flink入门(一)——基本原理与应用场景
一、简介
1.简介
flink是一个开源的分布式流处理框架
优势:高性能处理、高度灵活window操作、有状态计算的Exactly-once等
详情简介,参考官网:https://flink.apache.org/flink-architecture.html
中文参考:https://flink.apache.org/zh/flink-architecture.html
flink组件介绍:
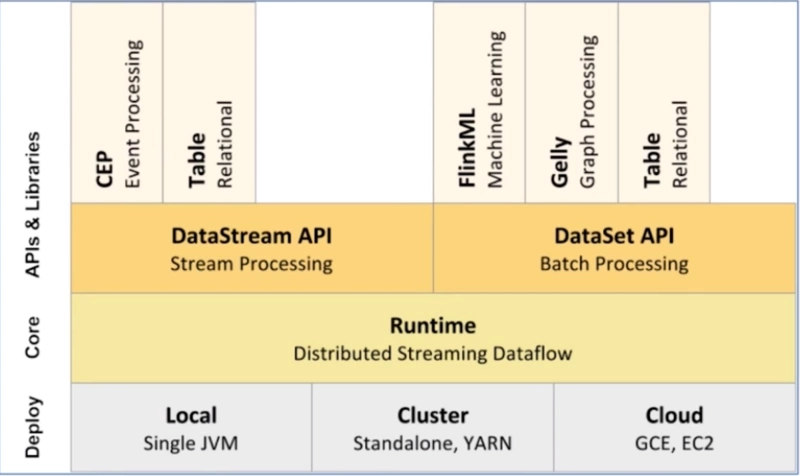
1)部署:支持本地、集群(支持yarn资源管理)、云
2)核心层:提供了计算的核心
3)API:提供了面向流处理的DataStream和面向批处理的DataSet
4)类库:支持Table/SQL
基本架构为 DataSource(数据源) -> Transfromation(算子处理数据) ->DataSink(数据目的)
2.框架对比:
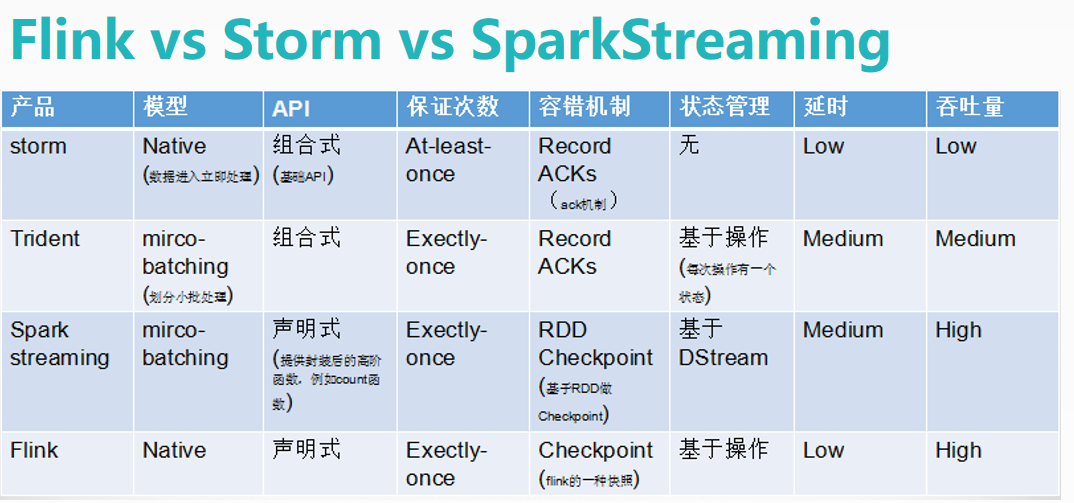
checkpoint就是检查点的意思,在重要位置设置检查点(快照),实现容错!https://blog.csdn.net/qq_39532946/article/details/78306809
2.传统lambda架构
使用两套系统保证结果正确性:

3.flink的核心特点
推荐特点核心讲解:https://blog.csdn.net/Android_xue/article/details/91809188
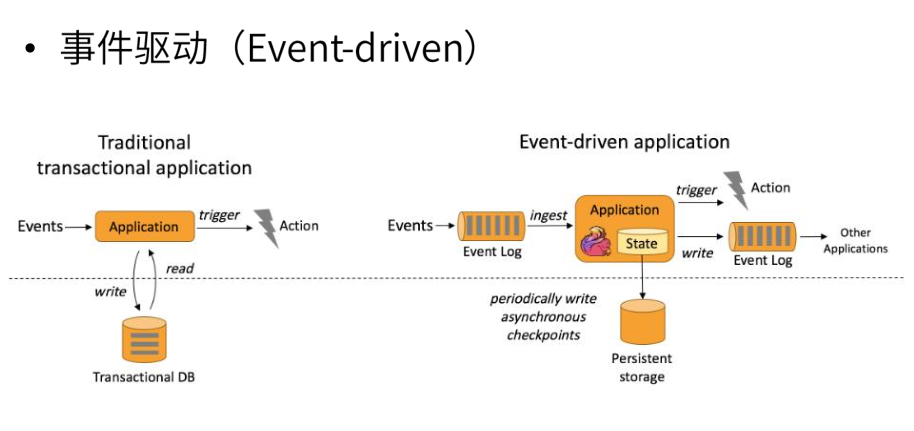
1)基于事件驱动
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。
2)基于流的世界观
处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
3)分层API

实战flink SQL使用较多,参考:https://blog.csdn.net/u013411339/article/details/93267838

 浙公网安备 33010602011771号
浙公网安备 33010602011771号