搭建Spark环境(Standalone部署模式)
搭建Spark的单独(Standalone)部署模式
Standalone单独部署(伪分布或全分布),不需要有依赖资源管理器。主要学习单独(Standalone)部署中的伪分布模式的搭建。
环境
个人笔记本安装。
内存:至少4G
硬盘:至少空余40G
操作系统: 64位 Windows系统
VMware 12+
步骤
1、总体步骤如下:
- 安装前的准备

- 搭建

2、详细步骤如下
- 安装前的准备
①安装Linux
下载Ubuntu 16.04
(a)Desktop --> 桌面版,默认带了界面
ubuntu-16.04.5-desktop-amd64.iso
(b)Server --> 服务器版,默认没有带界面
ubuntu-16.04.5-server-amd64.iso
②关闭防火墙
查看防火墙状态:
$ sudo ufw status
Status: inactive
关闭防火墙:
$ sudo ufw disable
防火墙在系统启动时自动禁用
$ sudo ufw status
Status: inactive
查看防火墙状态:
$ sudo ufw status
Status: inactive
③确认openssh-client、openssh-server是否安装
$ dpkg -l | grep openssh
如果没有安装,则安装:
$ sudo apt-get install openssh-client
$ sudo apt-get install openssh-server
④设置免密登录
通过ssh-keyen生成一个RSA的密钥对
$ ssh-keygen -t rsa -P ''
公钥追加到~/.ssh/authorized_keys文件中
$ ssh-copy-id -i ~/.ssh/id_rsa.pub 主机名(如上面都node1)
测试免密码登录:
$ ssh node1
⑤安装JDK
解压到根目录:
$ tar zxvf jdk-8u144-linux-x64.tar.gz -C ~
建一个软链接(方便使用)
$ ln -s jdk-8u144-linux-x64 jdk
配置环境变量:
$ vi ~/.bashrc
(注意!等号两侧不要加入空格)
export JAVA_HOME=/home/hadoop/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
使得变量生效:
$ source ~/.bashrc
⑥安装Scala
将Scala的安装包通过Xshell、Xftp上传到Linux。
(解压)
$ tar zxvf scala-2.11.12.tgz -C ~
(创建软连接)
$ ln -s scala-2.11.12 scala
(配置环境变量)
$ vi ~/.bashrc
export SCALA_HOME=~/scala
export PATH=$SCALA_HOME/bin:$PATH
(使环境变量生效)
$ source ~/.bashrc
⑦安装Anoaconda3
上传Anaconda的安装包,执行安装。
$ sh Anaconda3-5.2.0-Linux-x86_64.sh
许可协议,按ENTER继续,显示许可协议,按q到达“是否同意”,输入yes,同意。如下图所示:
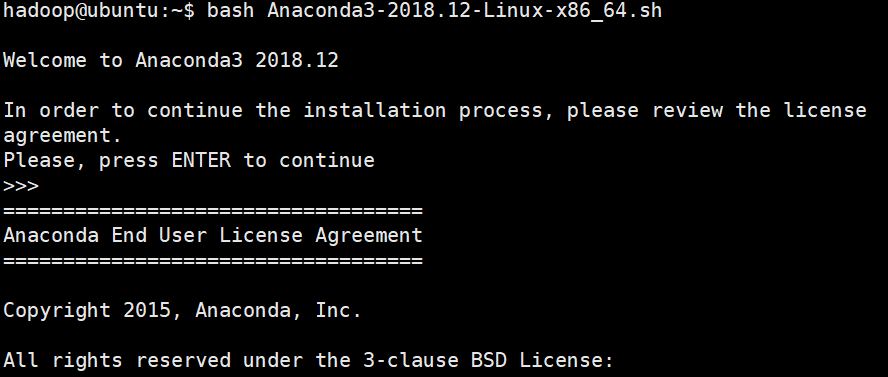
安装位置,查看文件即将安装的位置,按enter,即可安装。如下图所示:
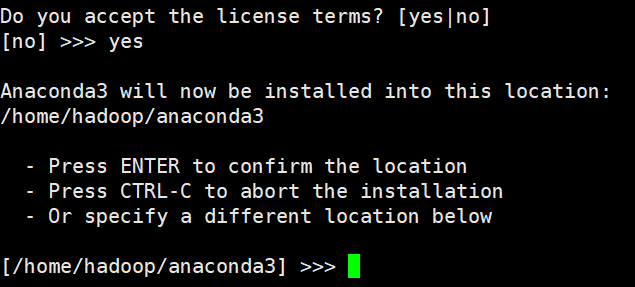
环境变量,加入环境变量,输入yes。如下图所示:
