数据分析入门——pandas之DataFrame数据丢失
一、数据丢失分类
1)nd中分为两种:None和np.nan(NaN)
其中,None是python中的对象,是一个object;而nan是一个float类型
两种不同的类型,运算速度也是不同的
2)pandas中两种都视作NaN(np.nan)
二、数据丢失处理
通过控制columns来创建有NaN的数据:

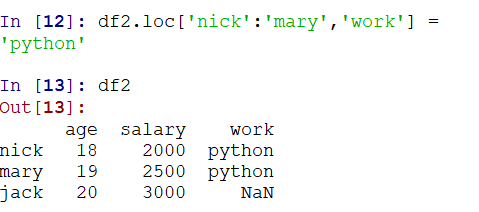
通过loc切片赋值来处理部分NaN数据:
1.与空相关的方法
检测:
isnull()和notnull()

如何检测df中哪些行中存在空行?
df.isnull().any(axis=1): True行中存在空 False行中不存在空(any的字面意思就是该行有一个为True即为True)
df.notnull().all(axis=1): False行中存在空 True行中不存在空(all与上面any类似,也就是逻辑里面的与操作了)
过滤:
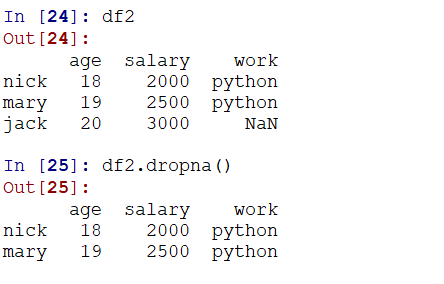
dropna() --可以选择过滤行还是列(默认为行,也就是axis = 0,有空行则删除)
可以通过how参数来控制,是any还是all(存在就剔除还是全部才剔除)
dropna(how = 'all')
这里重复一下,轴的概念:
根据stackoverflow答主解释,axis=0指的是逐行,轴是Index;axis=1指的是逐列,轴是columns。(index (0), columns (1))
根据结果:
mean(axis=0)计算的是每一列平均值,
mean(axis=1)计算的是每一行平均值。(轴是columns)
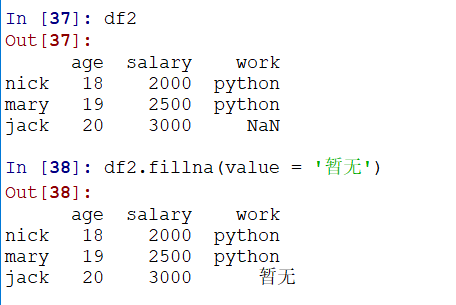
填充:(可以填充Series/DataFrame)
fillna(value = xx)
对所有的na都进行填充
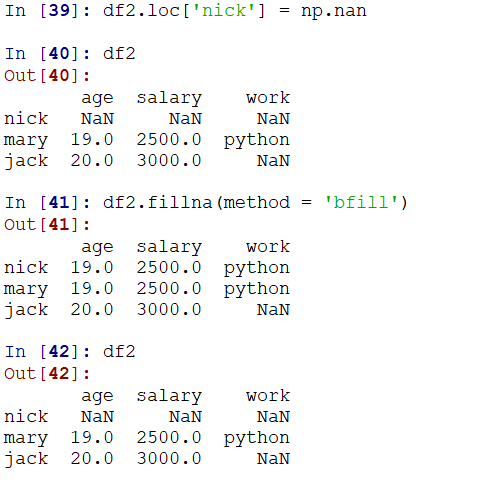
可以通过method选择向后填充(bfill,使用后一个的值进行填充,文档有详细参数解释),或者向前(ffill)填充
注意,此处是返回一个填充后的副本,本身并没有改变,可以通过inplace参数来控制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号