datax实战
一、全量同步
1.简单字段同步
本文以mysql -> mysql为示例:
本次测试的表为mysql的系统库-sakila中的actor表,由于不支持目的端自动建表,此处预先建立目的表:
CREATE TABLE `actor_copy` ( `actor_id` smallint(5) unsigned NOT NULL AUTO_INCREMENT, `first_name` varchar(45) NOT NULL, `last_name` varchar(45) NOT NULL, `last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`actor_id`), KEY `idx_actor_last_name` (`last_name`) ) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8;
通过官方快速开始提供的命令,可以查看配置模板:
python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
python datax.py -r streamreader -w streamwriter
打开dataX的mysqlreader以及mysqlwriter文档,编写JSON配置文件:(此处经过试验,即使是自增主键,同样需要配置,否则会报输入输出不匹配的错),加上JSON配置文件的x权限:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "Zcc170821#",
"column": [
"actor_id",
"first_name",
"last_name",
"last_update"
],
"splitPk": "actor_id",
"connection": [
{
"table": [
"actor"
],
"jdbcUrl": [
"jdbc:mysql://192.168.19.129:3306/sakila"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "Zcc170821#",
"column": [
"actor_id",
"first_name",
"last_name",
"last_update"
],
"preSql": [
"truncate table actor_copy"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://192.168.19.129:3306/sakila",
"table": [
"actor_copy"
]
}
]
}
}
}
]
}
}
这样,单表的最基本全量同步就完成了!
通过python 命令运行即可:
python datax.py ../job/mysqltest.json
2.增加常量与插入时间字段
原表正常字段,目标表多出两列:来源部门,插入时间。json配置如下:
常量使用单引号,时间暂时未摸索到变量如何使用(以下通过启动脚本已更新方式),通过时间函数实现
{ "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root", "column": [ "actor_id", "first_name", "last_name", "last_update", "'自动生成'", "NOW()" ], "splitPk": "actor_id", "connection": [ { "table": [ "actor" ], "jdbcUrl": [ "jdbc:mysql://hadoop01:3306/sakila" ] } ] } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "root", "password": "root", "column": [ "actor_id", "first_name", "last_name", "last_update", "src", "load_time" ], "preSql": [ "truncate table actor_copy" ], "connection": [ { "jdbcUrl": "jdbc:mysql://hadoop01:3306/sakila", "table": [ "actor_copy" ] } ] } } } ] } }
2020.1.11,更新通过启动脚本控制时间戳:
首先Json配置更改为变量:(注意变量有个单引号!)
{ "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "root", "column": [ "actor_id", "first_name", "last_name", "last_update", "'${src}'", "'${systime}'" ], "splitPk": "actor_id", "connection": [ { "table": [ "actor" ], "jdbcUrl": [ "jdbc:mysql://hadoop01:3306/sakila" ] } ] } }, "writer": { "name": "mysqlwriter", "parameter": { "writeMode": "insert", "username": "root", "password": "root", "column": [ "actor_id", "first_name", "last_name", "last_update", "src", "load_time" ], "preSql": [ "truncate table actor_copy" ], "connection": [ { "jdbcUrl": "jdbc:mysql://hadoop01:3306/sakila", "table": [ "actor_copy" ] } ] } } } ] } }
在datax的srcipts文件下新建一个启动脚本:
#coding:UTF-8
from datetime import datetime
import os
import sys
configFilePath = sys.argv[1]
src = '自动生成'
currentTime = format(datetime.now(), '%Y-%m-%d %H:%M:%S')
script2execute = "python /opt/datax/bin/datax.py {0} -p \"-Dsrc='{1}' -Dsystime='{2}'\"".format( configFilePath, src, currentTime)
os.system(script2execute)
在srcipts下的启动命令为:
python ./datax_start.py '/opt/datax/job/mysql_actor_copy_arg.json'
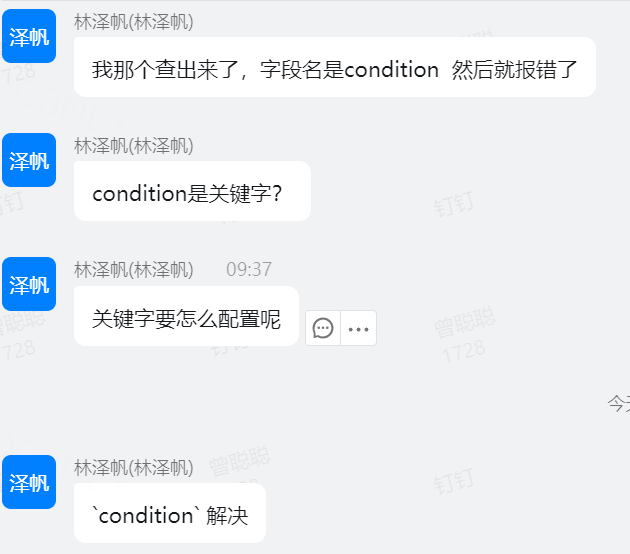
补充:如果是关键字冲突:
二、增量同步
增量同步的核心思路是时间戳,需要同步的表中要有Update_time字段:
参考实现:https://www.jianshu.com/p/34b3a084d7d8
https://blog.csdn.net/quadimodo/article/details/82186788
增量数据和全量数据如何合并?使用full join
https://blog.csdn.net/kx306_csdn/article/details/89508323
当然如果有例如更新时间,修改时间字段,可以直接将增量表INTO入昨日全量,然后根据ID去重,取最新时间也是可以的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号