机器学习数学基础-线性代数
前言
AI(人工智能)现在火的一塌糊涂,其实在AI领域,机器学习已广泛应用在搜索引擎、自然语言处理、计算机视觉、生物特征识别、医学诊断、证券市场分析等领域,并且机器学习已经是各大互联网公司的基础设施,不再是一个新鲜的技术。但当你真的开始学习机器学习的时候,就会发现上手门槛其实还挺高的,这主要是因为机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
本文主要介绍一下机器学习涉及到的一些最常用的的数学知识,方便大家在学习机器学习的时候,能扫除一些基础障碍。
标量(scalar)
标量是一个单独的数,一般用普通小写字母或希腊字母表示,如 等。
向量(vector)相关
向量的定义
把数排成一列就是向量,比如:
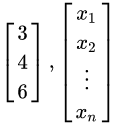
向量一般用粗体小写字母或粗体希腊字母表示,如 等(有时候也会用箭头来标识,如
),其元素记作
。
向量默认为列向量,行向量需要用列向量的转置表示,例如 等。

- 物理专业视角:向量是空间中的箭头,决定一个向量的是它的长度和方向
- 计算机专业视角:向量是有序的数字列表
- 数学专业视角:向量可以是任何东西,只要保证两个向量相加以及数字与向量相乘是有意义的即可
运算规则
向量的加法和数量乘法定义:
加法 相同维数的向量之间的加法为:

数量乘法 任意的常数 和向量的乘法为:
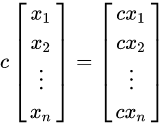
在给定数 及向量
的情况下

张成空间
张成空间是向量 和
全部线性组合构成的向量集合,即:
(
在实数范围内变动)
向量空间的基
向量空间中的一组基是张成该空间的一个线性无关向量的集合。
只有当以下两个条件同时满足时,一组向量 才能成为基底。
- (当前空间中的)任意向量
都可以表示成
的形式(
为任意数)
- 并且这种表示方法是唯一的
向量空间的维数
空间的维数可以通过基向量的个数来定义
维数 = 基向量的个数 = 坐标的分量数
线性无关
当且仅当 时
成立,则
是线性无关的。
换种表达方式,线性无关是说:其中任意一个向量都不在其他向量张成空间中,也就是对所有的 和
,
均不成立。
线性变换
线性的两个条件:直线依旧是直线 和 原点保持固定.
线性的严格定义:

线性变换保持网格线平行且等距分布,并且保持原点不动。
线性变换由它对空间的基向量的作用完全决定,在二维空间中,基向量就是 和
,这是因为其他任意向量都成表示为基向量的线性组合,坐标为(x,y)的向量就是x乘以
加上y乘以
,在线性变换之后,网格线保持平行且等距分布这一性质有个绝妙的推论,向量(x,y)变换之后的结果,将是x乘以变换后的
的坐标加上y乘以变换后的
的坐标。
向量的点积
点乘,也叫向量的内积、数量积。顾名思义,求下来的结果是一个数。两个维度相同的向量,点积定义如下:

- 点积和顺序无关
- 两个向量相互垂直时,点积为0
- 两个向量方向相同时,点积为正;相反时,点积为负


向量的叉积
叉乘,也叫向量的外积、向量积。顾名思义,求下来的结果是一个向量。
- 向量的叉积不满足交换律
对偶向量
给定一个向量,如果存在这样一个映射,它把给定的向量映射为一个实数,就说这个映射是对偶向量。例如一个n维行向量(a1,a2...an),它既可以理解为行向量,也可理解为某种映射,该映射把给定的n维列向量(b1,b2...bn)(矢量)映射为实数k,k=a1b1+a2b2+...anbn,即矩阵的乘积。则这个映射满足对偶向量的定义,因此行向量(a1,a2...an)是对偶(b1,b2...bn)的对偶向量。
矩阵(matrix)相关
矩阵的定义
矩阵是一个二维数组,其中的每一个元素由两个索引(而非一个)所确定,一般用粗体的大写字母表示,比如: 。
矩阵 中的第
行第
列的值,称为
的
元素;当矩阵行数和列数相同时,称为方阵。
矩阵就是映射,或者说是向量运动的描述。
将 维向量
乘以
矩阵
,能得到
维向量
。也就是说,指定了矩阵
,就确定了从向量到另外一个向量的映射。
两个矩阵相乘的几何意义就是两个线性变换相继作用。


