Python学习笔记(一、Python基础)
本学习笔记是根据 中国大学MOOC北京理工大学Python语言程序设计一课程而产生,仅供个人学习及复习使用。
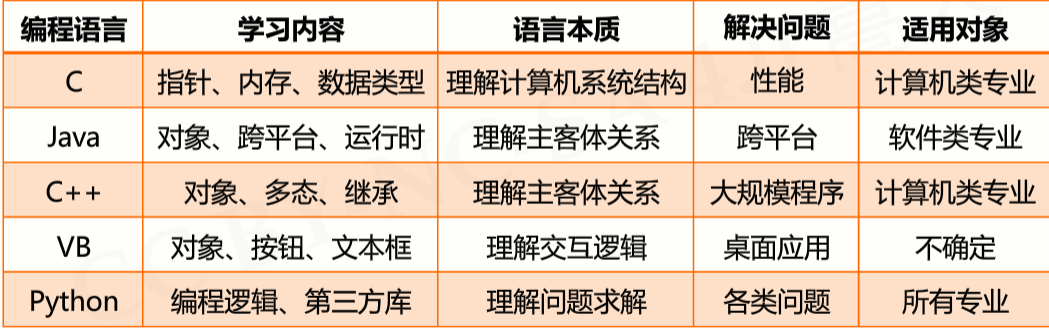
- Python语言是通用语言
- Python语言是脚本语言
- Python语言是开源语言
- Python语言是跨平台语言
- Python语言是多模型语言

Python基础
注释:单行:#内容,多行:"""内容"""
python利用相同的缩进表示同一语句块
如果一行只有一句代码,末尾不用加分号,否则末尾要加分号
如果一行代码写不下,该行最后加上一个'\',然后下一行接着写
Python中的几种数据类型
整数类型
没有取值范围限制
pow(x, y),计算x的y次幂
十进制:
二进制:以0b、0B开头
八进制:以0o、0O开头 比如:0o123、-0O456
十六进制:以0x、0X开头
浮点数类型
取值范围和小数精度都存在限制,但常规计算可忽略
取值范围数量级约-10308至10308,精度数量级10-16
浮点数运算存在不确定尾数,因为用二进制表示小数,可以无限接近,但不完全相同
0.1+0.2 != 0.3
浮点数间的运算及比较用round()函数辅助,不确定尾数一般发生在10-16左右,round()十分有效
round(a, b)==c :对a四舍五入,b是小数截取位数
浮点数可以采用科学计数法表示: aeb 表示 a*10b
复数类型
定义 j=√(-1),用 a+bj 表示复数,其中 a 是实部, b 是虚部
z=1.23e-4 + 5.6e + 89j
用 z.real 获取实部,用 z.imag 获取虚部
数值运算操作符
+、-、*、/、//、%、**
注意:
Python中 / 为浮点数除法,// 为整数除
x**y,表示x的y次幂,当y为小数时,进行开方运算
类型间可进行混合运算,生成结果为“最宽”类型:整数<浮点数<复数
整数+浮点数=浮点数
数值运算函数
abs(x),绝对值,取x的绝对值
divmod(x, y),商余,( x//y,x%y ),同时输出整数商和余数(二元组)
pow(x,y[, z]),幂余,(x**y)%z,z可省略
round(x[, d]),四舍五入,d为保留小数的位数,默认值为0
max(x1, x2, ……, xn),最大值
min(x1, x2, ……, xn),最小值
int(x),改x为整数,舍弃小数部分、变字符串为整数
float(x),将x变为浮点数,增加小数部分、变字符串为浮点数
complex(x),将x变为复数,增加虚数部分
字符串
由一对单引号或一对双引号表示,仅表示单行字符串
由一对三单引号或三双引号表示,可表示多行字符串
使得单引号和双引号的出现很好处理
切片:字符串[M:N:K] ,M缺失表示开头,N缺失表示结尾,K表示步长
将字符串逆序:[::-1]
转义符\,转义变大特定字符的本意,如\",表示双引号
转义符形成一些组合,表达一些不可打印的含义
\b回退,
\n换行,
\r光标移动至本行首,可实现对一行输出的覆盖,如进度条
字符串类型及操作
x+y:连接两个字符串x和y
n*x:复制n次字符串x
x in s:如果x是s的子串,返回true,否则返回false
字符串处理函数
len(x),长度,返回字符串长度
str(x),任意类型x所对应的字符串形式(相当于在两侧加引号,与eval工作相反)
hex(x),整数x的十六进制小写形式字符串
oct(x),整数x的八进制小写形式字符串
chr(u),u为Unicode编码,返回其对应的字符
ord(x),x为字符,返回其对应的Unicode编码
字符串处理方法
str.lower(),返回字符串的副本,全部字符小写
str.upper(),返回字符串的副本,全部字符大写
str.split(sep=None),返回一个列表,由str根据sep被分隔的部分组成,![]()
str.count(sub),返回子串sub在str中出现的次数
str.replace(old, new),返回字符串str的副本,将其中所有的old子串替换为new
str.center(width[, fillchar]),字符串str根据宽度width居中,fillchar为两侧的填充字符,可选,![]()
str.strip(chars),从str中去掉其左侧和右侧chars中列出的字符,![]()
str.join(iter),在iter变量除最后一个元素外,每个元素后增加一个str,它是格式化输出,尤其是按规律在字符串中增加分隔符的重要方法,![]()
字符串类型的格式化
字符串格式化使用.format()方法,槽:{<参数序号> : <格式控制标记>}
<模板字符串>.format(<逗号分隔的参数>),将format()中的参数按照相应的顺序添到模板字符串的相应的槽中
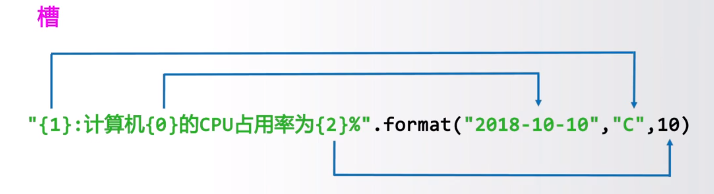

