

32-探索堆表创建聚集索引后物理存储位置是否改变
一、总结
1、这里说的堆表指的是组织结构是堆结构的表,也就是没有聚集索引的表(创建聚集索引后,组织结构变成了B+Tree结构)。
2、这里演示的数据库环境是SQLServer2016 RTM。
二、探索步骤
1、准备数据

--1.创建堆表 create table person(id int not null,name nvarchar(50),age int) --2.随机插入7条数据 insert into customer..person values(9,'jack',20) insert into customer..person values(4,'rose',16) insert into customer..person values(7,'wade',37) insert into customer..person values(2,'jame',27) insert into customer..person values(6,'black',16) insert into customer..person values(1,'feide',36) insert into customer..person values(8,'ted',19) insert into customer..person values(3,'hude',49)
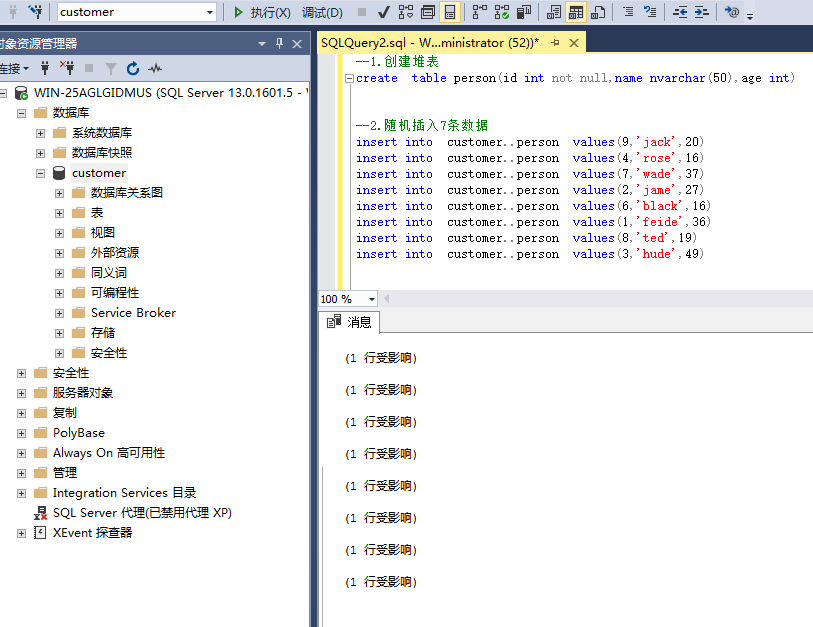
2、查看数据顺序
注:发现数据和插入时的顺序一致
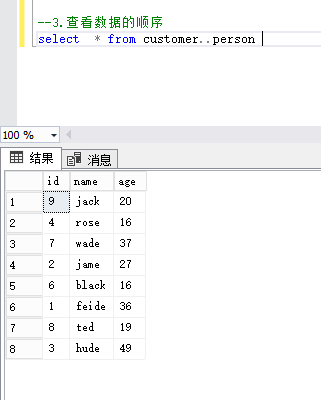
3、查看该表具体的page页
dbcc ind(customer,person,-1)
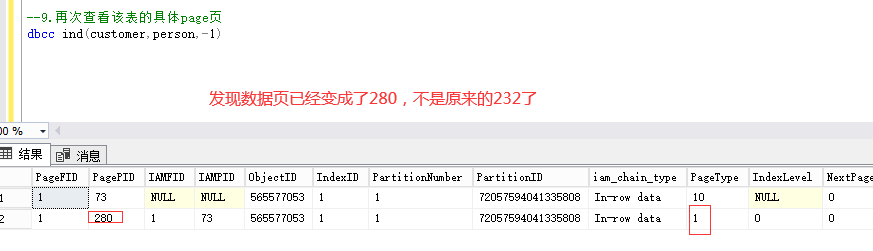
注:由下图可以看出该表所在的数据页编号是232
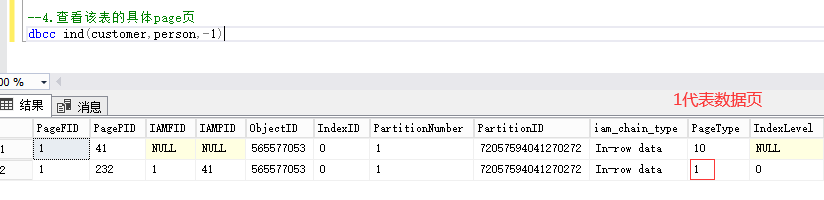
4、查看该页上具体的数据
dbcc traceon(3604)
dbcc page(customer,1,232,2)
注:从下面的结果可以看出在page页里面的存储时按照我们插入表的顺序存储的

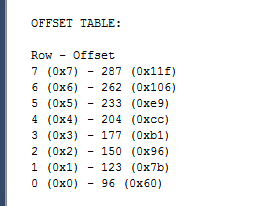
5.我们再使用winhex打开库的数据文件查看一下该页的数据存储
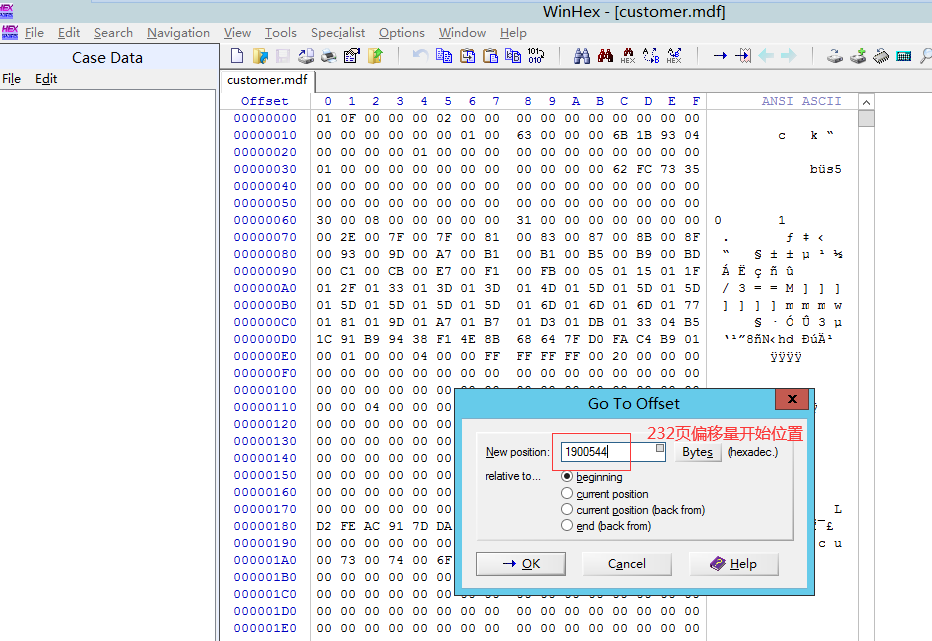
我们知道SQLServer数据库每页存储的大小是8kb,也就是8192字节,所以page为232的偏移量的开始位置就是232*8192=1900544
