对于现有的无人零售技术的调研
-
-
国外:亚马逊
-
国内:阿里、京东
-
“just walk out”概念,这个概念对超市场景来说主要是减少了两个环节:①货品扫码;②货品付款,也就是结账环节。 所谓的“无人便利店”。其实是有服务人员的,有人上货,有人做即时性的食品(奶茶等等),准确来说amazon go做的是的自动结算系统(cashierless),没有收银员, 「拿了就走」 ,系统自动识别顾客拿走的物品,自动结账。
-
解决的问题: 结账环节虽然非常关键,但对店家来说是一个鸡肋环节,因为大部分的工作都是重复化、机械化的操作,如收银的扫码,结算等。这类工作不需要有很高的技术水平就可以胜任,薪资水平一直也比较低。却需要大量员工操作,人力成本、设备成本较高; amazon go正是解决了这个环节。
-
真实意图:
- 数据收集技术,可以将消费者入店的所有行为数据进行跟踪与分析
- 希望能更切中零售的本质:出售受消费者喜爱的产品。
-
我国自动结算零售的发展历程:
-
自动结算1.0时代:自助结算机
将收银的工作转移给用户,结账的时候必须要有专人检查,否则货损问题无法解决。但专人检查效率低,提防性行为带给消费者的感受不好。
-
自动结算2.0时代: RFID
产品外贴设置好的RFID标签,顾客挑选完毕后,会到读取设备上读取自己所购买的商品,并进行支付。成本高,容易损坏。
-
自动结算2.5时代:2D视觉识别+RFID
-
无人值守3.0
RGBD成像技术:RGBD相机取代传统的2D摄像头
边缘计算:配备了边缘计算方案,开发边缘计算平台。RGBD相机通过多种接口进行深度对接,如网络、USB3.0和MIPI接口。
人体跟踪技术:打造了多相机头顶阵列传感方案,解决了多相机的时间同步、空间标定、安装施工难度大等一系列难题,从传感方案角度最大可能的保证了人体跟踪效果。 采用RGB-D跟踪技术,为物体建立三维坐标,从而彻底的解决了跟踪困难与后期识别的问题。
-
-
-
How the Amazon Go Store’s AI Works
6 core problems of "Computer Vision Complete" problem:
- Sensor Fusion
- Calibration 校准
- Person detection
- Object Recognition
- Pose estimation
- Activity Analysis
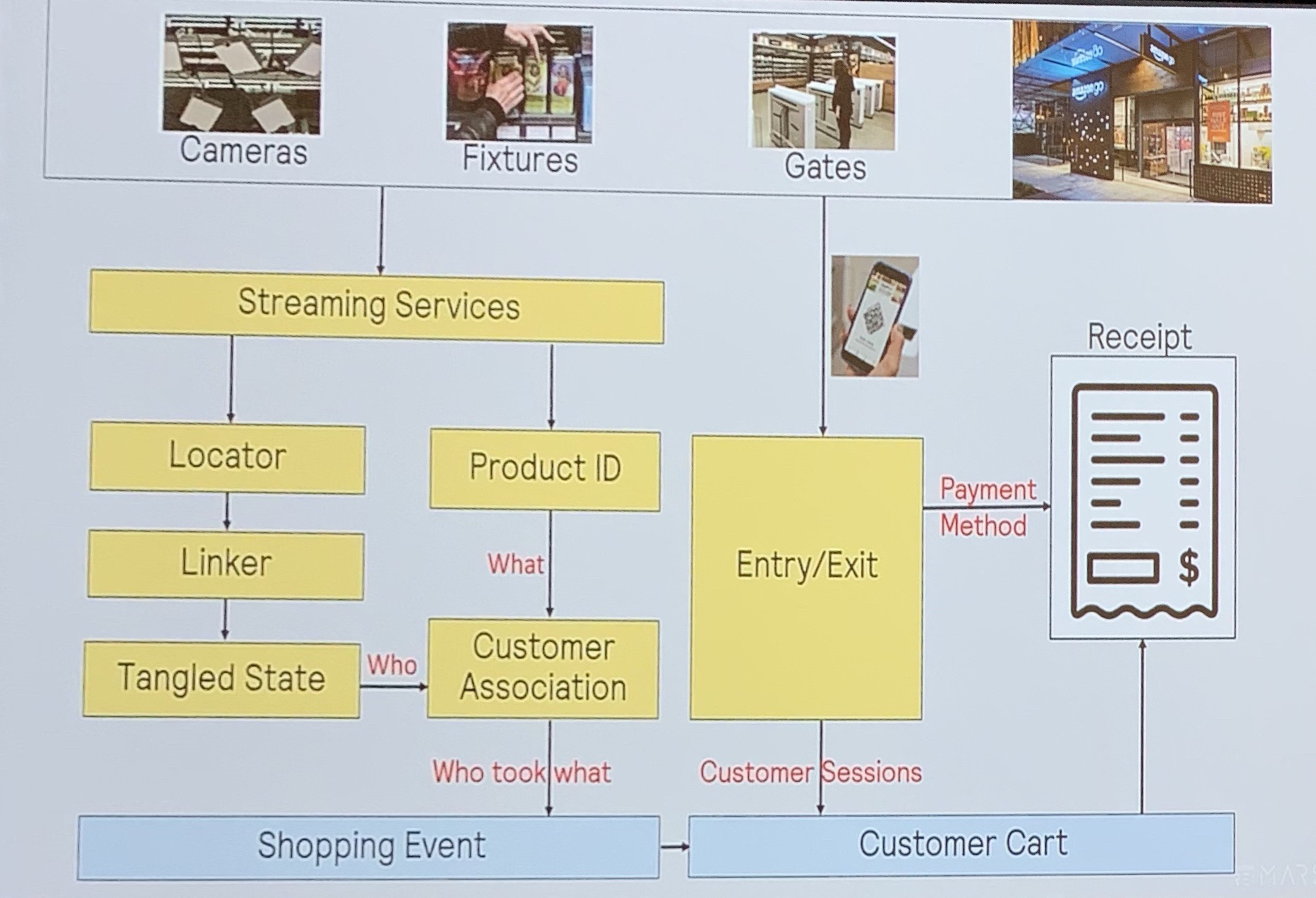
Person Identification
-
Locator
Problems: Occlusion(遮挡,人被物体遮挡), Tangled State(纠缠态,人和人太密集)
Amazon Solution: uses custom camera hardware that does both RGB video and distance calculation. They segment image into pixels, group pixels into blobs, and label each blob as person/not-person. Finally, they build a location map from the frame using triangulation of each person across multiple cameras.
-
Linker
