04-SQLServer的排序规则(字符集编码)
一、总结
1.SQLServer中的排序规则就是其他关系型数据库里所说的字符集编码;
2.SQLServer中的排序规则可以在3处设置,如下:
服务器级别(实例):instances ----->安装数据库的时候设置
数据库级别:database
表列级别:columns
所以在使用SQLServer的排序规则的时候,只需要保证这三处一致,就是正确的使用方式;
3.SQLServer的排序规则不仅影响记录行的sort顺序,还影响中文显示是否乱码;
4.创建数据库时,若我们未指定排序规则,数据库就会使用实例默认的排序规则;
5.SQLServer的排序规则只影响字符型的列,例如:char,varchar,text,nchar,nvarchar,ntext,因此在查询视图sys.columns中非字符型的字段的排序规则显示是NULL;
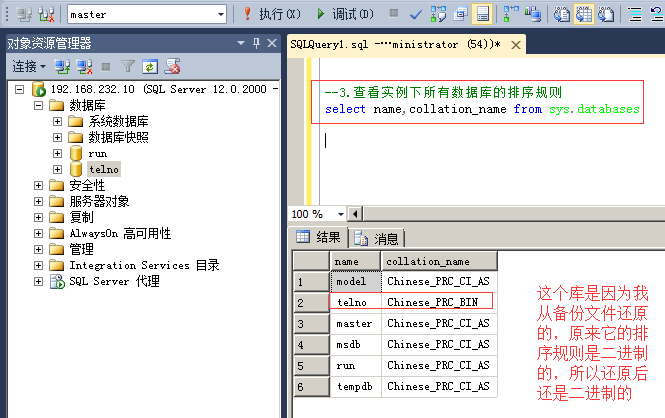
6.需要注意的是,虽然数据库的排序规则可以改,但是是有问题的,因为即使把数据库的排序规则改了,库里的表的字段的排序规则可能还是原来的,没有改,这在使用的时候,就可能会存在问题,所以数据库的排序规则尽力不要随意改动。
7.排序规则中,二进制排序的速度是最快的,因为SQLServer不用做任何调整即可使用快速、简单的排序算法。
二、查询语句
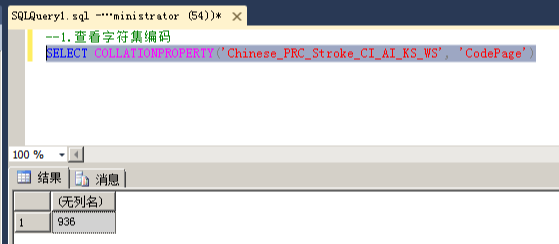
1.查询字符集编码
命令:SELECT COLLATIONPROPERTY('Chinese_PRC_Stroke_CI_AI_KS_WS', 'CodePage')
注:
(1).该数据库实例的排序规则是Chinese_PRC_CI_AS
(2).查出结果对应的字符集编码
936 :简体中文GBK
950 :繁体中文BIG5
437 :美国/加拿大英语
932 :日文
949 :韩文
866 :俄文
65001 :unicode UTF-8
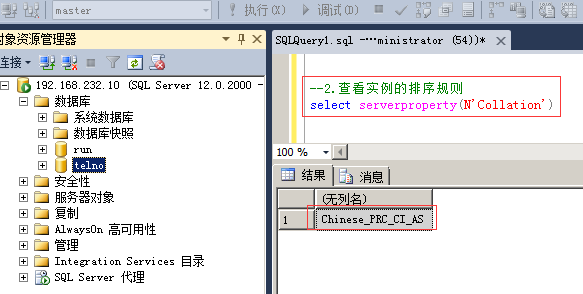
2.查看实例的排序规则
命令:select serverproperty(N'Collation')