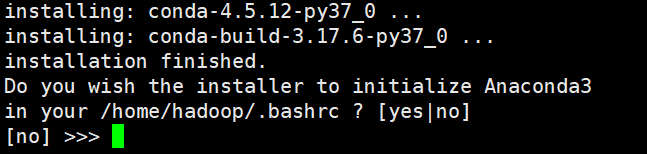
不安装VSCode,输入no。如下图所示:
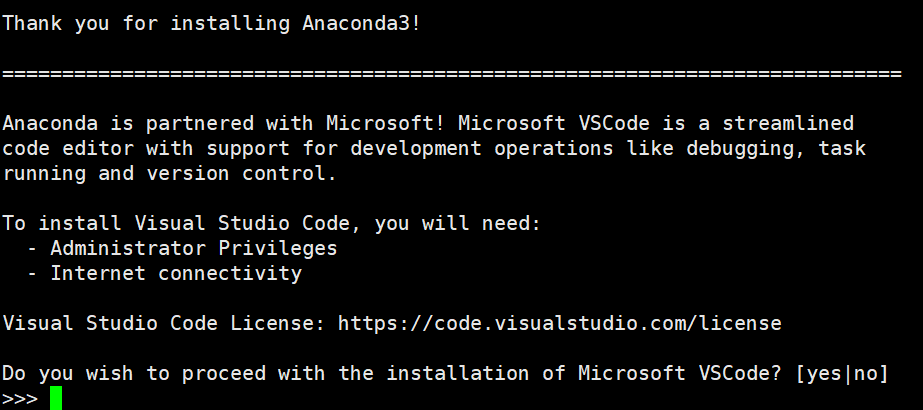
source~/.bashrc
⑧安装pyspark
$ conda install pyspark
- 搭建Spark伪分布
①安装包解压、配置环境变量
$ tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C ~
创建超链接:(便于使用)
$ ln -s spark-2.4.0-bin-hadoop2.7 spark
增加环境变量(如果已经安装过hadoop,这步可以省略,避免冲突)
$ vi ~/.bashrc
export SPARK_HOME=/home/hadoop/spark
export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
$ source ~/.bashrc
②修改配置文件
进入Spark配置文件所在目录,修改spark-env.sh文件。
$ cd ~/spark/conf
$ cp spark-env.sh.template spark-env.sh
$ vi spark-env.sh
export JAVA_HOME=/home/hadoop/jdk
export SPARK_MASTER_HOST=node1
export SPARK_MASTER_PORT=7077
#识别到python
export PYTHON_HOME=/home/hadoop/anaconda3
export PATH=$PYTHON_HOME/bin:$PATH
修改slaves文件。
$ cp slaves.template slaves
$ vi slaves
将里面在localhost改完主机名
# A Spark Worker will be started on each of the machines listed below.
#localhost
node1
③启动
$ cd ~/spark
$ sbin/start-all.sh
④验证
(a)查看进程验证
$ jps
显示如下进程:
1398 Worker
1327 Master
(b)打开网页http://[IP地址]:8080
(c)打开pyspark验证
pyspark --master spark://node1:7077
conda
-
conda简介
一个工具,用于包管理和环境管理
包管理与pip类似,管理Python的第三方库。
环境管理能够允许用户使用不同版本Python,并能灵活切换 -
conda基本命令
查看版本:
conda --version 或: conda -V创建环境:
conda create --name test创建制定python版本的环境:
conda create --name test2 python=2.7 conda create --name test3 python=3创建包含某些包的环境:
conda create --name test4 numpy scipy创建指定python版本下包含某些包的环境
conda create --name test5 python=3.5 numpy scipy删除某个环境
conda remove --name test --all列举当前所有环境:
conda info --envs conda env list进入某个环境:
conda activate test退出当前环境
conda deactivate

