
Pytest框架(4) -- 参数化
1. 参数化
参数化设计方法就是将模型中的定量信息变量化,使之成为任意调整的参数。对于变量化参数赋予不同数值,就可以得到不同大小和形状的零件模型。(比如我们去测试搜索功能,搜索不同的数据,其他步骤一样的,搜索内容不断变化,我们可以让搜索词以变量方式传递进去,搜索词搜索结果都是对应的两个变量。还有比如登录的测试,可能很多种数据账号密码)。
pytest允许在多个级别启用测试参数化:
- pytest.fixture() 允许fixture有参数化功能(后面讲解)
- @pytest.mark.parametrize 允许在测试函数或类中定义多组参数和fixtures
- pytest_generate_tests 允许定义自定义参数化方案或扩展(拓展)
1.1 参数化场景
只有测试数据和期望结果不一样,但操作步骤是一样的测试用例可以用上参数化;
可以看看下面栗子
2. 单参数
测试用例中需要传递一个参数进去,需要验证一个信息。
把这些要转递的参数放在一个列表里面。
import pytest
search_list = ['appium'] # 列表里面传参对应变量,多少个参数对应多少用例。变量单个里面参数也是单个
# 定义一个装饰器,实现参数化的功能。
# 第二个参数需要放一个数据的序列,可以是列表或者元组。
# 在下面装饰器中,第一个参数名字要跟下面函数参数名称一一对应。
@pytest.mark.parametrize('name',search_list) # 这个装饰器实现了参数化功能。第一个变量名字要跟参数名称一致
def test_search(name):
assert name in search_list
打印返回: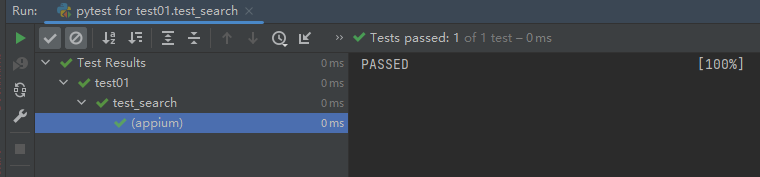
列表中多参数,对应多条测试用例,一个参数对应一个对勾代表一条测试用例
import pytest
search_list = ['appium','selenium','pytest',] # 定义一个列表,也就是第二个参数
# 1. 定义一个装饰器,实现参数化的功能。
# 2. 第二个参数需要放一个数据的序列,可以是列表或者元组。
# 3. 第一个参数是变量名字,名字要跟下面函数参数名称一一对应。
@pytest.mark.parametrize('name',search_list) # 这个装饰器实现了参数化功能。第一个变量名字要跟参数名称一致
def test_search(name):
