数据分析入门——pandas之Series
一、介绍
Pandas是一个开源的,BSD许可的库(基于numpy),为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
官方中文文档:https://www.pypandas.cn/docs/
本次演示使用数据来自github:https://github.com/jakevdp/PythonDataScienceHandbook/tree/master/notebooks/data
二、快速入门
1.导入

2.重点数据结构
主要是series和dataframe
所以一般情况下我们导入的是数据分析的三剑客:
numpy Series DataFrame:(如果只导入pd,那就正常使用pd.Series即可了)
from pandas import Series,DataFrame
三、Series
Series是Pandas中的一维数据结构,类似于Python中的列表和Numpy中的Ndarray,不同之处在于:Series是一维的,能存储不同类型的数据,有一组索引与元素对应。也就是加了索引的一维数据结构(索引不一定是0 1 2 3的数字)

1.创建
1)通过列表或者numpy数组进行创建,默认索引是0 1 2 3这样的整数索引。示例如上图
想要指定索引,可以设置index参数:(创建的时候指定也是可以的)
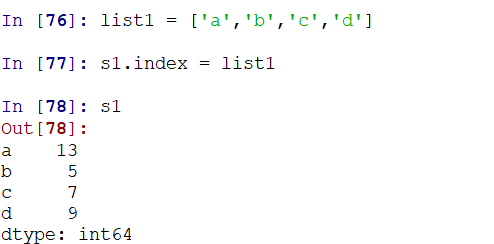
特别地,使用ndarray创建的series是引用,对series的改变会影响ndarray
2)由字典创建
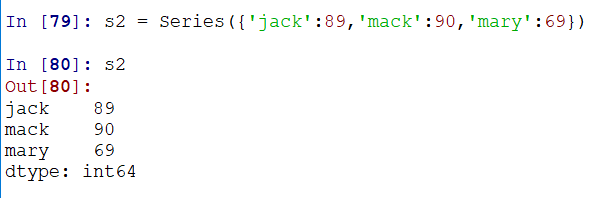
Series主要分为index、values两块
2.索引和切片
1).使用index作为索引值(不推荐)

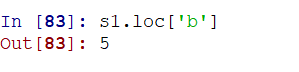
2)使用升级为Series之后的loc()函数(推荐)
3)使用隐式索引(不显式指定索引的内容值,通过类似ndarray的索引风格取数据)

4)切片,可以直接[]或者loc形式

3.Series基本概念
1)常用属性:index、values、shape(一维的,所以只能是一个元素的元组)、size
2)可以通过head()、tail()等查看头部和尾部数据(类似linux的命令),只看前5个或者后5个
3)索引没有对应的值时,值会出现NaN,也就是数据缺失的情况,在np中使用np.nan表示这个空值,python中就是None表示了
4)可以使用 isnull()、notnull()来检测空值:
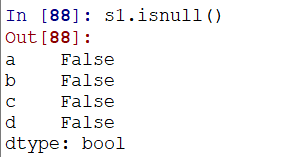
可以通过notnull()等进行空数据过滤:
s2 = s.notnull() # 以下取出的便是为True的非空数据 s[s2]
5)每个Series都有一个name属性,可以在DataFrame中进行区分,在df中,也就相当于列名
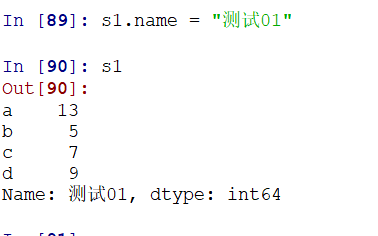
6)Series运算
可以正常的进行加减运算,其中None值不会参与计算,而ndarray值为None时为报错,为np.nan时计算结果为nan


或者通过s1.add(10,fill_value= 0)等形式来控制NaN的默认值
两个Series之间也可以运算,不对齐的部分(也就是索引不相等的部分),补充NaN

要保留index不对齐的部分,可以使用add()方法:,通过fill_value


 浙公网安备 33010602011771号
浙公网安备 33010602011771号