3.查看实例下所有数据库的排序规则
命令:select name,collation_name from sys.databases
4.修改现有数据库的排序规则
命令:alter database telno collate Chinese_PRC_BIN
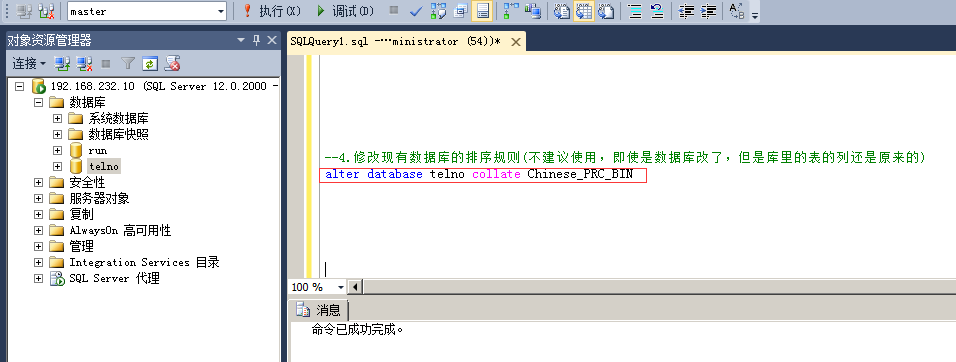
注:不建议使用,即使是数据库改了,但是库里的表的列还是原来的。
5.查询列的排序规则
命令:select name,collation_name from telno.sys.columns where collation_name is not null
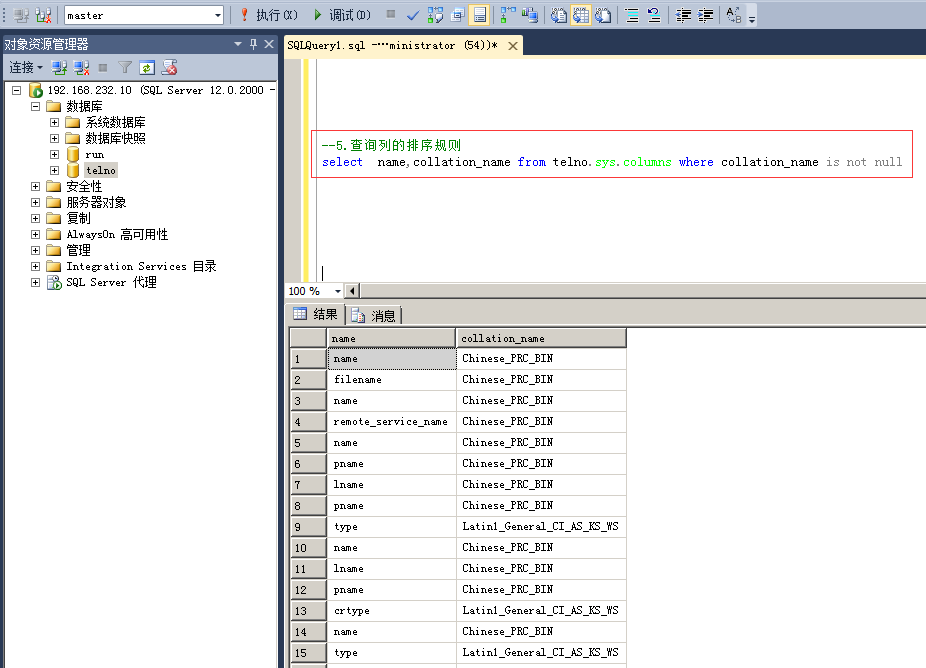
注:非字符型的字段的排序规则显示为NULL,所以要把NULL的结果过滤掉。
6.查看当前SQLServer版本支持的排序规则
命令:
select * from ::fn_helpcollations()
select * from fn_helpcollations()
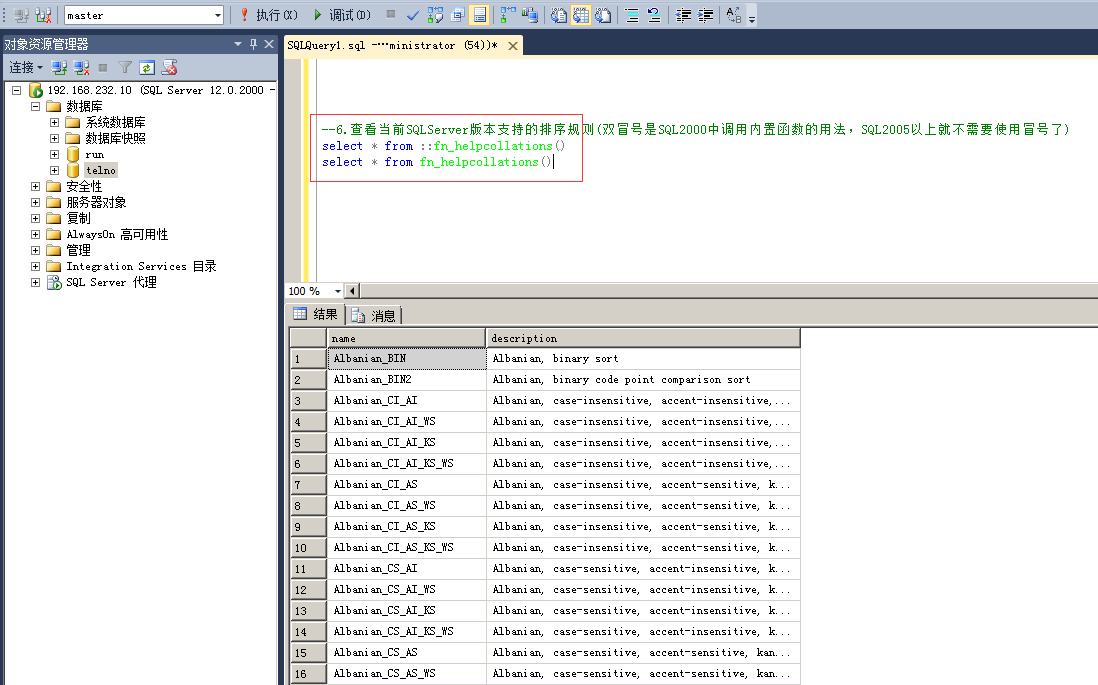
注:
(1)双冒号是SQL2000中调用内置函数的用法,SQL2005以上不需要使用冒号也能使用内置函数了;
(2)排序规则代表的意思详解
Chinese_PRC_ :指针对大陆简体字Unicode字符集的排序规则
后半部分的含义:
_BIN :二进制排序
C : case,大小写;
A :accent,重音;
I :Insensitive,不敏感,不区分;
S :sensitive,敏感,区分;
W :width,宽度
K :kanatype,假名
eg:
_CI :不区分大小写
_AS :区分重音
***************************************************
如下是个人开发系统,欢迎大家体验,纯属个人爱好,想一块玩的,私信。
易本浪账:www.jialany.com
***************************************************

 浙公网安备 33010602011771号
浙公网安备 33010602011771号