四种途径提高RabbitMQ传输数据的可靠性(二)
前言
上一篇四种途径提高RabbitMQ传输消息数据的可靠性(一)已经介绍了两种方式提高数据可靠性传输的方法,本篇针对上一篇中提出的问题(1)与问题(2)提出解决常用的方法。
本文其实也就是结合以上四个方面进行讲解的,主要参考《RabbitMQ实战指南》(有需要PDF电子书的可以评论或者私信我),本文截图也来自其中,另外可以对一些RabbitMQ的概念的认识可以参考我的另外两篇博文认识RabbitMQ交换机模型、RabbitMQ是如何运转的?
三、生产者确认机制
针对问题(1),我们可以通过生产者的确认消息机制来解决,主要分为两种:第一是事务机制、第二是发送方确认机制
1、事务机制
与事务机制相关的有三种方法,分别是channel.txSelect设置当前信道为事务模式、channel.txCommit提交事务和channel.txRollback事务回滚。如果事务提交成功,则消息一定是到达了RabbitMQ中,如果事务提交之前由于发送异常或者其他原因,捕获后可以进行channel.txRollback回滚。
// 将信道设置为事务模式,开启事务 channel.txSelect(); // 发送持久化消息 channel.basicPublish(EXCHANGE_NAME, ROUTING_KEY, MessageProperties.PERSISTENT_TEXT_PLAIN, "transaction messages".getBytes()); // 事务提交 channel.txCommit();
发生异常之后事务回滚
try { channel.txSelect(); channel.basicPublish(exchange, routingKey, MessageProperties.PERSISTENT_TEXT_PLAIN, "transaction messages".getBytes()); channel.txCommit(); } catch (Exception e){ e.printStackTrace(); channel.txRollback(); }
2、确认机制
生产者将信道设置为confirm确认模式,确认之后所有在信道上的消息将会被指派一个唯一的从1开始的ID,一旦消息被正确匹配到所有队列后,RabbitMQ就会发送一个确认Basic.Ack给生产者(包含消息的唯一ID),生产者便知晓消息是否正确到达目的地了。
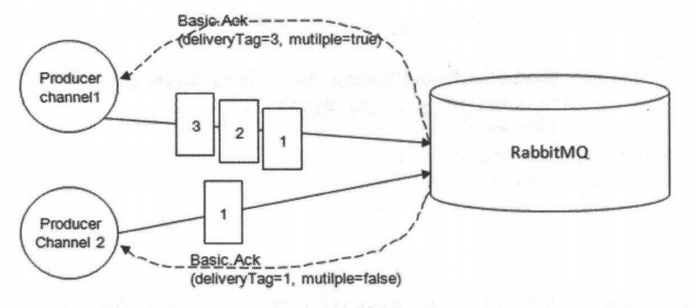
消息如果是持久化的,那么确认消息会在消息写入磁盘之后发出。RabbitMQ中的deliveryTag包含了确认消息序号,还可以设置multiple参数,表示到这个序号之前的所有消息都已经得到处理。确认机制相对事务机制来说,相比较代码来说比较复杂,但会经常使用,主要有单条确认、批量确认、异步批量确认三种方式。
2.1 单条确认
此种方式比较简单,一般都是一条条的发送,代码如下:
try { Connection connection = connectionFactory.newConnection(); Channel channel = connection.createChannel(); //set channel publisher confirm mode channel.confirmSelect(); // publish message channel.basicPublish("exchange", "routingkey", null, "publisher confirm test".getBytes()); if (!channel.waitForConfirms()) { // publisher confirm failed handle System.out.println("send message failed!"); } } catch (Exception e) { e.printStackTrace(); }
2.2 批量确认
问:批量确认comfirm需要解决出现返回的Basic.Nack或者超时情况的话,客户需要将这一批次消息全部重发,那么采用什么样的存储结构才能合适地将这些消息动态筛选出来。
最好是需要增加一个缓存,将发送成功并且确认Ack之后的消息去除,剩下Nack或者超时的消息,改进之后的代码如下:
// take ArrayList or BlockingQueue as a cache List<Object> cache = new ArrayList<>(); // set channel publisher confirm mode channel.confirmSelect(); for (int i=0; i < 20; i++) { // publish message String message = "publisher message["+ i +"]"; cache.add(message); channel.basicPublish("exchange", "routingkey", null, message.getBytes()); if (channel.waitForConfirms()) { // remove message publisher confirm cache.remove(i); } // TODO handle Nack message:republish } } catch (Exception e) { e.printStackTrace(); // TODO handle Nack message:republish }
2.3 异步批量确认
异步确认方式通过在客户端addConfirmListener增加ConfirmListener回调接口,包括handleAck与handleNack处理方法:
