sqoop数据迁移
3.1 概述
sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库
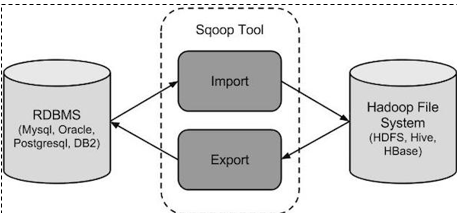
3.2 工作机制
将导入或导出命令翻译成mapreduce程序来实现
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
3.3 sqoop实战及原理
3.3.1 sqoop安装
安装sqoop的前提是已经具备java和hadoop的环境
1、下载并解压
最新版下载地址http://ftp.wayne.edu/apache/sqoop/1.4.6/
2、修改配置文件
$ cd $SQOOP_HOME/conf
$ mv sqoop-env-template.sh sqoop-env.sh
打开sqoop-env.sh并编辑下面几行:
export HADOOP_COMMON_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HADOOP_MAPRED_HOME=/home/hadoop/apps/hadoop-2.6.1/
export HIVE_HOME=/home/hadoop/apps/hive-1.2.1
3、加入mysql的jdbc驱动包
cp ~/app/hive/lib/mysql-connector-java-5.1.28.jar $SQOOP_HOME/lib/
4、验证启动
$ cd $SQOOP_HOME/bin
$ sqoop-version
预期的输出:
15/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
Sqoop 1.4.6 git commit id 5b34accaca7de251fc91161733f906af2eddbe83
Compiled by abe on Fri Aug 1 11:19:26 PDT 2015
到这里,整个Sqoop安装工作完成。
3.4 Sqoop的数据导入
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据(或者Avro、sequence文件等二进制数据)
3.4.1 语法
下面的语法用于将数据导入HDFS。
|
$ sqoop import (generic-args) (import-args) |
3.4.2 示例
表数据
在mysql中有一个库userdb中三个表:emp, emp_add和emp_contact
表emp:
|
id |
name |
deg |
salary |
dept |
|
1201 |
gopal |
manager |
50,000 |
TP |
|
1202 |
manisha |
Proof reader |
50,000 |
TP |
|
1203 |
khalil |
php dev |
30,000 |
AC |
|
1204 |
prasanth |
php dev |
30,000 |
AC |
|
1205 |
kranthi |
admin |
20,000 |
TP |
表emp_add:
|
id |
hno |
street |
city |
|
1201 |
288A |
vgiri |
jublee |
|
1202 |
108I |
aoc |
sec-bad |
|
1203 |
144Z |
pgutta |
hyd |
|
1204 |
78B |
old city |
sec-bad |
|
1205 |
720X |
hitec |
sec-bad |
表emp_conn:
|
id |
phno |
|
|
1201 |
2356742 |
gopal@tp.com |
|
1202 |
1661663 |
manisha@tp.com |
|
1203 |
8887776 |
khalil@ac.com |
|
1204 |
9988774 |
prasanth@ac.com |
|
1205 |
1231231 |
kranthi@tp.com |
导入表表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
|
$bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp --m 1 |
如果成功执行,那么会得到下面的输出。
|
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar ----------------------------------------------------- O mapreduce.Job: map 0% reduce 0% 14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0% 14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully ----------------------------------------------------- ----------------------------------------------------- 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds (0.8165 bytes/sec) 14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records. |
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-00000 |
emp表的数据和字段之间用逗号(,)表示。
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP |
导入关系表到HIVE
|
bin/sqoop import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --hive-import --m 1 |
导入到HDFS指定目录
在导入表数据到HDFS使用Sqoop导入工具,我们可以指定目标目录。
以下是指定目标目录选项的Sqoop导入命令的语法。
|
--target-dir <new or exist directory in HDFS> |
下面的命令是用来导入emp_add表数据到'/queryresult'目录。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --target-dir /queryresult \ --table emp --m 1 |
下面的命令是用来验证 /queryresult 目录中 emp_add表导入的数据形式。
|
$HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-* |
它会用逗号(,)分隔emp_add表的数据和字段。
|
1201, 288A, vgiri, jublee 1202, 108I, aoc, sec-bad 1203, 144Z, pgutta, hyd 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
导入表数据子集
我们可以导入表的使用Sqoop导入工具,"where"子句的一个子集。它执行在各自的数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
where子句的语法如下。
|
--where <condition> |
下面的命令用来导入emp_add表数据的子集。子集查询检索员工ID和地址,居住城市为:Secunderabad
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --where "city ='sec-bad'" \ --target-dir /wherequery \ --table emp_add --m 1 |
