env.fromElements(new WaterSenor("i_sensor", 1547718199L, 5), new WaterSenor("i_sensor", 1547718201L, 16), new WaterSenor("i_sensor", 1547718202L, 12), new WaterSenor("i_sensor", 1547718202L, 220), new WaterSenor("u_sensor", 1547718201L, 16), new WaterSenor("u_sensor", 1547718202L, 12), new WaterSenor("u_sensor", 1547718202L, 19), new WaterSenor("u_sensor", 1547718202L, 230) ); SingleOutputStreamOperator<String> processed = streamSource.keyBy(WaterSenor::getId) .process(new MyKeyedProcessFunction2()); processed.print(); // 启动执行 env.execute(); } }
package service; import bean.WaterSenor; import org.apache.flink.api.common.state.ListState; import org.apache.flink.api.common.state.ListStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; import java.util.ArrayList; import java.util.List; public class MyKeyedProcessFunction2 extends KeyedProcessFunction<String, WaterSenor, String> { // 列表状态 ListState<Integer> listState; // 初始化 public void open(Configuration parameters) throws Exception { listState = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("listState", Integer.class)); } @Override public void processElement(WaterSenor value, KeyedProcessFunction<String, WaterSenor, String>.Context ctx, Collector<String> out) throws Exception { listState.add(value.getVc()); // 从list状态把数据拿出来,放到list中进行排序 Iterable<Integer> iterable = listState.get(); List<Integer> vclist = new ArrayList<>(); for (Integer i : iterable) { vclist.add(i); } // 降序排列 vclist.sort((o1, o2) -> o2 - o1); // vclist只保留前3个数据 if(vclist.size() > 3){ vclist.remove(3); } out.collect(String.format("传感器id为:%s,最大的3个水位值为:%s", value.getId(), vclist.toString())); //更新状态 listState.update(vclist); } }
映射状态:
public static void main(String[] args) throws Exception { // 获取flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行度为1 env.setParallelism(1); // 从集合获取数据 DataStreamSource<WaterSenor> streamSource = env.fromElements(new WaterSenor("i_sensor", 1547718199L, 5), new WaterSenor("i_sensor", 1547718201L, 16), new WaterSenor("i_sensor", 1547718202L, 12), new WaterSenor("i_sensor", 1547718202L, 12), new WaterSenor("u_sensor", 1547718201L, 16), new WaterSenor("u_sensor", 1547718202L, 12), new WaterSenor("u_sensor", 1547718202L, 16), new WaterSenor("u_sensor", 1547718202L, 230) ); SingleOutputStreamOperator<String> processed = streamSource.keyBy(WaterSenor::getId) .process(new MyKeyedFunction3()); processed.print(); // 启动执行 env.execute(); }
package service; import bean.WaterSenor; import org.apache.flink.api.common.state.MapState; import org.apache.flink.api.common.state.MapStateDescriptor; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.KeyedProcessFunction; import org.apache.flink.util.Collector; public class MyKeyedFunction3 extends KeyedProcessFunction<String, WaterSenor, String> { MapState<Integer, Integer> mapState; // 初始化 @Override public void open(Configuration parameters) throws Exception { mapState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer, Integer>("map-state", Integer.class, Integer.class)); } @Override public void processElement(WaterSenor value, KeyedProcessFunction<String, WaterSenor, String>.Context ctx, Collector<String> out) throws Exception { Integer vc = value.getVc(); if(mapState.contains(vc)){ Integer count = mapState.get(vc); mapState.put(vc, count + 1); }else{ mapState.put(vc, 1); } out.collect(String.format("当前水位值:%s,当前水位值出现次数:%s", vc, mapState.get(vc))); } }
规约和聚合,暂略。和reduce等逻辑是相通类似的。
故障恢复
检查点的保存:
checkpoint检查点,就是某个时间点的所有状态
检查点的保存是周期性的,间隔时间可设置。
保存一条数据恰好被所有任务完整的处理完的状态,恢复时从下一条恢复保证数据恢复的可靠,否则让source进行重放,重新放数据进来即可。
检查点的恢复:
当任务挂了以后,找到最近一次的备份检查点,分别恢复到对应的状态中。
重置偏移量:假如一条流,在第3条的时候保存了checkpoint,第5条的时候挂了,如果重启后直接从第5条开始,那么就丢数据了,此时应该重置偏移量,重新从第4次开始计算。此时实现的就是精准一次,
考虑幂等性,如重复sink的问题,会不会计算错误等。
jobManager有一个检查点协调器,让taskMangaer保存检查点
检查点算法;暂略
检查点配置
默认检查点是关闭的,开启:
// 获取flink执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 设置并行度为1 env.setParallelism(1); // 开启检查点(默认单位ms,默认精准一次,可以通过ctrl+P参数查看) env.enableCheckpointing(10000);
指定检查点保存位置:
代码中用到HDFS,需要导入hadoop依赖、指定访问HDFS的用户名
