
语音助手Antenna(长期更新)
目标
制作一个个人的语音助手随时能聊天,核心要求是能够了解我,包括能够认识我周围的人,知晓我的生活经历,同时也能够连接网络搜索内容,为我提供知识。强调一个私人性,得知道我的个人信息并能聊起来。按照现在大模型的发展速度,肯定已经、或即将有这种东西了,但是一是不想付费,二是自己搞的过程中也学学东西。害本来是玩嵌入式的,现在演化到这个项目了。这个助手的名字就叫Antenna好了,原意“天线”,这里致敬/来源于Halo里的Cortana。
实现思路
该助手需要长期开机收集我的个人生活信息,目前主要是语音内容,有针对性的定期finetune。因此软件层面,需要基于一个预训练的大语言模型进行语言交互,一个语音识别模型将语音转换为文字;硬件层面需要录音和相应的控制设备、大模型的部署设备和与大模型通信的设备。
基本方案
饭得一口一口吃,初步设想先不动硬件,软件包括云和本地两个部分。使用本地设备收集我的语音内容,整理成适配大模型的数据集格式,定期上传云平台进行大模型finetune,然后定期下载finetune后的模型至本地进行merge;本地运行大模型平时交互的inference。
我手里算力最强、同时也是用的最多的本地设备是一台2021年的MacBook Pro,搭载Apple M1 Pro芯片组,8+2核CPU,16G内存,16核GPU,驱动架构为苹果自己的Metal 3,目前系统为Sequoia 15.0. 另有一台实验室的Intel台式机,无GPU,唯一优点是windows系统,且存储几个T...
嵌入式设备方面,算力最强的是意法半导体的STM32MP157,目前只是一块来自正点原子的核心板,主频800MHz,内置GPU(但不会用),板载1G内存和8G存储eMMC和千兆PHY,感觉有可能带的动简单的模型。。
另看上了基于RK3566的泰山派卡片电脑,主频1.8GHz,搭载NPU和支持OpenGL的GPU,2G内存,价格也挺友好,考虑入手。
漫长的测试
学习大模型使用
kimi广告做的多,用起来也不错,而且免费,API也很完善,但是不开源没法finetune。但是先做点能跑的玩意儿出来鼓舞下士气还是很有必要滴。先用python基于kimi做了一个仅inference的语音对话demo在Mac上跑着玩一下,主要包括三部分:(1)调用Mac麦克风录音后转文字;(2)文字输入给kimi并获得回答文本;(3)文本转语音播放。步骤(1)最广泛的包是在线识别的GoogleSpeech,免费、准确度高、中英通吃,但是得联网,有时候略慢;另一个不联网方案是vosk,不设计特殊名词和英文时准确度不错,且本地跑速度很快,调包大法用起来都很简单,我都是直接用kimi生成的code改一改就用了。步骤(2)用的kimi的API,教程很详细,且内置了网络搜索功能,很nice,直接copy过来。步骤(3)用的pyttsx3,中文语音只有Tingting,很不好听,不过用起来倒也简单,速度快且完全本地,先凑合着。代码全文如下:
点击查看代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 28 19:13:28 2024
@author: jiaminghu
"""
from openai import OpenAI
import cv2
import sounddevice as sd
import numpy as np
from scipy.io.wavfile import write
import pyttsx3
import pyaudio
from vosk import Model, KaldiRecognizer
import json
import time
from typing import *
from openai.types.chat.chat_completion import Choice
import speech_recognition as sr
def listen_for_command():
# 初始化识别器
recognizer = sr.Recognizer()
# 使用麦克风作为音频源
with sr.Microphone() as source:
print("Please speak command...")
audio = recognizer.listen(source)
try:
# 使用Google的免费Web API进行语音识别
command = recognizer.recognize_google(audio, language='zh-CN') #en-US'
print("You said: " + command)
# 在这里,你可以将command发送给Kimi搜索
answer = kimi_search(command)
# 将文本转换为语音并播放
engine.say(answer)
engine.runAndWait()
# 在这里,你可以将command发送给Kimi搜索
# 例如,你可以调用一个函数来处理搜索请求
return command
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
return None
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
return None
def listen_for_command_localvosk():
# 指定模型路径
model_path = "./vosk-model-small-cn-0.22"
model = Model(model_path)
# 初始化识别器,采样率为16000Hz
recognizer = KaldiRecognizer(model, 16000)
# 定义音频流参数
chunk = 1024
format = pyaudio.paInt16
channels = 1
rate = 16000
p = pyaudio.PyAudio()
# 开启音频流
stream = p.open(format=format, channels=channels, rate=rate, input=True, frames_per_buffer=chunk)
print("开始说话,说'停止'以结束录音...")
