
python---内置库re
1.前言
这节学习可以操作正则表达式的内置库:re。
首先了解正则表达式的概念,之后在学re模块来操作正则表达式的这些方法。
re库是比较常用的内置库。
2. 概念
在处理字符串的时候,经常我们会找一些复杂规则的一些字符串的需求。
正则表达式就是用来描述这些规则的工具,正则表达式就是记录文本规则的一些代码。
使用正则表达式可以用来查找符合某些复杂规则的一些字符串。
3.使用场景
工作当中一般在处理这种复杂的字符串的时候,会总到这个正则表达式。
比如:处理一些日志,对日志的特定内容过滤出来进行分析。
4.在python中使用正则表达式
在python中要使用正则表达式,需要把它当作模式字符串。
为了避免使用过多的转义符号,直接使用原生字符串来进行表示,原生字符串:即在字符串前面去加上r,加上之后就被当成普通的一个字符。
5. 使用re模块实现正则表达式操作
re是内置库,需要导入。
5.1正则表达式转换对象
首先看第一个方法:可以将字符串转换为正则表达式对象。
patter就是一个正则表达式,这个正则表达式传入到这个complete这个方法当中之后,最终会得到prog,这个prog就是我们的正则对象。
import re # 匹配包含 hogwarts 的表达式 pattern = r"hogwarts" # 转换为正则对象.(正则对象要经常用可以用这一步,不是可以省略这一步) prog = re.compile(pattern) # 通过re调用compile这个方法,然后再把定义的正则表达式再传进来。
5.2 匹配字符串
匹配字符串可以用到3个方法:(如下图中)
这3个方法在传递参数是一样的,都需要把正则对象传进去,要匹配的字符串传进去,最后传一个flag。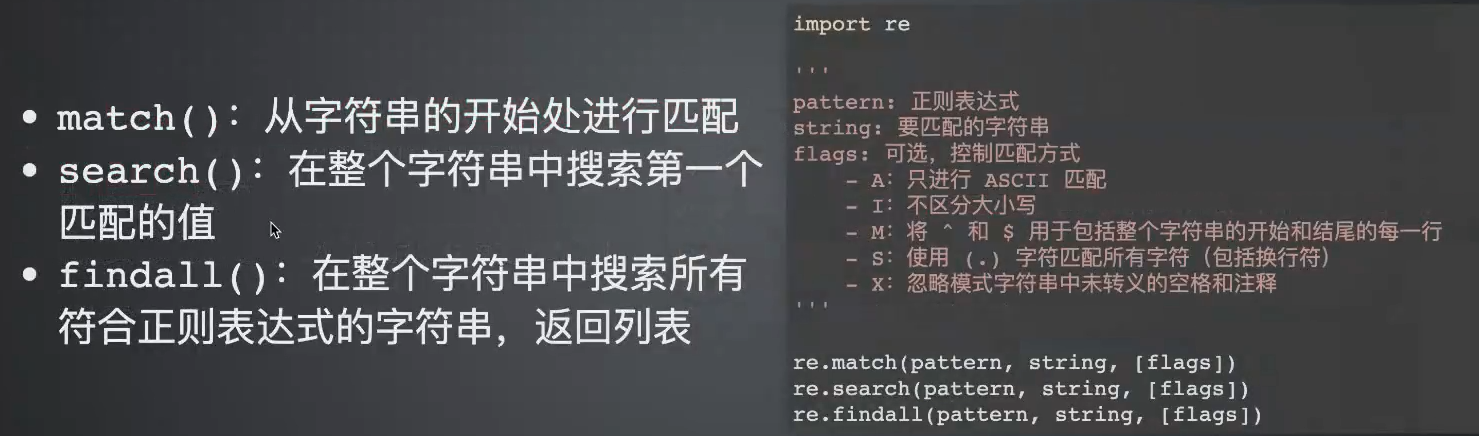
第一个方法:match()
import re # 匹配以 hog 开头的字符串 pattern = r"hog\w+" s1 = "Hogwarts is a magic school" # match方法从字符串的开始出进行匹配,匹配成功会返回一个match对象。 # 第三个参数,利用re去调用I,这样就会不区分大小写 match1 = re.match(pattern,s1,re.I) print(match1) # 提取具体信息 print(f"匹配值的起始位置为:{match1.start()}") # 调用一个start方法 print(f"匹配值的结束位置为:{match1.end()}") # 调用一个end方法 print(f"匹配位置的元祖为:{match1.span()}") # span方法,调用起始位置组成的元祖 print(f"要匹配的字符串为:{match1.string}") # 调用string这个属性 print(f"匹配的数据为:{match1.group()}") # 调用group这个方法 # 开头不是以hog开头,返回为None s2 = "I like hogwarts" match2 = re.match(pattern,s2,re.I) print(match2)
返回: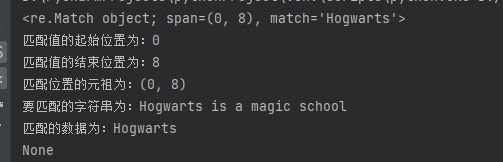
第二个方法:search()
search方法在 整个字符串中去搜索 第一个匹配的值。
