数据分析入门——pandas之数据合并
主要分为:级联:pd.concat、pd.append
合并:pd.merge
一、numpy级联的回顾
详细参考numpy章节
https://www.cnblogs.com/jiangbei/p/11287238.html

二、pd中concat函数
1.简单级联
和numpy的级联类似,默认增加行数,通过axis(默认为0)来控制
在pandas中,如果行 和 列不一致,但是shape相同,会级联成一个更大的df,不对应的值会填充NaN。



并且,级联可以重复:

可以通过ignore_index进行索引重排序(变成0开始的索引):

通过keys创建多层索引:(可以使得合并之后的数据更加清晰)

2.不匹配级联
不匹配级联是指两个df的行或者列索引不一致
1)外连接,不对齐的补NaN,(默认模式)

2)内连接,通过join参数控制:

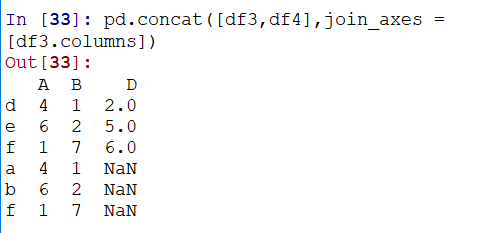
3)指令连接的轴,通过join_axis控制:
这样就只保留了Join_axis的列:
3)使用append()方法进行追加
这种使用和concat是差不多的,不过可以不通过pd来操作了:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号