矩阵运算
加法:
只要两个矩阵的形状一样,就可以把两个矩阵相加。两个矩阵相加是指对应位置的元素相加,比如 ,其中
。
乘法:
两个矩阵 和
的矩阵乘积是第三个矩阵
。为了使乘法可被定义,矩阵A的列数必须和矩阵B的行数相等。如果矩阵
的形状是
,矩阵
的形状是
,那么矩阵
的形状是
。例如
具体地,该乘法操作定义为:
矩阵乘积服从分配律:
矩阵乘积也服从结合律:
矩阵乘积不满足交换律:的情况并非总是满足
矩阵乘积的转置有着简单的形式:
矩阵的秩
矩阵的秩,为变换后的空间的维数
核与值域
核:所有经过变换矩阵后变成了零向量的向量组成的集合,通常用Ker(A)来表示。
值域:某个空间中所有向量经过变换矩阵后形成的向量的集合,通常用R(A)来表示。
维数定理
对于 矩阵
,有
其中 表示X的维度。
列空间
矩阵 的列空间为所有可能的输出向量
构成的集合,换句话说,列空间就是矩阵所有的列所张成的空间。
所以更精确的秩的定义是列空间的维数;当秩达到最大值时,意味着秩和列数相等,也即满秩。
零向量
变换后落在原点的向量的集合被称为矩阵的‘零空间’或者‘核’。
- 零向量一定在列空间中
- 对于一个满秩变换来说,唯一能在变换后落在原点的就是零向量自身
- 对于一个非满秩的矩阵来说,它将空间压缩到一个更低的维度上,变换后的已给向量落在零向量上,而“零空间”正是这些向量所构成的空间
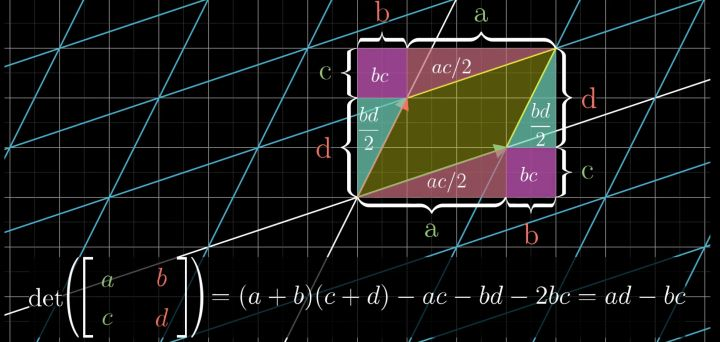
行列式
线性变换的行列式即线性变换改变面积的比例。
- 检验一个矩阵的行列式是否为0,就能了解这个矩阵所代表的变换是否将空间压缩到更小的维度上
- 在三维空间下,行列式可以简单看作这个平行六面体的体积,行列式为0则意味着整个空间被压缩为零体积的东西,也就是一个平面或者一条直线,或者更极端情况下的一个点
- 行列式的值可以为负,代表空间定向发生了改变(翻转);但是行列式的绝对值依然表示区域面积的缩放比例
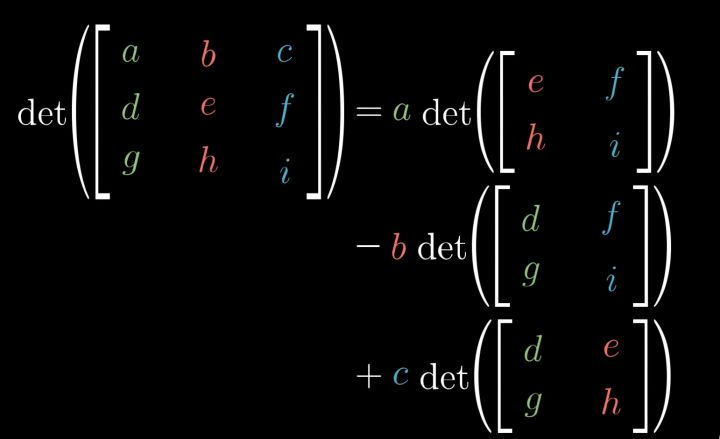
奇异矩阵
行列式为零的矩阵
特征值和特征向量
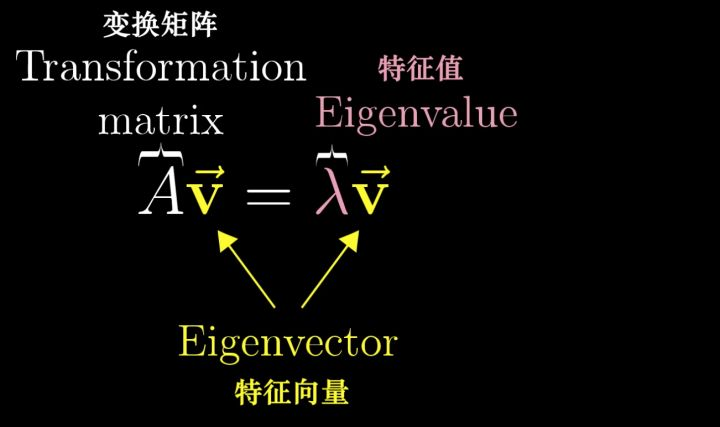
特征分解
如果说一个向量 是方阵
的特征向量,将一定可以表示成下面的形式:
为特征向量
对应的特征值。特征值分解是将一个矩阵分解为如下形式:
其中, 是这个矩阵
的特征向量组成的矩阵,
是一个对角矩阵,每一个对角线元素就是一个特征值,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列)。也就是说矩阵A的信息可以由其特征值和特征向量表示。