该页的结束位置为234*8192-1=1916927(下一页的开始偏移量减去1就是该页偏移量的结束位置)
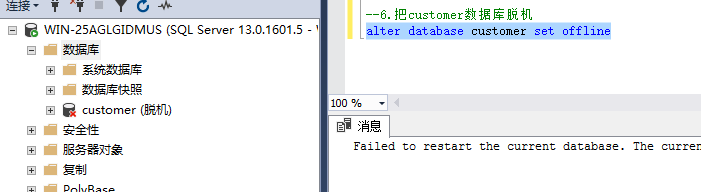
(1)先把数据库脱机(脱机后才能打开mdf文件,要不然是正在使用状态)
alter database customer set offline
(2)双击winhex.exe
(3)ALT+G查看具体的偏移量位置
注:由下图也可以看到数据在数据文件里也是按照我们插入的顺序写入的
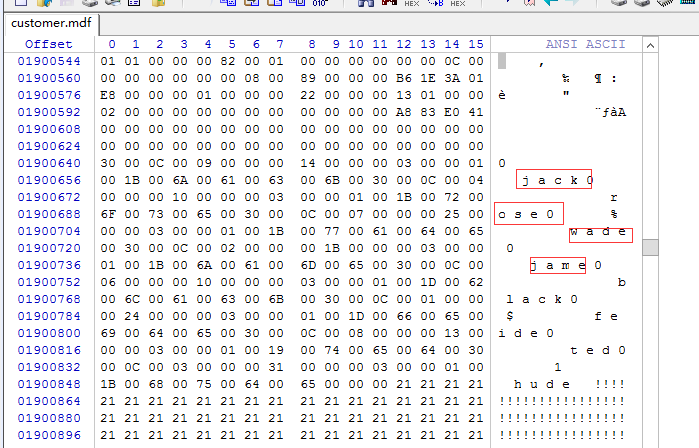
6.准备开始创建聚集索引
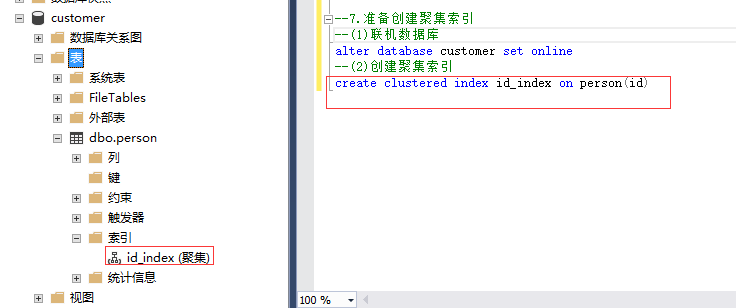
(1)先联机数据库 alter database customer set offline (2)创建id的聚集索引 create clustered index id_index on person(id)
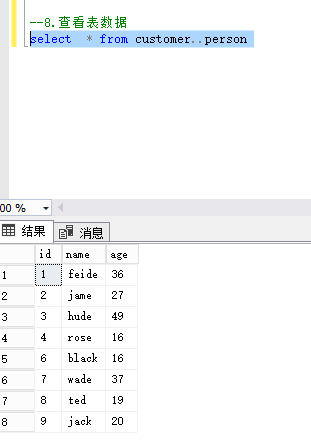
7.查看表数据,发现已经有顺序了
8、再次去查看数据页,看看物理上是否是顺序存储的
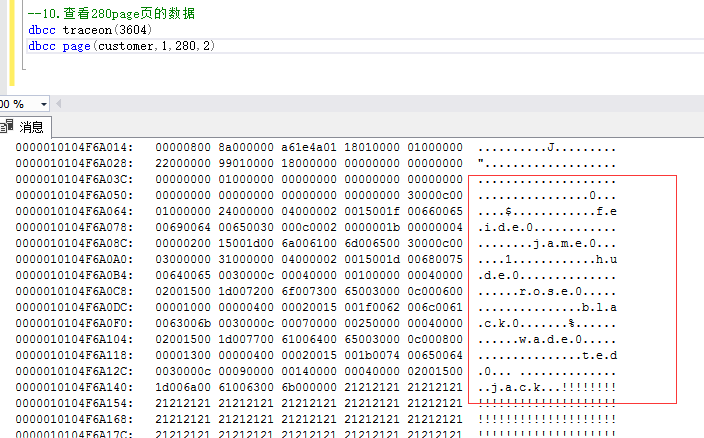
9.查看第280页的数据
发现顺序是按照id的大小排序的
10.再次用winhex查看280页的数据