# 记录开始时间
start_time = time.time()
text = ''
# 读取音频流
while True:
data = stream.read(chunk)
if recognizer.AcceptWaveform(data):
result = recognizer.Result()
if result:
result_json = json.loads(result)
if 'text' in result_json:
if '停止' in result_json['text']:
print("停止录音")
break
print("识别结果:", result_json['text'])
text += result_json['text']
# 检查是否说出了“停止”
if time.time() - start_time > 20: # 设置超时时间为10秒,也可以根据需要调整
print("超时,自动停止录音")
break
# 关闭音频流
stream.stop_stream()
stream.close()
p.terminate()
command = text.strip()
print("You said: " + command)
# 在这里,你可以将command发送给Kimi搜索
answer = kimi_search(command)
# 将文本转换为语音并播放
engine.say(answer)
engine.runAndWait()
return command
def kimi_search_offline(query):
# 这里应该是调用Kimi搜索的代码
query = '你好kimi, ' + query
print("Searching Kimi for: " + query)
client = OpenAI(
api_key = "API_KEY", #得用自己的KEY哦
base_url = "https://api.moonshot.cn/v1",
)
completion = client.chat.completions.create(
model = "moonshot-v1-8k",
messages = [
{"role": "system", "content": system_query},
{"role": "user", "content": query}
],
temperature = 0.8,
)
print(completion.choices[0].message.content)
# 要转换为语音的文本
return completion.choices[0].message.content
def kimi_search(query):
query = '你好kimi, ' + query
print("Searching Kimi for: " + query)
client = OpenAI(
api_key = "sk-NZ9KYlSLrfCUEe3gvGMO6YSP99Lf7n5OVzoNer6xRtfHfbti",
base_url = "https://api.moonshot.cn/v1",
)
messages = [
{"role": "system", "content": system_query},
]
# 初始提问
messages.append({
"role": "user",
"content": query
})
# search 工具的具体实现,这里我们只需要返回参数即可
def search_impl(arguments: Dict[str, Any]) -> Any:
"""
在使用 Moonshot AI 提供的 search 工具的场合,只需要原封不动返回 arguments 即可,
不需要额外的处理逻辑。
但如果你想使用其他模型,并保留联网搜索的功能,那你只需要修改这里的实现(例如调用搜索
和获取网页内容等),函数签名不变,依然是 work 的。
这最大程度保证了兼容性,允许你在不同的模型间切换,并且不需要对代码有破坏性的修改。
"""
return arguments
def chat(messages) -> Choice:
completion = client.chat.completions.create(
model="moonshot-v1-128k",
messages=messages,
temperature=0.3,
tools=[
{
"type": "builtin_function", # <-- 使用 builtin_function 声明 $web_search 函数,请在每次请求都完整地带上 tools 声明
"function": {
"name": "$web_search",
},
}
]
)
return completion.choices[0]
finish_reason = None