每次发送消息confirmSet集合元素加1,当消息被确认ack进入handleAck方法时,“unconfirm”集合中删除响应的一条(multiple设置为false时)或者多条记录(multiple设置为true时),其中存储缓存最好采用SortedSet数据结构
代码如下:
try { Connection connection = connectionFactory.newConnection(); Channel channel = connection.createChannel(); // take as a cache SortedSet cache = new TreeSet(); // set channel publisher confirm mode channel.confirmSelect(); for (int i = 0; i < 20; i++) { // publish message long nextSeqNo = channel.getNextPublishSeqNo(); String message = "publisher message[" + i + "]"; cache.add(message); channel.basicPublish("exchange", "routingkey", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes()); cache.add(nextSeqNo); } // add confirmCalback: handleAck, handleNack channel.addConfirmListener(new ConfirmListener() { @Override public void handleAck(long deliveryTag, boolean multiple) { if (multiple) { // batch remove ack message cache.headSet(deliveryTag - 1).clear(); } else { // remove ack message cache.remove(deliveryTag); } } @Override public void handleNack(long deliveryTag, boolean multiple) { // TODO handle Nack message:republish } }); } catch (Exception e) { e.printStackTrace(); // TODO handle Nack message:republish }
3、总结比较
1)是确认机制好呢?还是事务机制?两者可以共存吗?
确认机制相对于事务机制,最大的好处就是可以异步处理提高吞吐量,不需要额外等待消耗资源。但是两者时候不能同时共存的。
2)那么确认机制的三种方式之间呢?实际产生环境是推荐哪一种呢?(其实毫无疑问当然是推荐异步批量确认方式)
批量确认的最大问题就是在于返回的Nack消息需要重新发送,以上普通单条确认、批量确认、批量异步确认三种方法,在实际生产环境中强烈推荐使用批量异步确认方式。
四、消息与队列的持久化
针对的问题(2),我们可以通过增加队列与消息的持久化来实现。
1、交换器的持久化
交换器的持久化是通过声明队列durable参数为true实现的,如果交换器不设置持久化,那么在RabbitMQ服务器重启之后,相关的交换器元数据会丢失,消息不会丢失,只是不能将消息发送到这个交换器中。因此,都是建议将其置为持久化。
channel.exchangeDeclare(EXCHANGE_NAME, "direct", true, false, null);
2、队列的持久化
队列持久化同理与交换器持久化,只是RabbitMQ服务器重启之后,相关的元数据会丢失,数据也会跟着丢失,消息也自然丢失。
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
3、消息的持久化
队列的持久化不能保证内存存储的消息不会丢失,要确保消息不会丢失,需要将其通过设置BasicProperties中的deliveryMode属性为2可实现消息的持久化(PERSISTENT_TEXT_PLAIN实际上已经封装了这个属性),也就是说只有实现了队列与消息的持久化,才能保证消息不会丢失。
// 其中的2就是投递模式 public static Class final BasicProperties_PERSISTENT_TEXT_PLAIN =
new BasicProperties("text/plain", null, null, 2, null, null, null, null, null, null, null, null, null);
4、消息丢失的几种情况
但实际上不是设置了交换器、队列、消息持久化就能一定保证消息不会被丢失,以下几种情况是可能丢失的,比如:
1)设置autoAck为true,消费者收到消息后,还没处理就宕机了,这样也算数据丢失,解决办法是设置为false,之后手动确认。
2)在设置了持久化后消息存入RabbitMQ之后,还需要一段时间才能存入磁盘之中(虽然很短,但不能忽视),RabbitMQ并不会为每条消息都今次那个同步存盘,可能只会保存到操作系统缓存之中而不是物理磁盘中,如果RabbitMQ这个时间段内宕机、异常、重启等情况,消息也会丢失,解决办法是引入RabbitMQ的镜像队列机制(类似于集群,Master挂了切换到Slave)
总结
没有完全十全十美的方式能保证数据能100%不丢失,并且最大效率节约性能消耗等,两篇博文虽然已经提出常用的四种方式,当实际环境中整个RabbitMQ环境在搭建没有结合实际的生产业务环境的话,也会发生消息丢失的等情况,解决这样的问题无非就完善消息备份,健全RabbitMQ集群..........

 浙公网安备 33010602011771号
浙公网安备 33010602011771号