System.setProperty("HADOOP_USER_NAME", "HADOOP");// 检查点配置 CheckpointConfig checkpointConfig = env.getCheckpointConfig(); checkpointConfig.setCheckpointStorage("hdfs://hadoop01:8082/ck");
检查点有很多其他配置项:
// 1、启用检查点: 默认是barrier对齐的,周期为5s, 精准一次
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
// 2、指定检查点的存储位置
checkpointConfig.setCheckpointStorage("hdfs:///ip:port/dir");
// 3、checkpoint的超时时间: 默认10分钟
checkpointConfig.setCheckpointTimeout(60000);
// 4、同时运行中的checkpoint的最大数量
checkpointConfig.setMaxConcurrentCheckpoints(1);
// 5、最小等待间隔: 上一轮checkpoint结束 到 下一轮checkpoint开始 之间的间隔
checkpointConfig.setMinPauseBetweenCheckpoints(1000);
// 6、取消作业时,checkpoint的数据 是否保留在外部系统
// DELETE_ON_CANCELLATION:主动cancel时,删除存在外部系统的chk-xx目录 (如果是程序突然挂掉,不会删)
// RETAIN_ON_CANCELLATION:主动cancel时,外部系统的chk-xx目录会保存下来
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 7、允许 checkpoint 连续失败的次数,默认 0 表示 checkpoint 一失败,job 就挂掉
checkpointConfig.setTolerableCheckpointFailureNumber(10);
实际配置示例:
logger.info("start config flink StreamExecutionEnvironment ... ")
// == 设置用户执行程序的账户名称
System.setProperty("HADOOP_USER_NAME", "hdfs")
// == flink 流 env
val env = StreamExecutionEnvironment.getExecutionEnvironment
val flinkConf: FlinkConfiguration = FlinkConfiguration.apply()
/**
* 开启checkpoint 3min
*/
env.enableCheckpointing(flinkConf.checkpointingTime)
// 设置 执行语义 : 仅消费一次
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(flinkConf.checkpointTimeout)
// 两个检查点的最小间隔
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(flinkConf.minPauseBetweenCheckpoints)
// 同一时间只允许进行一个检查点
env.getCheckpointConfig.setMaxConcurrentCheckpoints(flinkConf.maxConcurrentCheckpoints)
// RETAIN_ON_CANCELLATION 在job失败和 手动 stop时,保留checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
// hdfs checkpoint dir :
if(!DevConfiguration.apply().isDev){
env.setStateBackend(new FsStateBackend(flinkConf.checkpointDataUri))
}
env
配置文件:
flink { checkpointingTime = 180000 checkpointTimeout = 60000 minPauseBetweenCheckpoints = 500 maxConcurrentCheckpoints = 1 # eastSoftRvs2oss # checkpointDataUri = "hdfs://emr-cluster/flink/checkpoints/eastSoftRvs2oss" # flinkOutputDir = "oss://sumatra/user/hive/warehouse/ods.db/ods_eastSoft_rvs_source_di_parquet" # flinkOutputDir = "hdfs://emr-cluster/test/flink/ods_eastSoft_rvs_source_di_parquet" # financialControl2kafka # checkpointDataUri = "hdfs://emr-cluster/flink/checkpoints/local/financialControl2kafka" checkpointDataUri = "hdfs://emr-cluster/flink/checkpoints/local/rvsDataTrans-local" flinkOutputDir = "hdfs://emr-cluster/test/flink/ods_ihu_can_source_di_parquet" # sensors point # checkpointDataUri = "hdfs://emr-cluster/flink/checkpoints/sensorDataSouce2ossApp" # flinkOutputDir = "hdfs://emr-cluster/test/flink/ods_sensors_point_source_di_parquet" # sensors point # checkpointDataUri = "hdfs://emr-cluster/flink/checkpoints/local/eastSoftRvsTrans2HdfsApp" # flinkOutputDir = "hdfs://emr-cluster/test/flink/ods_eastSoft_rvs_source_di_parquet" flinkGlobalParallelism = 2 }
除了检查点,还可以有保存点(savepoint),用于手动触发保存状态,可以用来更新flink版本等等
java版本的配置示例:
package com.ecarx.sumatra.data.common; import java.io.Serializable; import java.util.List; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.configuration.Configuration; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.runtime.state.filesystem.FsStateBackend; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup; import org.apache.flink.streaming.api.environment.ExecutionCheckpointingOptions; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import com.google.common.collect.Lists; public abstract class MessageImport implements Serializable { private static final Logger LOG = LoggerFactory.getLogger(MessageImport.class); protected AppContext appContext; private int parallelism = 2; public void start() throws Exception { this.execute(); } private void execute() { try { System.setProperty("HADOOP_USER_NAME", "hadoop"); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(parallelism); env.enableCheckpointing(1000 * 60 * 3); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setCheckpointTimeout(1000 * 60 * 3); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(1000 * 