assert name in search_list
打印返回: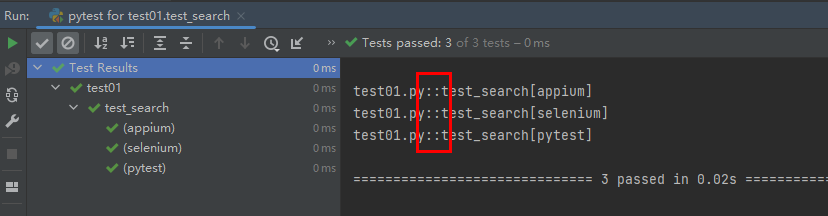
上面::为pytest的分隔符,不同的层级之间都会加上,比如模块::类名::方法名 这样。
3. 多参数
需要验证多个信息,把代码里面需要变化的多个参数都给它抽离出来。
多参数也是把参数放在一个列表/元组里面,因为传递的数据是多个,所以放在一个序列里面,可以包在元组里面或者列表里面。
import pytest
# 1. 参数化的名字,要与方法中的参数名一一对应,顺序也要保持一致。
# 2. 如果是多个变量,那么数据列表中是一个嵌套元素,嵌套元素的元素,就是和前面的参数一一对应。
# 3. 如果传递多个参数的话,每组数据放在列表/元组中,列表中嵌套列表 / 元组,每组数据逗号隔开。只要参数一一对应即可。
# 4. 第一个位置放参数,多个参数逗号隔开,放在一个字符串里。
@pytest.mark.parametrize('test_input,expected',[('3+5',8),('2+5',7),('7+5',12)])
def test_mark_more(test_input,expected): # 第一个参数为传递进来的参数,第二个参数为预期结果参数
assert eval(test_input) == expected # eval是个表达式,用过字符转里面的表达式转化为实际的表达式
注意理解,注意符号与对应关系。
4. 用例重命名
用例重命名:添加ids参数。
用例默认名称为参数的值或者数据(可以参考上面的返回)。
重命名通过添加一个参数叫ids,相当与给测试用例重新起一个名字,注意参数的位置。
ads个数要与传递的参数个数一致否则会报错。
import pytest
# 1. 默认是通过提供的参数的值进行命名的。
# 2. 通过添加ids可以为测试用例重新命名。
# 3. ids 的个数 == 传递的数据个数。 即下面的个数要匹配,多了会执行失败。
@pytest.mark.parametrize('test_input,expected',[('3+5',8),('2+5',7),('7+5',12)],ids = ["number1","number2","number3"])
def test_mark_more(test_input,expected):
assert eval(test_input) == expected