类似上面,现在可以搜索到值了。
import re pattern = r"hog\w+" s2 = "I like hogwarts" match2 = re.search(pattern,s2,re.I) print(match2)
返回:
第三个方法:findall()
它可以在字符串中搜索到 所有的能够符合我们的正则表达式的 字符串。
impor re # 匹配以 hog 开头的字符串 pattern = r"hog\w+" # 返回1个 s1 = "Hogwarts is a magic school" match_list1 = re.findall(pattern,s1,re.I) print(match_list1) # 返回2个 s2 = "I like hogwarts hogwarts" match_list2 = re.findall(pattern,s2,re.I) print(match_list2)
返回: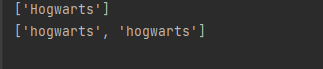
5.3 匹配字符串
第一种:sub(),字符串替换
方法一:字符串替换
可以把匹配到的字符串替换成其他字符串。
替换需要用到sub这个方法。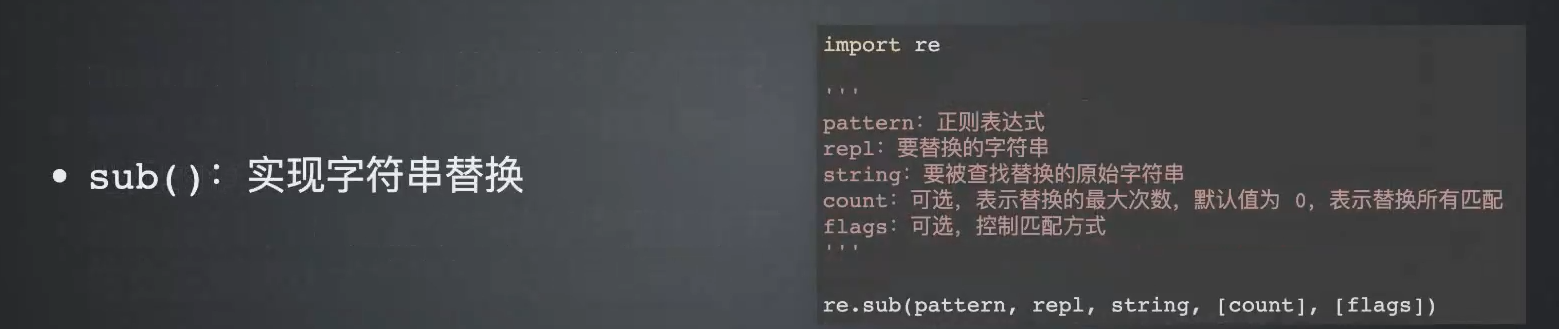
代码示例:
import re # 匹配手机号码 pattern = r"1[34578]\d{9}" # 用sub方法进行替换 s1 = "中奖号码 123456 ,联系电话 15611111114" result = re.sub(pattern,'1xxxxxxxx14',s1) print(result)
返回: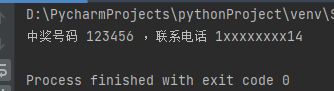
第二种:spiit(),分割字符串
分割字符串,
这是实际工作中很实用的一个技能!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!__________________________

看下面栗子,分割url。
import re p = r"[?|&]" # 用?和 & 进行分割 url = "https://www.baidu.com/s?wd=%E9%9C%8D%E6%A0%BC%E6%B2%83%E5%85%B9&rsv_spt=1&rsv_iqid=0xa21846cc000b9d31&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=85070231_1_hao_pg&rsv_enter=0&rsv_dl=tb&rsv_sug3=16&rsv_sug1=5&rsv_sug7=100&rsv_btype=i&prefixsug=%25E9%259C%258D%25E6%25A0%25BC%25E6%25B2%2583%25E5%2585%25B9&rsp=1&inputT=10226&rsv_sug4=10956" # 调用split方法,把参数穿进去 r = re.split(p,url) print(r) # 打印分割之后的结果
打印返回结果:
打印得到一组组参数。完成参数的拆分!!!!!!!!!!!!!!!!!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号