60); env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); env.getCheckpointConfig().enableUnalignedCheckpoints(); env.getCheckpointConfig() .setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // state.checkpoints.dir String checkpointDir = appContext.getAppConf().getProperty("state_store") + "/" + appContext.getTaskName(); /** * env.getCheckpointConfig().setCheckpointStorage(checkpointDir); * 新API使用麻烦,需要配置OSS * https://nightlies.apache.org/flink/flink-docs-release-1.15/docs/deployment/filesystems/oss/ * * */ env.setStateBackend(new FsStateBackend(checkpointDir)); Configuration config = new Configuration(); config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, true); env.configure(config); String groupId = this.appContext.getKafkaConfig().getProperty("group.id"); String bootstrapServers = this.appContext.getKafkaConfig().getProperty("bootstrap.servers"); String topics = this.appContext.getKafkaConfig().getProperty("topics"); List<String> topicList = Lists.newArrayList(topics.split(",")); LOG.info("kafka.group.id:{},bootstrapServers:{},topics:{}", groupId, bootstrapServers, topics); KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(bootstrapServers) .setTopics(topicList).setStartingOffsets(OffsetsInitializer.latest()).setGroupId(groupId) .setValueOnlyDeserializer(appContext.getMessageDeserializer()) .setProperty("partition.discovery.interval.ms", "600000").build(); DataStream<String> dataStream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka-Source") .setParallelism(parallelism).name(this.operateName("source")); this.dataProcess(dataStream); env.execute(appContext.getTaskName()); } catch (Exception e) { System.out.println("ERROR msg:" + e.getMessage()); e.printStackTrace(); LOG.error("taskName:{} execute error.{} ", appContext.getTaskName(), e); throw new RuntimeException(appContext.getTaskName(), e); } } public MessageImport(AppContext appContext) { super(); this.appContext = appContext; } protected abstract void dataProcess(DataStream<String> dataStream); protected final String operateName(String functionDesc) { return this.appContext.getTaskName() + "-" + functionDesc; } }
优化后的代码:
private void execute() { try { System.setProperty("HADOOP_USER_NAME", "hadoop"); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(parallelism); // 启用Checkpointing并配置相关参数 env.enableCheckpointing(1000 * 60 * 3); // 每3分钟进行一次Checkpoint CheckpointConfig checkpointConfig = env.getCheckpointConfig(); checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); checkpointConfig.setCheckpointTimeout(1000 * 60 * 3); // Checkpoint超时时间为3分钟 checkpointConfig.setMinPauseBetweenCheckpoints(1000 * 60); // 最小等待间隔为1分钟 checkpointConfig.setMaxConcurrentCheckpoints(1); // 最大并发Checkpoint数量为1 checkpointConfig.enableUnalignedCheckpoints(); // 允许非对齐的Checkpoint checkpointConfig.setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 取消作业时保留Checkpoint // 配置Checkpoint存储位置为OSS(或其他支持的存储系统),需要确保URI格式正确 // 假设checkpointDir变量中存储的是OSS的URI,形如:oss://<bucket-name>/<path>/ String checkpointDir = appContext.getAppConf().getProperty("state_store") + "/" + appContext.getTaskName(); // 注意:这里需要确保checkpointDir是一个有效的OSS URI,或者根据实际的存储系统调整URI格式 // 如果使用OSS,请确保Flink已正确配置OSS文件系统连接器 checkpointConfig.setCheckpointStorage(checkpointDir); // 使用新API配置Checkpoint存储 // 不再需要设置StateBackend为FsStateBackend,因为CheckpointStorage已经涵盖了状态存储的配置 // env.setStateBackend(new FsStateBackend(checkpointDir)); // 这行代码是过时的,应该删除 // 额外的配置可以通过Configuration对象设置,但通常Checkpoint相关配置已经通过CheckpointConfig完成 // Configuration config = new Configuration(); // config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, true); // env.configure(config); // 这部分配置通常不是必需的,特别是关于Checkpoint的部分 // Kafka源配置和数据流处理逻辑保持不变... // ...(Kafka源配置、数据流处理和数据流执行等代码) env.execute(appContext.getTaskName()); } catch (Exception e) { System.out.println("ERROR msg:" + e.getMessage()); e.printStackTrace(); LOG.error("taskName:{} execute error.{}", appContext.getTaskName(), e); throw new RuntimeException(appContext.getTaskName() + " execute error", e); // 改进异常信息,使其更具描述性 } }
精准一次:
端到端精准一次:flink本身可以通过ck设置精准一次,源头必须做到可重放,目的端必须做到幂等(主键update等)
两阶段提交

 浙公网安备 33010602011771号
浙公网安备 33010602011771号