返回查看: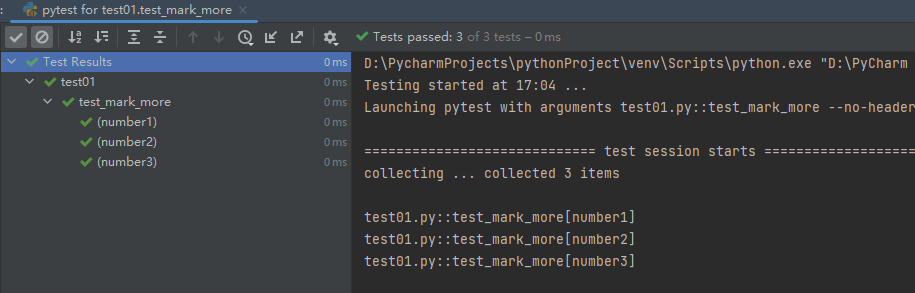
4.1. 用例中文命名报错问题
先看问题
原因:
主要原因是pytest这个nodeid没有兼容中文字符编码的问题。主要原因是pytest这个nodeid没有兼容中文字符编码的问题。可以通过在conftest.py中加上一个钩子函数修复这个问题。可以通过在conftest.py中加上一个钩子函数修复这个问题。把这段代码,写在conftest.py文件中就好,如果没有这个文件,就创建一个。
注意!!!!这个conftest.py文件的位置有一定要求:放在你的py测试用例同级,或者上级,这样才能自动识别到。
上代码(下方直接复制使用即可)~~~~
def pytest_collection_modifyitems(items):
"""
处理中文的unicode显示问题
:return:
"""
for item in items:
item.name = item.name.encode("utf-8").decode("unicode_escape")
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
下图1位置放上面代码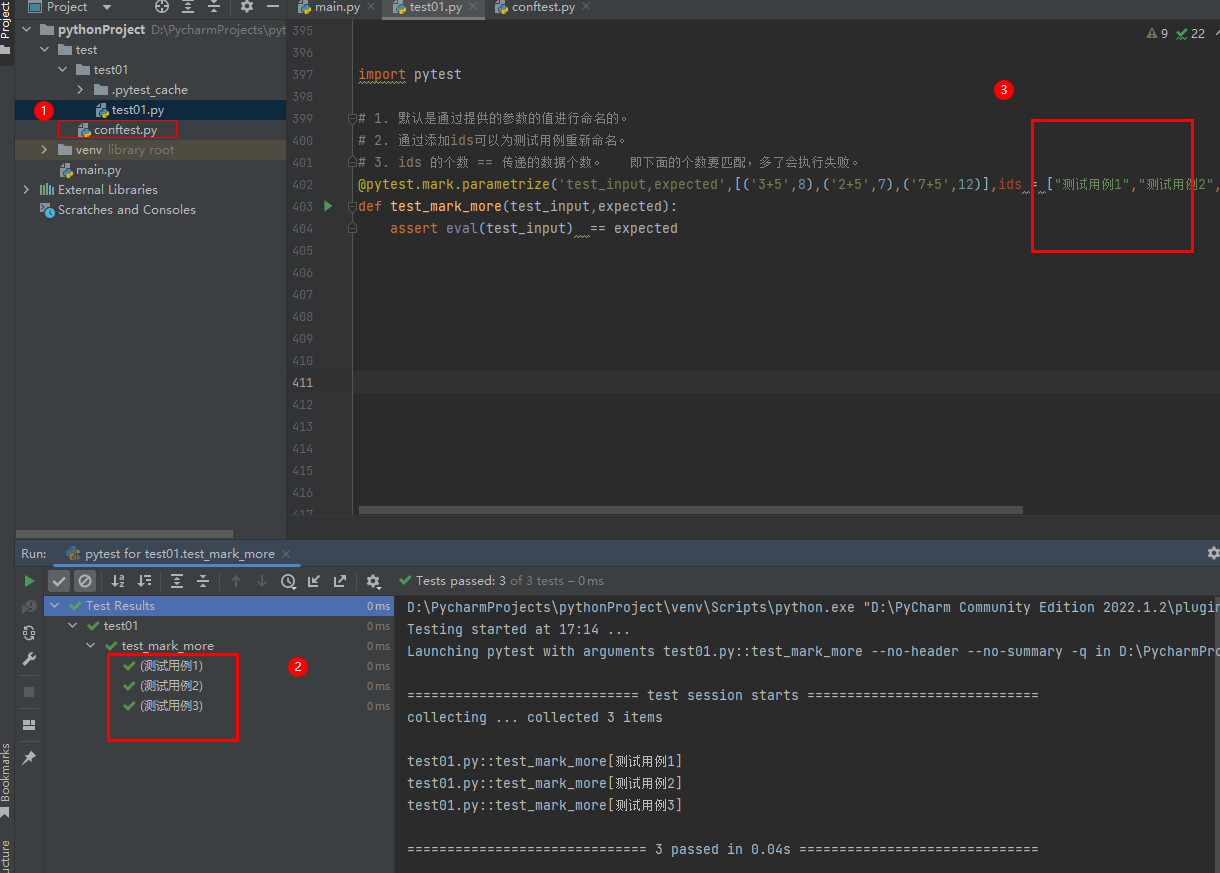
解决上面报错问题~~~~~~!!!!!!!!!!!
5. 笛卡尔积
数学里面的词,
看下下面理解:
比如我们有两个集合a集合和b集合,在集合a和集合b分别取一个元素,组成有序的数据对。把这些有序的数据对作为一个新的元素,他们的全体的集合称之为集合a和集合b的值积也就是笛卡尔积。3*3种组合,相当于全量测试,所有的情况与组合都列出来,进行测试。
下面上代码~~~~~~~,代码形式
两个列表,9种全组合。
import pytest
@pytest.mark.parametrize("wd",["appium","selenium","pytest"])
@pytest.mark.parametrize("code",["utf-8","gbk","gd2312"])
def test_dksj(wd,code):
print(f"wd:{wd},code:{code}")
执行返回: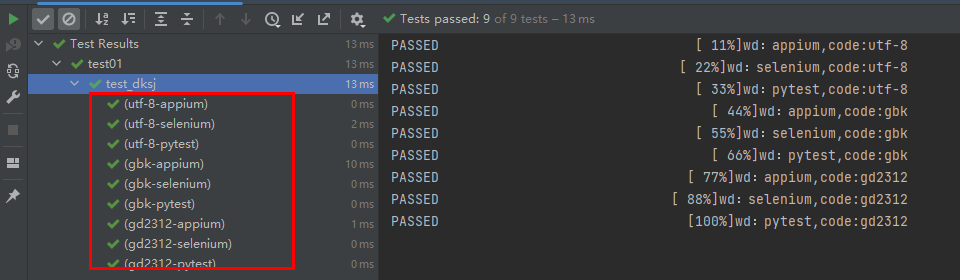
更多学习,往下讲继续补充。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号