下面的命令用来验证数据从emp_add表导入/wherequery目录
|
$HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-* |
它用逗号(,)分隔 emp_add表数据和字段。
|
1202, 108I, aoc, sec-bad 1204, 78B, oldcity, sec-bad 1205, 720C, hitech, sec-bad |
增量导入
增量导入是仅导入新添加的表中的行的技术。
它需要添加‘incremental’, ‘check-column’, 和 ‘last-value’选项来执行增量导入。
下面的语法用于Sqoop导入命令增量选项。
|
--incremental <mode> --check-column <column name> --last value <last check column value>
|
假设新添加的数据转换成emp表如下:
1206, satish p, grp des, 20000, GR
下面的命令用于在EMP表执行增量导入。
|
bin/sqoop import \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp --m 1 \ --incremental append \ --check-column id \ --last-value 1205 |
以下命令用于从emp表导入HDFS emp/ 目录的数据验证。
|
$ $HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-* 它用逗号(,)分隔 emp_add表数据和字段。 1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
下面的命令是从表emp 用来查看修改或新添加的行
|
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1 这表示新添加的行用逗号(,)分隔emp表的字段。 1206, satish p, grp des, 20000, GR |
3.5 Sqoop的数据导出
将数据从HDFS导出到RDBMS数据库
导出前,目标表必须存在于目标数据库中。
u 默认操作是从将文件中的数据使用INSERT语句插入到表中
u 更新模式下,是生成UPDATE语句更新表数据
语法
以下是export命令语法。
|
$ sqoop export (generic-args) (export-args) |
示例
数据是在HDFS 中“EMP/”目录的emp_data文件中。所述emp_data如下:
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
1、首先需要手动创建mysql中的目标表
|
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10)); |
2、然后执行导出命令
|
bin/sqoop export \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table emp2 \ --export-dir /user/hadoop/emp/ |
3、验证表mysql命令行。
|
mysql>select * from employee; 如果给定的数据存储成功,那么可以找到数据在如下的employee表。 +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+ |
3.6 Sqoop作业
注:Sqoop作业——将事先定义好的数据导入导出任务按照指定流程运行
语法
以下是创建Sqoop作业的语法。
|
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
|
创建作业(--create)
在这里,我们创建一个名为myjob,这可以从RDBMS表的数据导入到HDFS作业。
|
bin/sqoop job --create myimportjob -- import --connect jdbc:mysql://hdp-node-01:3306/test --username root --password root --table emp --m 1 |
该命令创建了一个从db库的employee表导入到HDFS文件的作业。
验证作业 (--list)
‘--list’ 参数是用来验证保存的作业。下面的命令用来验证保存Sqoop作业的列表。
$ sqoop job --list
它显示了保存作业列表。
Available jobs:
myjob
检查作业(--show)
‘--show’ 参数用于检查或验证特定的工作,及其详细信息。以下命令和样本输出用来验证一个名为myjob的作业。
$ sqoop job --show myjob
它显示了工具和它们的选择,这是使用在myjob中作业情况。
|
Job: myjob Tool: import Options: ---------------------------- direct.import = true codegen.input.delimiters.record = 0 hdfs.append.dir = false db.table = employee ... incremental.last.value = 1206 ...
|
执行作业 (--exec)
‘--exec’ 选项用于执行保存的作业。下面的命令用于执行保存的作业称为myjob。
|
$ sqoop job --exec myjob 它会显示下面的输出。 10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation ... |
3.7 Sqoop的原理
概述
Sqoop的原理其实就是将导入导出命令转化为mapreduce程序来执行,sqoop在接收到命令后,都要生成mapreduce程序
使用sqoop的代码生成工具可以方便查看到sqoop所生成的java代码,并可在此基础之上进行深入定制开发
代码定制
以下是Sqoop代码生成命令的语法:
|
$ sqoop-codegen (generic-args) (codegen-args) $ sqoop-codegen (generic-args) (codegen-args) |
示例:以USERDB数据库中的表emp来生成Java代码为例。
下面的命令用来生成导入
|
$ sqoop-codegen \ --import --connect jdbc:mysql://localhost/userdb \ --username root \ --table emp |
如果命令成功执行,那么它就会产生如下的输出。
|
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5 14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation ………………. 14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or overrides a deprecated API. Note: Recompile with -Xlint:deprecation for details. 14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jar |
验证: 查看输出目录下的文件
|
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/ $ ls emp.class emp.jar emp.java
|
如果想做深入定制导出,则可修改上述代码文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号