前三个通常一起用,可看成一组
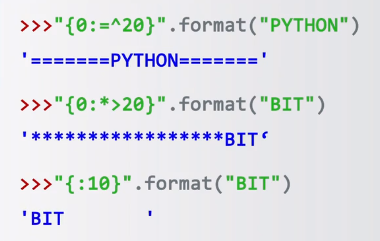
后三个通常一起用,可看成一组
程序的分支结构
单分支:
if <条件> : 语句块
二分支的紧凑方式:<表达式1> if <条件> else <表达式2>
多分支:
if <条件> : 语句块1 elif <条件> : 语句块2 else : 语句块3
操作符及用于条件组合的三个保留字
操作符:<、<=、>=、>、==、!=
与或非:and、or、not
异常处理
try : <语句块1> except : <语句块2>
语句块1无异常就执行语句块1,有异常就执行语句块2
try : <语句块1> except <异常类型名称>: <语句块2>
语句块1无异常就执行语句块1,有异常且是except后的那种异常类型就执行语句块2
高级
try : <语句块1> except : <语句块2> else : <语句块3> finally : <语句块4>
else对应的语句块3是在try不发生异常时执行,无论是否发生异常语句块4一定执行
程序的循环结构
遍历循环
for <循环变量> in <遍历结构> : <语句块>
- 由保留字for和in组成,完成遍历所有元素后结束
- 每次循环,所获得元素放入循环变量,并执行一次语句块
for i in range(N) : <语句块>
- 遍历由range()函数产生的数字序列,产生循环 ( i 可省略)
range(N),产生 0~N-1 的整数序列,共N个
range(M, N),产生 M 到 N-1 的整数序列,共N-M个
range(M, N, K),产生由 M 到 N-1 且步长为K的整数序列
列表遍历循环:
for item in [123, "py", 456] : print(item, end=",")
文件按行的遍历循环:
for line in fi : <语句块>
- fi是一个文件标识符,遍历其每一行,产生循环
无限循环
while <条件> : <语句块>
- 反复执行语句块,知道条件不满足时结束
循环控制保留字
break 和 continue
循环的高级用法
循环+else
while <条件> : <语句块> else : <语句块>
- 当循环没有被break语句退出时,执行else语句块
- else语句块作为“正常”完成循环的奖励,这里else的用法与异常处理中的else用法相似
函数
一般函数
def <函数名>(<参数(零个或多个)>): <函数体> return <返回值>
可选参数传递
函数定义时可为某些参数指定默认值,构成可选参数
def <函数名>(<必选参数>, <可选参数>): <函数体> return <返回值>
可选参数一定要放在必选参数后面

