分布式事务与Seate框架(3)——Seata的AT模式实现原理
前言
在上两篇博文(分布式事务与Seate框架(1)——分布式事务理论、分布式事务与Seate框架(2)——Seata实践)中已经介绍并实践过Seata AT模式,这里一些例子与概念来自这两篇(特别是第一篇理论部分),如果有不懂的小伙伴可以先看看,这里主要是讲解Seata AT模式的实现原理。
又好久没有记录博文了,这篇其实是很早之前就记录好了的,但是一直没时间去写出来,今天发出来算是再次对Seata分布式有个加深!
一、AT模式介绍
同样地,还是得先复习下分布式事务的相关理论部分:AT模式是Seata最主推的分布式事务且基于XA演进而来的解决方案,主要有三个角色:TM、RM和TC,其中TM和RM作为Seata的客户端和业务集成,TC作为Seata服务器独立部署。TM向TC注册一个全局事务,并生成全局唯一的XID;在AT模式下,数据库资源被当做RM,访问RM时,Seata会对请求进行拦截;每个本地事务提交时,RM会向TC(Transaction Coordinator,事务协调器)注册一个分支事务。
从三个角色TM、RM和TC的角度来记录具体的流程的话,可以总结如下:
- TM向TC注册全局事务,并生成全局唯一XID;
- RM向TC注册分支事务,并将其纳入到该XID对应的全局事务范围。
- RM向TC汇报资源的准备状态
- TC汇总所有事务参与者的执行状态,决定分布式事务全部回滚还是提交
- TC通知所有的RM提交/回滚事务
从具体的微服务角度总结,假设分别有三个:MicroService-1, MicroService-2, MicroService-3,流程图如下:

二、Seata AT模式的实现原理
1. AT模式的第一阶段实现
解析业务SQL,更新业务数据,保存更新前后镜像到undo_log。在业务操作数据库流程中,Seata会基于数据源代理(0.9以后支持自动代理)对原执行SQL进行解析。之后通过本地事务的ACID特性,将这两步操作(保存业务数据前后镜像到undo_log, 更新业务数据)在本地事务中进行提交。
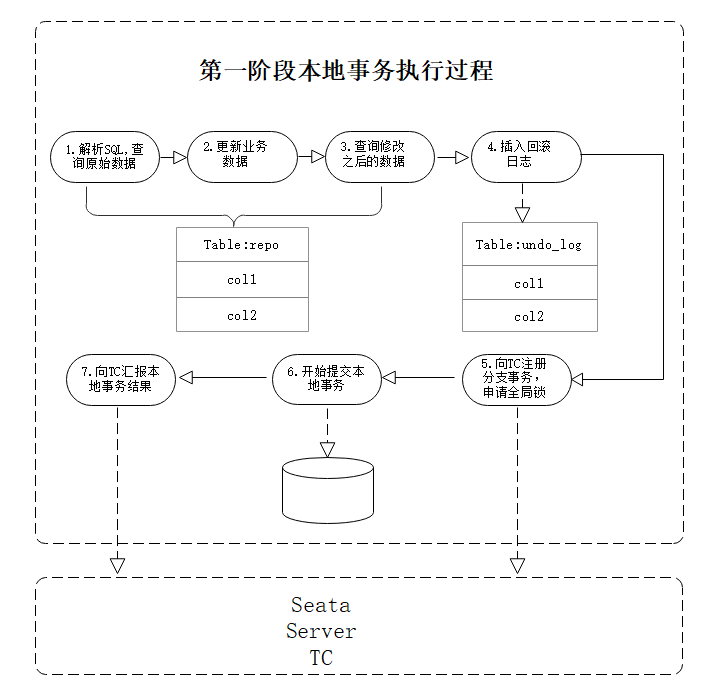
比如(引用第二篇博文中的例子),我们对库存表库存进行减一,执行:
UPDATE repo SET amount=amount-1 WHERE id=1
则第一阶段需要做的步骤:
(1)通过DataSourceProxy对业务SQL进行解析,得到SQL的表、WHEER条件等,之后通过查询修改之前的数据:
SELECT id, name, amount, price FROM repo WHERE id=1;
这样就得到了修改之前的镜像,此时amount=100;
(2)执行更新业务:
即执行update语句,此时amount=99;
(3)查询修改之后的数据镜像,此时是通过第二步获取到的主键查询到修改之后的数据的
SELECT id, name, amount, price FROM repo WHERE id=1;
这样就有了修改之后的数据镜像了。
(4)插入回滚日志
有了修改前后的业务镜像数据之后,可以将业务镜像数据与业务相关的SQL信息构造成一条undo_log记录,插入undo_log表中:
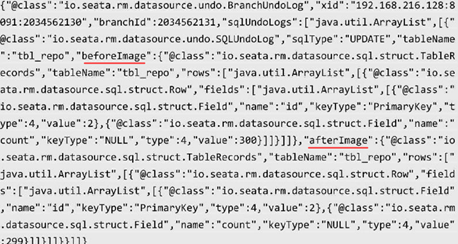
(如果要看到undo_log记录,则需要在debug模式下或者日志打印输出,否则事物回结束后会删除该记录)
(5)向TC注册分支事务,并且申请关于id=1记录的全局锁
(6)本地事务开始提交,将undo_log数据插入与更新业务数据一并提交(只有释放全局锁)
(7)将本地事务提交的结果告诉TC。
从AT模式的第一阶段来看,不同于XA模式的主要有以下几点(或者说优势):
- 分支事务在第一阶段提交完成之后就马上释放本地事务锁定的资源。而XA模式一般是在锁定资源的持续到第二阶段的提交或者回滚后才释放资源。
- AT模式第一阶段就释放了资源,这样就会让AT模式提升了分布式事务处理效率;
- 之所以在第一阶段就释放了资源,这是因为AT模式下,在第一阶段就记录了undo_log回滚日志,所以不怕第二阶段出现异常。
2.AT模式第二阶段的原理分析
TC服务接收到事务分支的事务状态汇报之后,决定对全局事务进行提交或者回滚,这就是第二阶段。
2.1.事务提交
如果在第一阶段所有的分支事务已经提交,则TC决定全局事务提交,此时只需要清理UNDO_LOG日志即可,相比较XA模式,不需要TC触发所有分支事务的提交。
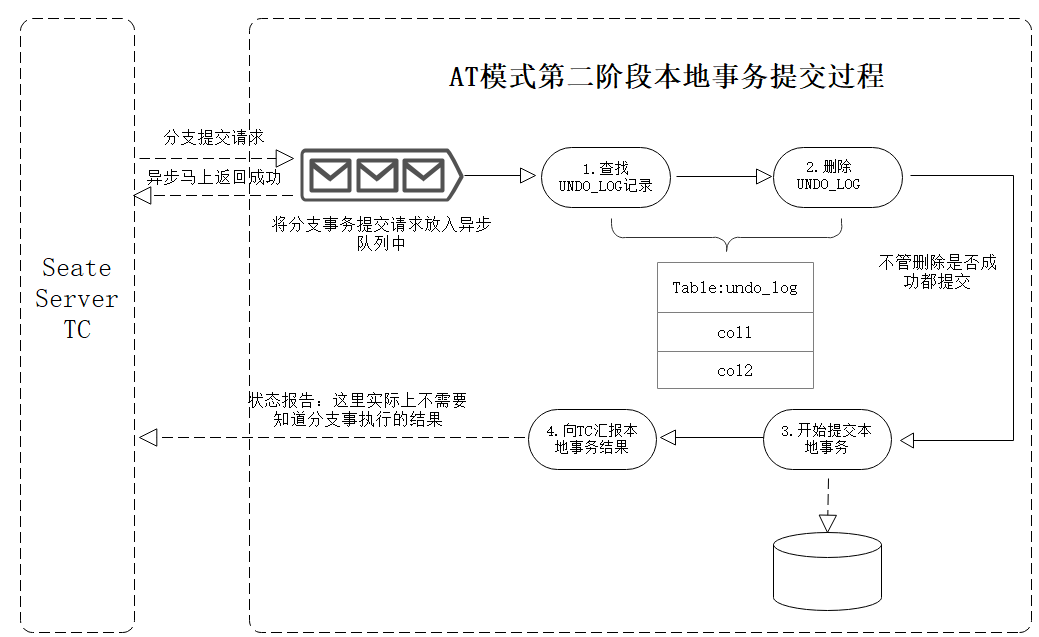
具体的流程为:
(1) 分支事务收到TC的提交请求之后放入异步队列中,马上返回提交成功的结果;这里不需要同步返回的原因是:TC不需要知道分支事务的结果,因为仅仅只是一步删除UNDO_LOG记录的操作,即使不成功也不会结果造成影响,所以采用异步是有效的方式。
(2) 从异步队列中执行分支提交请求,清理undo_log日志,这里并不需要分支事务的提交了,因为第一阶段中已经提交过了。
理解起来就是:AT模式下的全局事务的提交只需要清理UNDO_LOG记录就行,不需要管分支(本地)事务的提交结果!
