数据分析入门——pandas之DataFrame基本概念
一、介绍
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
可以看作是Series的二维拓展,但是df有行列索引:index、column
推荐参考:https://www.jianshu.com/p/c534e83d2f4b
二、快速入门
1.打开csv

发现报错,原因是路径中\User的\u和转义符号冲突了,我们使用字符串中的知识,添加r开头表示不转义即可:
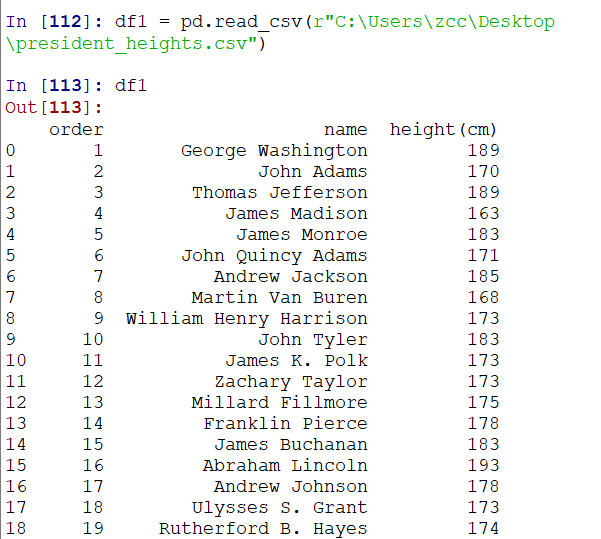
它包含的是行列索引和值values,value对应的就是二维的ndarray了
2.创建df
1.通过字典来创建df

可以通过index属性来控制索引,column同理:(在创建以后通过df.index = []的属性赋值也可以实现控制索引的)

2.可以通过列表来创建,给定ndarray,再给定Index和columns来构造df
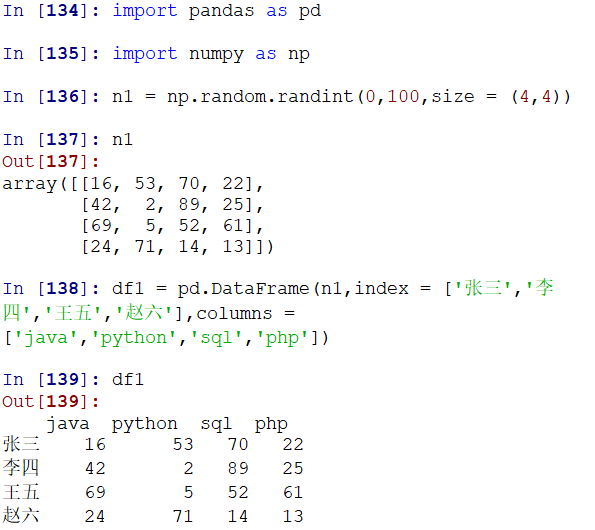
参考:https://www.yiibai.com/pandas/python_pandas_dataframe.html
3.df的索引
列索引:
通过列的索引检索,可以返回对应的列,也就是之前的Series

行索引:
使用loc或者iloc进行索引(其中,前者是显式索引,需要指定索引的值,后者是隐式索引,已过时的ix方法不再展开)
使用loc检索出一行,发现结果也是Series:

需要检索多行时,需要两个中括号(并且返回的也是DataFrame):

并且loc是支持切片(左右的闭区间)的:(支持的是行切片,如果切片范围不存在,则返回空数据,而不是报错)
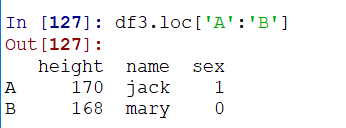
隐式索引是类似的:(但是iloc的切片是左闭右开,与上面稍有不符合)

//存在部分bug:汉字索引有个别索引不生效,无法检索
元素索引:
可以通过线检索出某一列,再操作这个列Series(注意使用loc的推荐方法):

其他变通形式同理:

上面这个简写就变成:这就是行索引的变通形式

4)DataFrame的数据查看
1.通过head()、tail()查看头几行或者尾几行(默认n = 5):

2.通过a.index ; a.columns ; a.values 即可查看对应属性
3.a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
三、DataFrame的运算
1.DF之间的运算
构建的df1、df2如下:(用于后续计算)
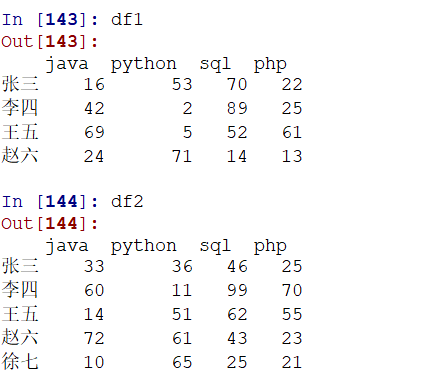
其实总结下来就是,行列索引相同的(也就是需要对齐再相加,无法对齐时使用NaN对齐,列会取并集,行值不对齐时使用默认NaN),进行计算,没有的全部用空进行计算(参考https://blog.csdn.net/weixin_34208283/article/details/86005233)
https://blog.csdn.net/weixin_33966095/article/details/88446784

需要避免NaN值可以使用pandas的add方法的fill_value来控制:

2.DF与Series之间的运算
直接运算,发现结果并不如人意:

提取行发现可以计算:

这也就是Series中的广播规则,默认情况下是s的index和df的columns进行对齐的,第二个对齐后的操作,看数据知道是广播成了四行与df对齐,可以通过 axis来进行广播控制(0表示在列上广播,1表示在行上广播)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号