可变参数传递
例子:max()和min()
函数定义时可设计可变数量参数,即不确定参数总数量
def <函数名>(<参数>, *b ): <函数体> return <返回值>

b为组合数据类型
参数传递的两种方式
函数调用时,参数可以按照位置或名称方式传递

函数的返回值
函数可以返回0个或多个结果
- return保留字用来传递返回值
- 函数可以有返回值,也可以没有,可以有return ,也可以没有
- return可以传递0个返回值,也可以传递任意多个返回值


局部变量和全局变量
规则1: 局部变量和全局变量是不同变量
- 局部变量是函数内部的占位符,与全局变量可能重名但不同
- 函数运算结束后,局部变量被释放
- 可以使用global保留字在函数内部声明全局变量


规则2:局部变量为组合数据类型且未创建,等同于全局变量
其实组合数据类型在Python中是由指针来体现的,所以函数中如果没有真实创建组合数据类型,他是用的变量是使用的指针,而指针指的是外部的全局变量,所以当修改这个指针对应的内容,就修改了全局变量


lambda函数
lambda函数返回函数名作为结果
- lambda函数是一种匿名函数,即没有名字的函数
- 使用lambda保留字定义,函数名是返回结果
- lambda函数用于定义简单的、能够在一行内表示的函数

这是一种非常简单的函数的紧凑表达形式

谨慎使用lambda函数
- lambda函数主要用作一些特定函数或方法的参数
- lambda函数有一些固定使用方式,建议逐步掌握
- 一般情况,建议使用def定义的普通函数
案例:
七段数码管绘制
import turtle, time def DrawGap(): #绘制数码管间隔 turtle.penup() turtle.fd(5) def DrawLine(flag): #绘制单段数码管 DrawGap() turtle.pendown() if flag else turtle.penup() turtle.fd(40) DrawGap() turtle.right(90) def DrawDigit(x): #根据数字绘制七段数码管 DrawLine(True) if (x) in [2, 3, 4, 5, 6, 8, 9] else DrawLine(False) DrawLine(True) if (x) in [0, 1, 3, 4, 5, 6, 7, 8, 9] else DrawLine(False) DrawLine(True) if (x) in [0, 2, 3, 5, 6, 8, 9] else DrawLine(False) DrawLine(True) if (x) in [0, 2, 6, 8] else DrawLine(False) turtle.left(90) DrawLine(True) if (x) in [0, 4, 5, 6, 8, 9] else DrawLine(False) DrawLine(True) if (x) in [0, 2, 3, 5, 6, 7, 8, 9] else DrawLine(False) DrawLine(True) if (x) in [0, 1, 2, 3, 4, 7, 8, 9] else DrawLine(False) turtle.left(180) turtle.penup() turtle.fd(20) def DrawData(date): #date为日期,格式为‘%Y-%m=%d+’ turtle.pencolor("red") for i in date: if i == '-': turtle.write('年', font=("Arial", 18, "normal")) turtle.pencolor("green") turtle.fd(40) elif i == '=': turtle.write('月', font=("Arial", 18, "normal")) turtle.pencolor("blue") turtle.fd(40) elif i == '+': turtle.write('日', font=("Arial", 18, "normal")) else: DrawDigit(eval(i)) def main(): turtle.setup(800,350,200,200) turtle.penup() turtle.fd(-350) turtle.pensize(5) DrawData(time.strftime("%Y-%m=%d+", time.gmtime())) turtle.hideturtle() turtle.done() main()
