pyspark的用法
pyspark -h 查看用法
pyspark -h
Usage: pyspark [options]
常见的[options] 如下表:

输入pyspark -h 查看各参数的定义

查看sc变量
-
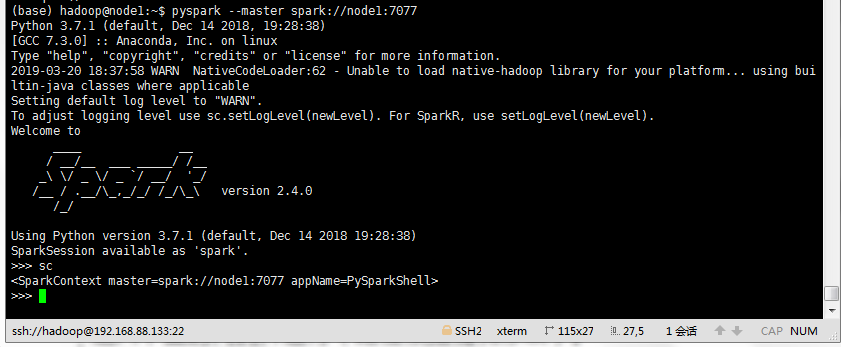
不指定--master时
pyspark (查看sc变量) sc

-
指定--master时
pyspark --master spark://node1:7077 (查看sc变量) sc
用pyspark开发一个WordCount程序
输入下面的代码并运行(路径根据情况修改)。
-
在本地创建一个文件:/home/hadoop/252/input/data.txt (hadoop是本地用户名,252表示文件名,两个值请根据情况修改)。此路径也可以换为hdfs的路径。
data.txt文件中的内容是:
a good beginning is half the battle where there is a will there is a way -
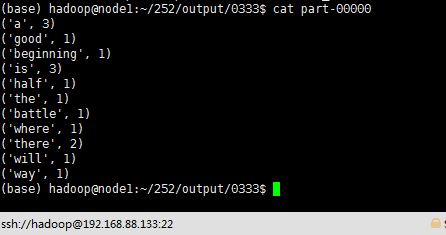
一行代码实现WordCount
sc.textFile("/home/hadoop/252/input/data.txt").flatMap(lambda line: line.split(" ")).map(lambda word : (word,1)).reduceByKey(lambda x,y : x+y).saveAsTextFile("/home/hadoop/252/output/0222")
-
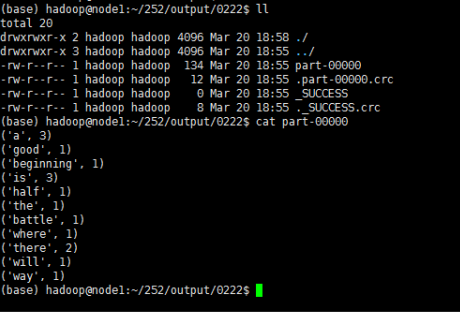
多行代码实现WordCount(单步)
rdd1 = sc.textFile("/home/hadop/252/input/data.txt") #延时读取数据 rdd1.collect() #查看结果(列表方式)

rdd2 = rdd1.flatMap(lambda line: line.split(" ")) #将每句话进行分词,再整合到一个列表
rdd2.collect() #查看结果(列表方式)

rdd3 = rdd2.map(lambda word : (word,1)) #每个单词记一次数,将单词和1构成元组
rdd3.collect() #查看结果(列表方式)

rdd4 = rdd3.reduceByKey(lambda x,y:x+y) #再将value进行累加,把相同的Key的value进行累加
rdd4.collect() #查看结果(列表方式)

rdd4.saveAsTextFile("/home/hadoop/252/output/0333") #保存到指定目录,此目录预先不能存在
最后,输出查看目录中的内容