while finish_reason is None or finish_reason == "tool_calls":
choice = chat(messages)
finish_reason = choice.finish_reason
if finish_reason == "tool_calls": # <-- 判断当前返回内容是否包含 tool_calls
messages.append(choice.message) # <-- 我们将 Kimi 大模型返回给我们的 assistant 消息也添加到上下文中,以便于下次请求时 Kimi 大模型能理解我们的诉求
for tool_call in choice.message.tool_calls: # <-- tool_calls 可能是多个,因此我们使用循环逐个执行
tool_call_name = tool_call.function.name
tool_call_arguments = json.loads(tool_call.function.arguments) # <-- arguments 是序列化后的 JSON Object,我们需要使用 json.loads 反序列化一下
if tool_call_name == "$web_search":
tool_result = search_impl(tool_call_arguments)
else:
tool_result = f"Error: unable to find tool by name '{tool_call_name}'"
# 使用函数执行结果构造一个 role=tool 的 message,以此来向模型展示工具调用的结果;
# 注意,我们需要在 message 中提供 tool_call_id 和 name 字段,以便 Kimi 大模型
# 能正确匹配到对应的 tool_call。
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_call_name,
"content": json.dumps(tool_result), # <-- 我们约定使用字符串格式向 Kimi 大模型提交工具调用结果,因此在这里使用 json.dumps 将执行结果序列化成字符串
})
print(choice.message.content)
return choice.message.content # <-- 在这里,我们才将模型生成的回复返回给用户
if __name__ == "__main__":
system_query = "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。你之后收到的文字来源于语音识别,所以可能会有误差、重复和标点不全的情况,请按照一个人通常说话的习惯进行理解。"
engine = pyttsx3.init()
engine.setProperty('voice', 'com.apple.voice.compact.zh-CN.Tingting')
engine.setProperty('rate', 220)
command = listen_for_command()
#command = listen_for_command_localvosk()
大模型Finetune
玩够了以后,继续测试大模型的finetine。优先考虑了阿里云的通义千问系列QWen,因为中英都支持的好,而且是开源里目前性能最好的嘛。inference很顺利,但是官方的finetune script不支持苹果的GPU架构Metal Performance Shaders(MPS),这让我手里唯一的GPU都用不起来了。好在MPS的生态做的不错,有一个专门的repo叫MLX,介绍说it is an array framework for machine learning research on Apple silicon(https://github.com/ml-explore) ,特别有llm的例子,先跟着一篇博客(https://apeatling.com/articles/part-3-fine-tuning-your-llm-using-the-mlx-framework/) 使用测试一下Mistral-7B-Instruct-v0.2,关键步骤为:
先下载mlx-exmplesgit clone https://github.com/ml-explore/mlx-examples.git,
安装lora的依赖cd mlx-examples/lora pip install -r requirements.txt
直接调用lora.py训练
python lora.py \ --train \ --model mistralai/Mistral-7B-Instruct-v0.2 \ --data ~/Developer/AI/Models/fine-tuning/data \ --batch-size 2 \ --lora-layers 8 \ --iters 1000