组合数据类型
集合类型及操作
集合是多个元素的无序组合
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
集合用大括号 {} 表示,元素间用逗号分隔
-建立集合类型用 {} 或 set()
-建立空集合类型,必须使用 set()
集合用大括号{}表示,元素间用逗号分隔
集合中每个元素唯一,不存在相同元素
集合元素之间无序
集合间运算
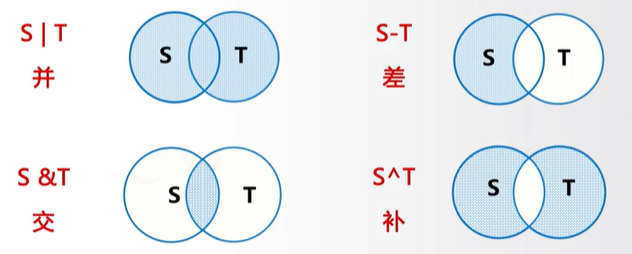
6个操作符:
S | T:返回一个新集合,包括在集合S和T中的所有元素
S - T:返回一个新集合,包括在集合S但不在T中的元素
S & T:返回一个新集合,包括同时在集合S和T中的元素
S ^ T:返回一个新集合,包括集合S和T中的非相同元素
S <= T或S < T:返回True/False,判断S和T的子集关系
S >=T 或S > T:返回True/False,判断S和T的包含关系
4个增强操作符:
S |= T:更新集合S,包括在集合S和T中的所有元素
S -= T:更新集合S,包括在集合S但不在T中的元素
S &= T:更新集合S,包括同时在集合S和T中的元素
S ^= T:更新集合S,包括集合S和T中的非相同元素
集合处理方法
S.add(x):如果x不在集合S中,将x增加到S
S.discard(x):移除S中元素x,如果x不在集合S中,不报错
S.remove(x):移除S中元素x,如果x不在集合S中,产生KeyError异常
S.clear():移除S中所有元素
S.pop():随机返回S的一个元素,更断S,若S为空产生KeyError异常
S.copy():返回集合S的一个副本
len(S):返回集合S的元素个数
x in S:判断S中元素x,x在集合S中,返回True,否则返回False
x not in S:判断S中元素x,x不在集合S中,返回True,否则返回False
set(x):将其他类型变量x转变为集合类型
集合类型应用场景:
元素去重
序列类型及操作
序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列: S0,S1.....Sn-1
- 元素间由序号引导,通过下标访问序列的特定元素
序列是一个基类类型,包括:字符串类型、元组类型、列表类型
序列处理函数及方法
6个操作符
x in s:如果x是序列s的元素,返回True ,否则返回False
x not in s:如果x是序列s的元素,返回False ,否则返回True
s + t:连接两个序列s和t
s*n或n*s:将序列s复制n次
s[i]:索引,返回s中的第i个元素,i是序列的序号
s[i : j]或s[i : j : k]:切片,返回序列s中第i到j以k为步长的元素子序列
5个函数和方法
len(s):返回序列s的长度
min(s):返回序列s的最小元素,s中元素需要可比较
max(s):返回序列s的最大元素,s中元素需要可比较
s.index(x)或s.index(x, i, j):返回序列s从开始到位置中第一次出现元素的位置
s.count(x):返回序列s中出现x的总次数
元组是序列类型的一种扩展
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号,分隔
- 可以使用或不使用小括号

列表类型及操作
列表是序列类型的一种扩展,十分常用
- 列表是一种序列类型,创建后可以随意被修改
- 使用方括号 [] 或 list() 创建,元素间用逗号,分隔
- 列表中各元素类型可以不同,无长度限制
如果没使用方括号 [] 或 list(),而是仅仅赋值,则只是换了个名

