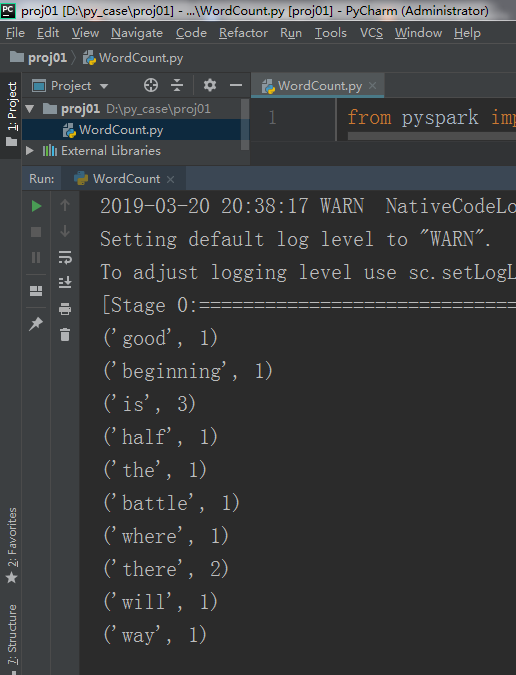
使用Pycharm开发WordCount程序
创建工程
设置虚拟机Python解释器环境
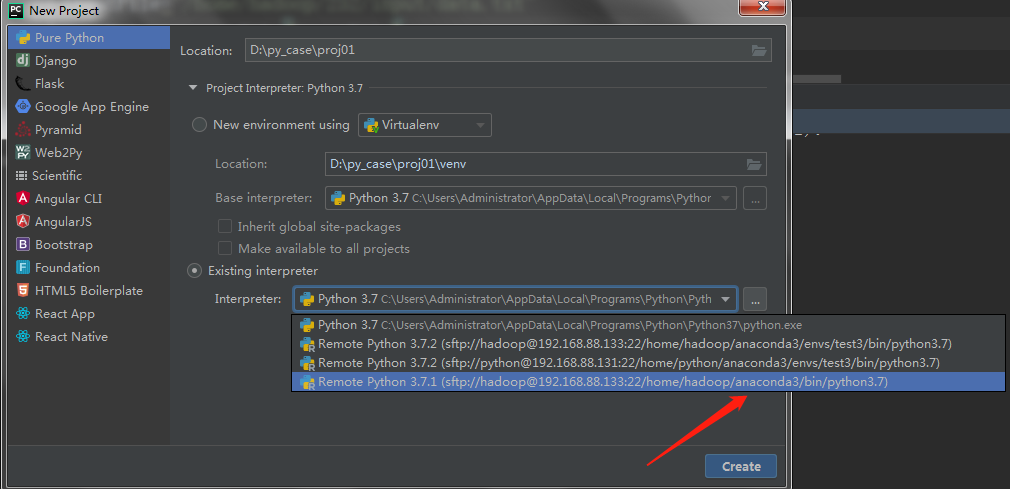
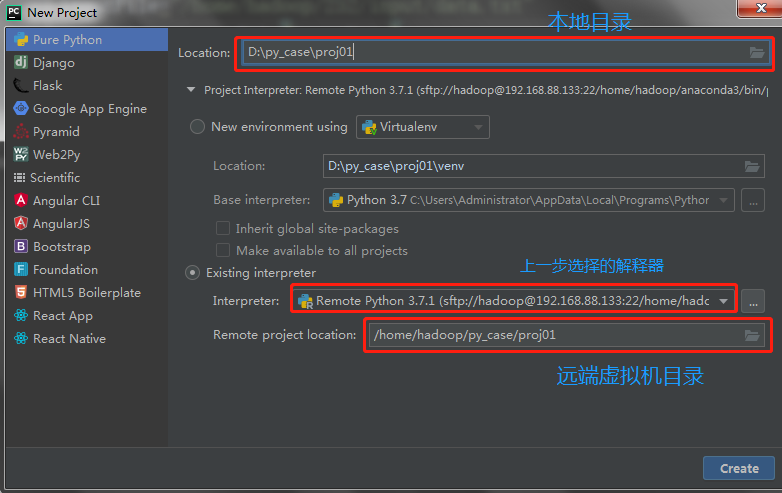
注意:解释器应该选择:/home/hadoop/anaconda3/bin/python3.7,这样依赖的库都有了。
创建一个python文件,取名为WordCount
开发WordCount程序
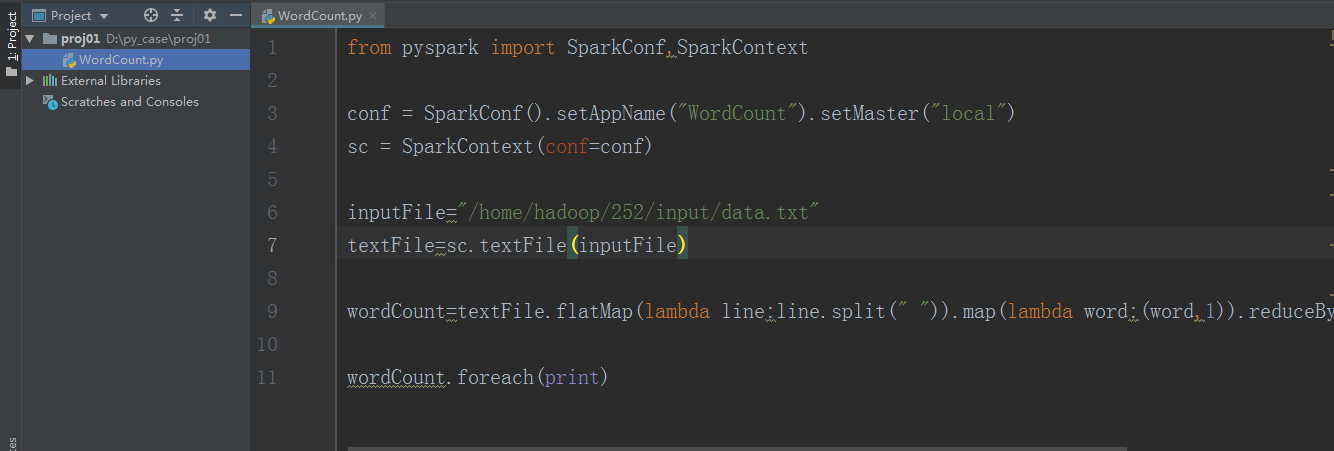
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("WordCount").setMaster("local")