对于矩阵为高维的情况下,那么这个矩阵就是高维空间下的一个线性变换。可以想象,这个变换也同样有很多的变换方向,我们通过特征值分解得到的前N个特征向量,那么就对应了这个矩阵最主要的N个变化方向。我们利用这前N个变化方向,就可以近似这个矩阵(变换)。
总结一下,特征值分解可以得到特征值与特征向量,特征值表示的是这个特征到底有多重要,而特征向量表示这个特征是什么。不过,特征值分解也有很多的局限,比如说变换的矩阵必须是方阵。
奇异值分解
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,比如说有N个学生,每个学生有M科成绩,这样形成的一个N * M的矩阵就不可能是方阵,我们怎样才能描述这样普通的矩阵呢的重要特征呢?奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
分解形式:
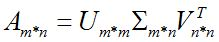
假设A是一个M * N的矩阵,那么得到的U是一个M * M的方阵(称为左奇异向量),Σ是一个M * N的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值),VT(V的转置)是一个N * N的矩阵(称为右奇异向量)。
LU分解
给定矩阵A,将A表示成下三角矩阵L和上三角矩阵U的乘积,称为LU分解。
转置矩阵
对于矩阵A,将其行列互换得到的矩阵,称为A的转置矩阵,记为 。
矩阵的转置是以对角线为轴的镜像,这条从左上到右下的对角线被称为主对角线(main diagonal)。
单位矩阵
方阵中,如果除了对角线(从左上到右下)上的元素为1,其余元素都为0,则该矩阵称为单位矩阵,记为 。
表示
阶单位矩阵。
单位矩阵表示的映射是“什么都不做”的映射。
逆矩阵
A逆乘以A等于一个‘什么都不做’的矩阵。
- 一旦找到A逆,就可以在两步同乘A的逆矩阵来求解向量方程
- 行列式不为零,则矩阵的逆存在
零矩阵
所有元素都为0的矩阵称为零矩阵,记为 。
零矩阵表示的映射是将所有的点都映射到原点的映射。
对角矩阵
在方阵中,对角线(从左上到右下)上的值称为对角元素。
非对角元素全部为0的矩阵称为对角矩阵。
对角矩阵表示的映射是沿着坐标轴伸缩,其中对角元素就是各坐标轴伸缩的倍率。
张量(tensor)
在某些情况下,我们会讨论坐标超过两维的数组。一般的,一个数组中的元素分布在若干维坐标的规则网络中,我们称之为张量。
一阶张量可以用向量表示,二阶张量可以用矩阵表示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号