列表类型及操作函数或方法
ls[i] = x:替换列表ls第i元素为x
Is[i : j : k] = lt:用列表lt替换ls切片后所对应元素子列表
del Is[i]:删除列表ls中第i元素
del Is[i : j : k]:删除列表ls中第i到第j以k为步长的元素
Is += It:更新列表ls,将列表lt元素增加到列表ls中
Is *= n:更新列表Is,其元素重复n次
ls.append(x):在列表Is最后增加一个元素x
ls.clear():删除列表ls中所有元素
ls.copy():生成一个新列表,赋值ls中所有元素
Is.insert(i, x):在列表Is的第i位置增加元素x
ls.pop(i):将列表ls中第i位置元素取出并删除该元素
ls.remove(x):将列表ls中出现的第一个元素x删除
Is.reverse():将列表ls中的元素反转
小测试,思考如何实现:

序列类型应用场景:
- 元组用于元素不改变的应用场景,更多用于固定搭配场景
- 数据保护:如果不希望数据被程序所改变,转换成元组类型
- 列表更加灵活,它是最常用的序列类型
最主要作用:表示一组有序数据,进而操作它们
实例:
基本统计值
def getnum(): nums = [] nstr = input("请输入数字(回车结束):") while nstr != "": print(nstr) nums.append(eval(nstr)) nstr = input("请继续输入数字(回车结束):") return nums def mean(nums): #计算平均值 res = 0.0 for i in nums: res += i return res/len(nums) def dev(nums): #计算方差 t = mean(nums) res = 0.0 for i in nums: res += (i-t)**2 return pow(res/(len(nums)-1), 0.5) def median(nums): #计算中位数 sorted(nums) #内置排序函数 size = len(nums) if size%2 == 0: res = (nums[size//2-1]+nums[size//2])/2 else : res = nums[size//2] return res n = getnum() print("平均值:{},方差:{:.2},中位数:{}.".format(mean(n),dev(n),median(n)))
def getnum(): s = input() ls = list(eval(s)) return ls def mean(nums): #计算平均值 res = 0.0 for i in nums: res += i return res/len(nums) def dev(nums): #计算方差 t = mean(nums) res = 0.0 for i in nums: res += (i-t)**2 return pow(res/(len(nums)-1), 0.5) def median(nums): #计算中位数 nums.sort() size = len(nums) if size%2 == 0: res = (nums[size//2-1]+nums[size//2])/2 else : res = nums[size//2] return res n = getnum() print("平均值:{:.2f},标准差:{:.2f},中位数:{}".format(mean(n),dev(n),median(n)))
字典类型及操作

字典类型是”映射”的体现
- 键值对:键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号 {} 和 dict() 创建,键值对用冒号:表示
- d[key]方式既可以索引,也可以赋值
字典类型操作函数和方法:
del d[k]:删除字典d中键k对应的数据值
k in d:判断键k是否在字典d中,如果在返回True,否则False
d.keys():返回字典d中所有的键信息
d.values():返回字典d中所有的值信息
d.items():返回字典d中所有的键值对信息
tips:上面.key()和.values()函数返回的不是列表类型,而是一种字典的特殊类型
d.get(k, <default>):键k存在,则返回相应值,不在则返回<default>值
d.pop(k, <default>):键k存在,则取出相应值,不在则返回<default>值
d.popitem():随机从字典d中取出一个键值对,以元组形式返回
d.clear():删除所有的键值对
len(d):返回字典d中元素的个数
字典类型应用场景:
映射的表达
实例:
英文文本词频统计:
def GetText(): #归一化处理 txt = open("hamlet.txt", "r").read() txt = txt.lower() for ch in txt: if ch in '!"#$%&()*+,-./:;<=>?@[\\]^_`‘{|}~': txt = txt.replace(ch, " ") return txt txt = GetText() words = txt.split() counts = {} for word in words: counts[word] = counts.get(word, 0)+1 lt = list(counts.items()) lt.sort(key = lambda x:x[1], reverse = True) #由大到小的排序 for i in range(10): word, count = lt[i] print("{0:<10}{1:>5}".format(word, count))
-