sc = SparkContext(conf=conf)
inputFile = "/home/hadoop/252/input/data.txt"
textFile = sc.textFile(inputFile)
wordCount = textFile.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda x, y: x + y)
wordCount.foreach(print)
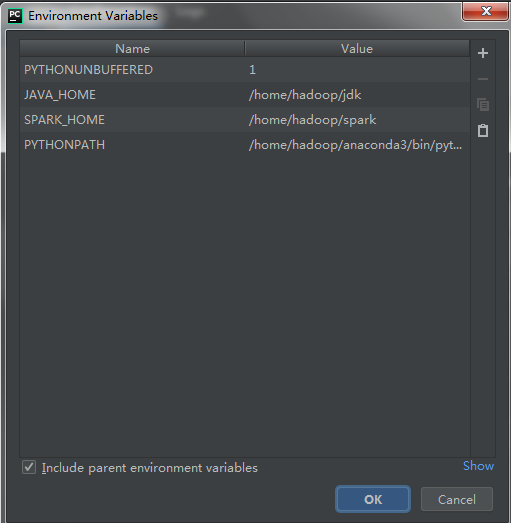
设置配置Run的参数
【Run】→【Edit Configurations】配置Environment Variables 参数
运行程序
在代码中【右键】--【Run ‘Wordcount’】