开始偏移量:280*8192 = 2293760
结尾偏移量:281*8192-1=2301951
发现数据在280页里也是按照id的值顺序存储的

11.再次查看原来的232页的数据
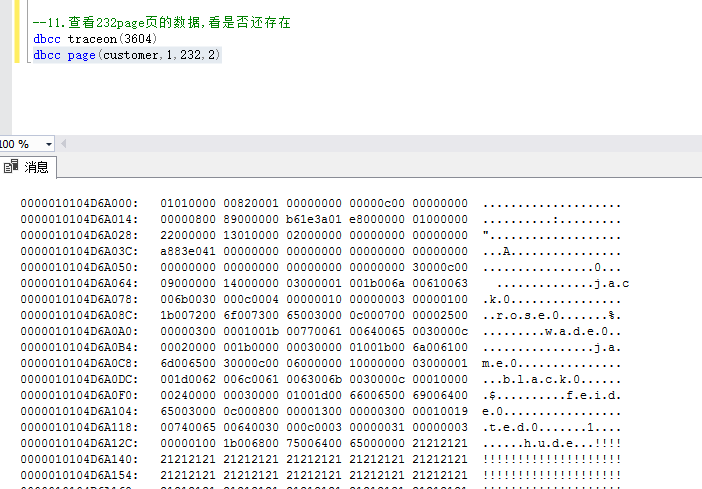
疑问:发现232的数据还是存在的,并且还是按照我们插入表的顺序存储的,但是我们通过select语句查该表的数据的时候,是去280页查找的,那这个232页的数据留着是做什么用的呢?是因为数据空间还没没有释放吗?
12.收缩一下数据文件,再次查看232页看是否还存在
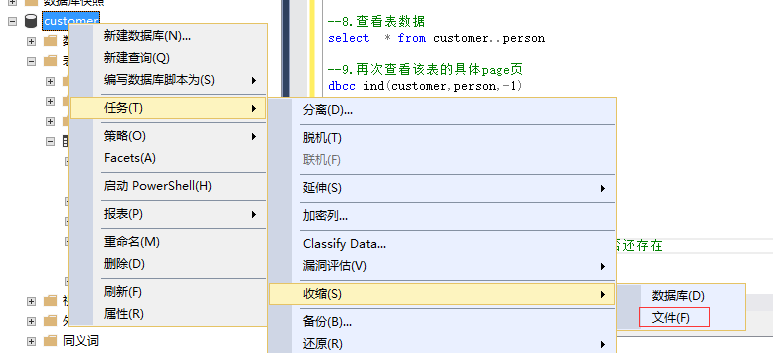
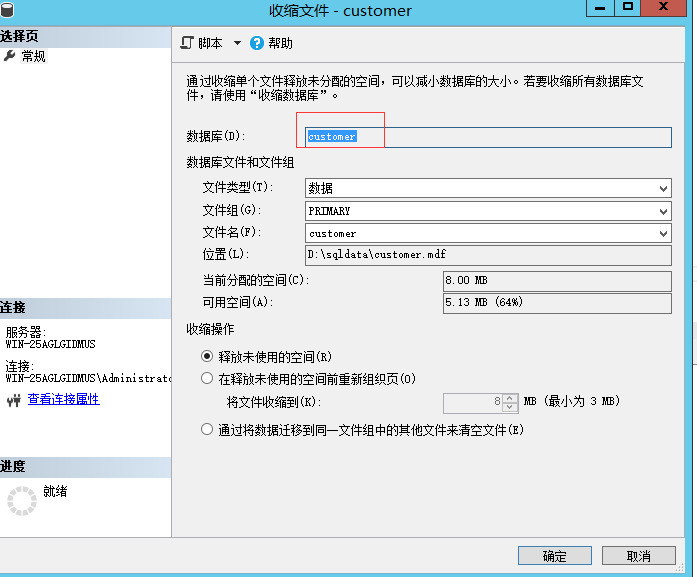
注:收缩完数据文件,查看232页的数据,还是存在的
***************************************************
如下是个人开发系统,欢迎大家体验,纯属个人爱好,想一块玩的,私信。
易本浪账:www.jialany.com
***************************************************


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构