To tracking the customers in the store
-
Disambiguating Tangled States 消除纠缠态
Mark close customers as low confidence get scheduled to be re-identified over time.
Distinguish associates(员工) from customers.
Item identification
-
Product ID detection
-
Customer association
Combining all of the information from the above to finally answer the “Who took what?” question.
-
Pose Estimation
Build a stick-figure like model of the customer from the video, because cameras look from the top down, not form an isometric view.
-
Action determination
The system needs to count all the items on the shelf rather than using a simple assumption based on space.

-
The long tail
Using simulation to build a massive training set
Streaming Services
- Video capture with compute on board to do basic preprocessing and cut down the bandwidth requirements
- Video streamer appliance on site to handle video codecs, network issues, and guarantee delivery to the cloud
- Video servers on the cloud to capture and store video in S3 and Dynamo
Entry & Exit Detection
- Mobile App to scan QR when you show up at the store. They spent a lot of time doing UX testing on this (scan with phone up or down, how to handle groups, etc.)
- Association System associates your likeness in the video to your account based on position in the store entrance when you scan the QR code
- Creation of the session happens based on the association
问题:1. 重复扫码 2. 家庭购物(group 一人支付)
Cart, Payment, and Receipts

 浙公网安备 33010602011771号
浙公网安备 33010602011771号