实测能用!看着跑满的GPU十分满意哈哈哈
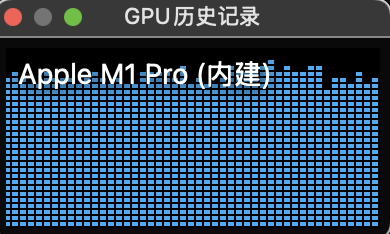
接着测试Qwen。直接调用官方版Qwen是无法load的,会报无法载入参数的错误,必须调用转化为mlx格式的的模型,有两个来源:第一个是用mlx提供的mlx_lm.convert将其他非mlx格式的大模型转为mlx格式;第二是调用mlx的Hugging face仓库里已有的(https://huggingface.co/mlx-community?) ,现在已经有190个模型了,都是开发者用第一个方法convert以后上传的,包括全套最新的Qwen,直接搜索关键词就能找到
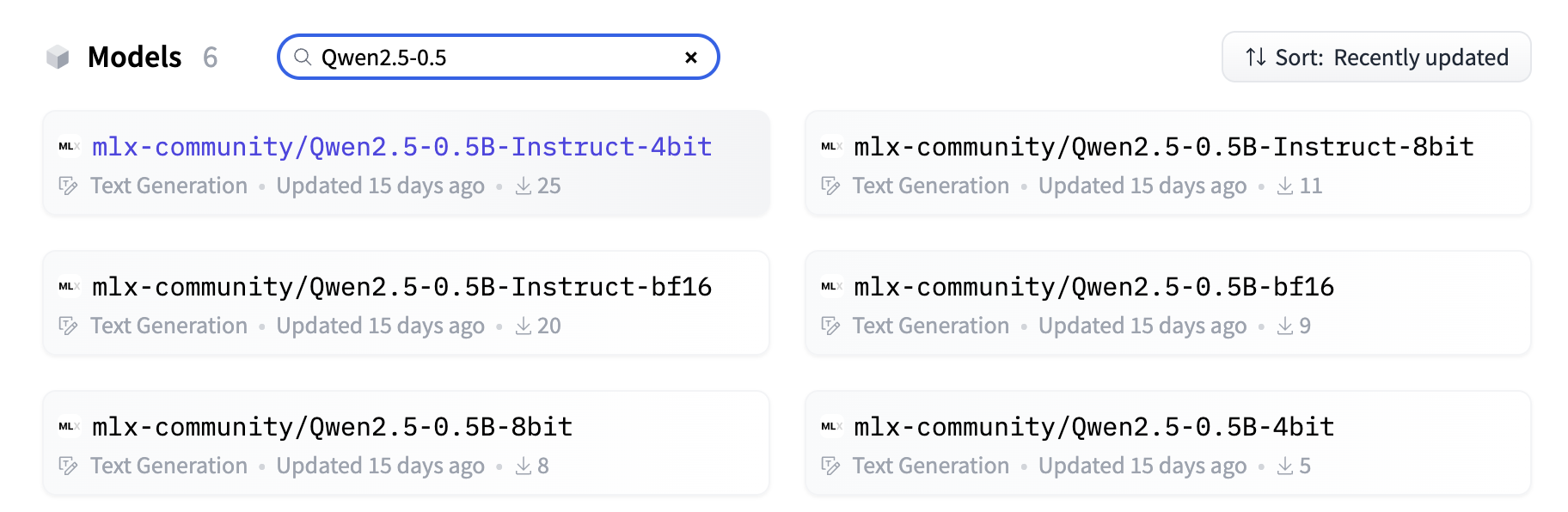
不得不感叹生态的重要性!既然有了那我就不客气了,后面再测试convert为社区做贡献吧,先直接下载用。
为了后续嵌入式部署的可能性,先考虑了一个最小的0.5B模型,即mlx-community/Qwen2.5-0.5B-Instruct-4bit。注意此时不能像上述那篇博客那样直接直接执行lora.py,会报错,应该是pip安装整个mlx_lm包
pip install mlx-lm
或者,因为我之前已经下载了mlx-examples,就直接在mlx-examples/llms里安装pip install .
安装后得到包mlx_lm。然后准备finetune数据,mlx的github上(https://github.com/ml-explore/mlx-examples/blob/main/llms/mlx_lm/LORA.md#Data) 给出了数据的格式,需要准备train.jsonl, test.jsonl和valid.jsonl三个文件,我需要的chat数据格式如下:
{"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello."}, {"role": "assistant", "content": "How can I assistant you today."}]}
注意和Qwen官方finetune给的格式不太一样,不过核心要素还是对话的内容嘛,大差不差。另注意jsonl是一行一条数据,不能有额外空格。初步测试就准备了8条数据,就是让她知道我、yb和jy是谁(Antenna当然是‘她’啦),然后用如下命令预训练
python -m mlx_lm.lora --model mlx-community/Qwen2.5-0.5B-Instruct-4bit --train --iters 600 --data "./"
这里3个.jsonl文件我就放到当前目录"./"下了。调对数据结构以后顺利执行,600个iteration训练的飞快,erro从5.6降到了0.03左右,用了不到2分钟。结束后得到了./adapter文件夹,里面有每100步存的训练好的adapter。训练时默认采用lora,即将大模型参数中的一部分拿来训练。
接下来进行测试,因为只为了跑通流程,测试集就偷懒直接copy了训练集,测试命令为
mlx_lm.lora --model mlx-community/Qwen2.5-0.5B-Instruct-4bit --adapter-path "./adapters" --data "./" --test
得到困惑度1.024,后面再研究具体含义,反正就是一个评价llm的指标,大概和entropy有关,越低越好。直接让它生成一下看看效果
mlx_lm.generate --model mlx-community/Qwen2.5-0.5B-Instruct-4bit --adapter-path "./adapters" --prompt "你是谁"
效果。。一言难尽,并没有知道她是Antenna,稍微认识了一下我,但是高估了我的身份,高估的有点过不了审的僭越,就不放出来了。。不管怎么样,再测试下fuse,运行
mlx_lm.fuse --model mlx-community/Qwen2.5-0.5B-Instruct-4bit
默认读取./adpaters中的adapter然后整合到预训练的Qwen中,生成fused_model文件夹就是可以用mlx_lm.generate直接调用的了,将mlx_lm.generate的--model设置为fused_model的地址即可。fuse之后的模型和adapter还是有区别的,同一个问题的回答不一样。反正终于流程跑通了,后面再慢慢调参并测试其他模型吧,可能0.5B不太够用(但是快是真的快)。
语音测试
另一方面同步测试的是语音,一直用Tingting肯定也受不了。这个平台(https://fish.audio/zh-CN) 简单用了一下搞的不错,上传了对象的一段20s音频,很快就能学到语音模型,现在研究一下API和价格。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号