数据分析入门——pandas数据处理
1,处理重复数据
使用duplicated检测重复的行,返回一个series,如果不是第一次出现,也就是有重复行的时候,则为True:
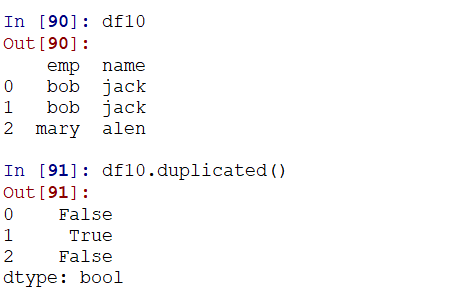
对应的,可以使用drop_duplicates来删除重复的行:

以上两个方法,都不能有重复的列!
2.map函数:列处理
map() 是一个Series的函数,DataFrame结构中没有map()。map()将一个自定义函数应用于Series结构中的每个元素(elements)。
传入一个拉姆达表达式:
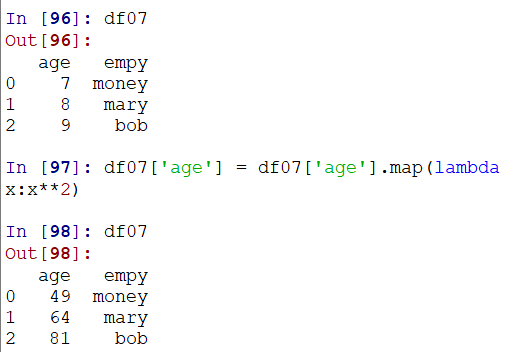
可以通过不存在的列名,利用map映射新增一列:(当然,此处map传入的可以是自定义函数,但不能是类似sum这样的UDTF聚合函数,而必须是UDF函数)

其他与apply、applymap等的区别,参考:https://blog.csdn.net/maymay_/article/details/80229053
3.rename函数:替换索引
使用renname函数替换行索引:(列索引通过columns控制同理,使用一个dict进行映射,包含映射的将会进行映射!)

更加简单粗暴的方法可以直接通过df.index = 赋值操作来进行!
4.异常值检测和过滤
通过describe查看统计性数值:count——数据量有几个数,mean是平均值,std表示标准差(波动),min/max最小/最大值,中间百分比则是取最小最大值之间的25%、50%等的值

通过std求每一列的标准差:(可以通过axis来控制轴)
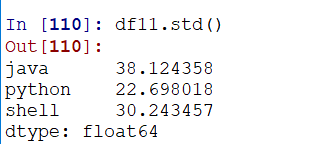
通过标准差,借助any()函数(any函数一真即真,有一个True则返回True)来实现过滤
例如检测大于两倍标准差的:(这里通过控制轴,来取得每个同学而不是每个科目的过滤值)
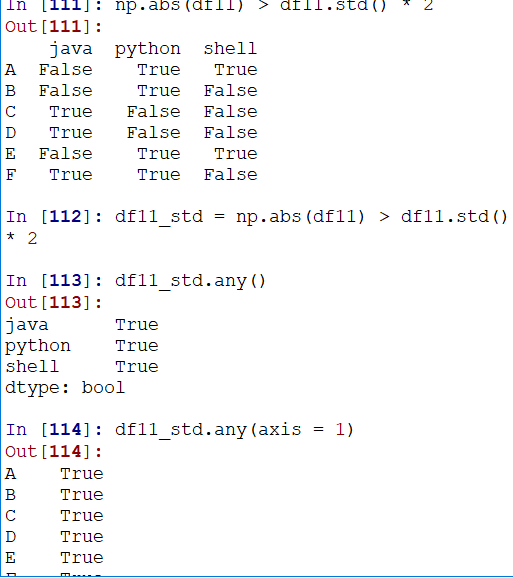
顺势,就可以过滤数据了:(通过boolean提取数据,参考:https://www.jianshu.com/p/b1be2eccd029)

5.排序抽样——take函数
利用随机生成的顺序,结合take取数据:

使用random.randint可以实现随机抽样的效果
6.数据聚合(重点)
数据聚合通常是数据处理的最后一步,一般是要使每个数组产生唯一的值:
通常分类涉及到的是:分组—>函数处理——>合并
使用groupby分组:

打印发现是一个GroupBy的对象,使用groups属性,可以查看分成了哪几个组:
GroupBy对象的更多操作,参考:https://www.jianshu.com/p/42f1d2909bb6

可以通过筛选的方式,快速求出平均值等操作:(返回的是一个Series)

通过merge,可以整合平均值到原df中去:
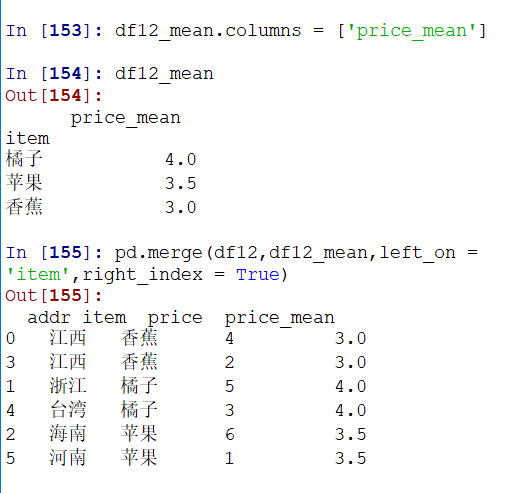
通过其他列分组,同理:(如果不选择列,则会对所有能操作的列进行操作,返回一个df结果)
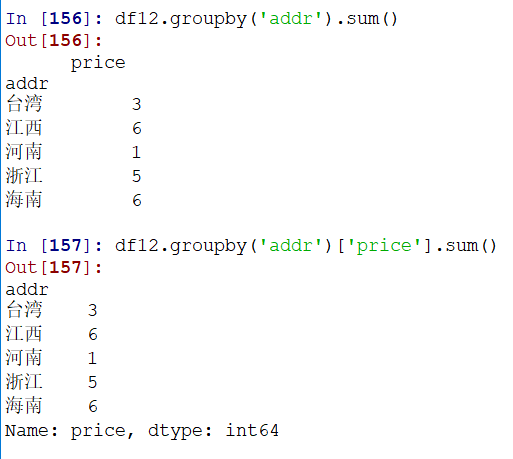
多列分组,同理:

7.高级数据聚合
可以通过transform和apply实现相同功能,并且,apply可以传入一个匿名函数
apply和map的区别,参考:https://blog.csdn.net/weixin_39791387/article/details/81487549
https://www.jianshu.com/p/c384ac86c4a6
map() 方法是pandas.series.map()方法, 对DF中的元素级别的操作, 可以对df的某列或某多列, 可以参考文档
apply(func) 是DF的属性, 对DF中的行数据或列数据应用func操作.
applymap(func) 也是DF的属性, 对整个DF所有元素应用func操作
————————————————
版权声明:本文为CSDN博主「诸葛老刘」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39791387/article/details/81487549


 浙公网安备 33010602011771号
浙公网安备 33010602011771号