2.2.事务回滚
在第一阶段的分支事务中任何一个分支事务执行失败,都会进入全局事务回滚流程,显而易见全局事务的回滚主要是依赖UNDO_LOG中的记录进行补偿的。
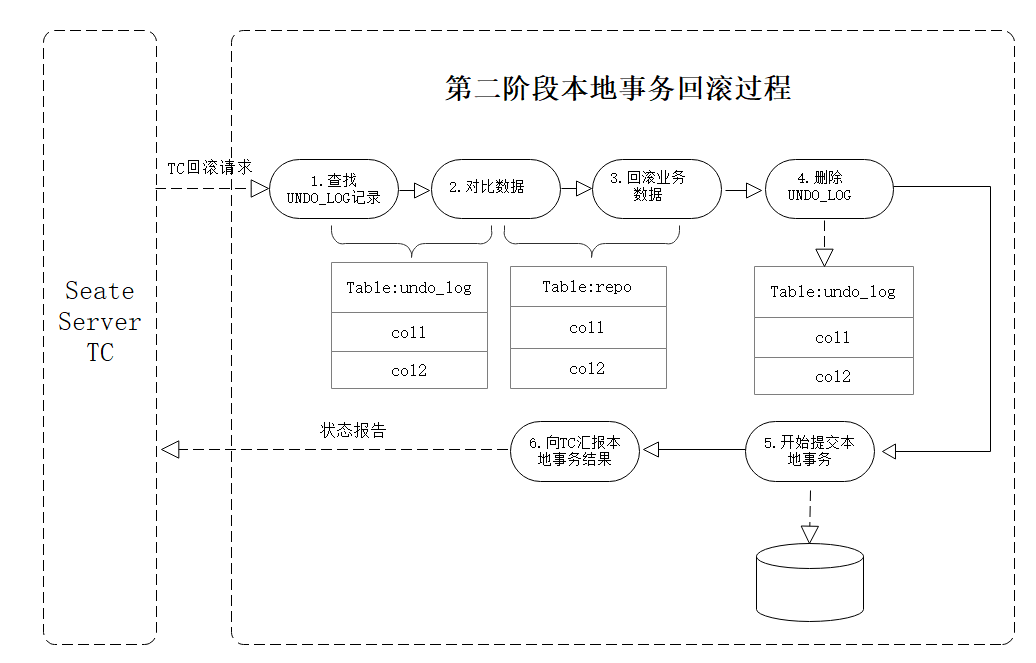
具体的流程如下:
接收到TC的回滚请求后,开启本地事务用来执行回滚操作
(1)本地事务分支开始进行对查找UNDO_LOG记录
通过XID+branch ID查到UNDO_LOG记录;
(2)数据校验(对比更新后镜像数据与当前数据)
拿到rollback_for中afterImage镜像数据与当前业务表中数据比较,不同的话,比如afterImage镜像数据拿出的amount理论上为99,但是实际上amount=98,则说明已经被当前全局事务外的某个操作做了修改(实际上由于全局锁的存在,并不会存在其他全局事务对业务数据进行更新),那么事务不进行回滚。
(3)第二步中对比结果是相等的话,就采用beforeImage和SQL的相关信息进行回滚,即:
UPDATE rep SET acoumt=100 WHERE id=1
(4)删除UNDO_LOG记录
(5)提交本地事务
(6)将本地事务的回滚执行结果报告给TC
3.AT模式下事务的隔离性保证
在AT模式下,多个全局事务操作同一张表时,它的事务隔离性保证是基于全局锁来实现的。
(1)写隔离
在第一阶段本地事务提交之前,必须确保拿到全局锁,如果拿不到全局锁则一直等待尝试,超出最大尝试次数则放弃全局锁的获取,并回滚释放本地锁(在本地事务开始之前就获到本地锁,这里的本地锁概念是数据库锁,比如对某行记录的行锁)
(2)读隔离
数据库不设置事务隔离级别下发生三种情况(相当于复习下数据库隔离级别相关理论知识):
脏读:脏读是指一个事务在处理数据的过程中,读取到另一个未提交事务的数据。
不可重复读:不可重复读是指对于数据库中的某个数据,一个事务范围内的多次查询却返回了不同的结果,这是由于在查询过程中,数据被另外一个事务修改并提交了。
幻读:一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为幻读。也就是第一个事务读取的时候发现其他事务插入(或删除)的事务,就跟幻觉一样。
幻读跟不可重复读都是读取了另一个事务提交的结果,而不可重复读的重点是修改,幻读的重点在于新增或者删除。
在数据库本地事务隔离级别为RR或者以上时,Seata AT事务模式的默认全局隔离级别是Read Uncommit,在这种隔离级别下,所有事务都可以看到其它未提交事物的执行结果产生脏读,这在最终一致性的事务模型是被允许的,并且大部分是分布式事务是接受脏读的。
__EOF__

本文链接:https://www.cnblogs.com/jian0110/p/14925087.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix