

在上一篇中对枚举排序的MPI并行算法进行了详细的描述和实现,算法相对简单,采用了并行编程模式中的单程序多数据流的并行编程模式。在本篇中,将对快速排序进行并行化分析和实现。本篇代码用到了上篇中的几个公用方法,在本篇中将不再做说明。
在本篇中,我们首先对快速排序算法进行描述和实现,并在此基础上分析此算法的并行性,确定并行编程模式,最后给出该算法的MPI实现。
一、快速排序算法说明
快速排序时一种最基本的排序算法,效率相对较高。其基本思想是:在当前无序数组R[1,n]中选取一个记录作为比较的“基准”,即作为排序中的“轴”。经过一趟排序后,当前无序数组R[1,n]就会以这个轴为核心划分为两个无序的子区r1[1,i-1],r2[i,n]。其中左边的无序子区都会比“轴”小,右边的无序子区都会比“轴”大。这样下一趟排序,我们就可以对这两个子区用同样的方法进行划分排序,知道所有的无序子区中的记录均排好为止。
根据算法的说明,快速排序时一个典型的递归算法,算法描述如下:
无序数组R[1], R[2], ... , R[n]
quick_sort(R, start, end)
if(start < end)
r = partion(R, start, end)
quick_sort(R, start, r-1)
quick_sort(R, r+1, end)
endif
end quick_sort
方法partion的作用就是选取“轴”,并将数组分为两个无序子区,并将该“轴”的最终位置返回,在这里我们选择数组的第一个元素为“轴”,其算法描述为:
partion(R, start, end)
r = R[start]
while(start < end)
while( (R[end] >= r) && (start < end))
end--
end ehile
R[start] = R[end]
while( (R[start] < r) && (start < end))
start++
end wile
R[end] = R[start]
end while
R[start] = r
return start
end partion
该排序算法的性能好坏主要取决于“轴”的选定,即无序数组的划分是否均衡。最好的情况下,无序数组每次都会被划为两个均等的无序子区,这是算法的负责度为o(nlogn);最坏的情况,无序数组每次划分都是左边n-1个元素,右边0个元素,这时算法的复杂度为o(n^2)。在通常的情况下,该算法的复杂度会依然保持在o(nlogn),上只不过具有更高的常数因子。因此,选定一个有效地“轴”,成为该算法的关键。一般情况下,会选定无序数组的第一个,中间或者是最后一个元素作为算法的“轴”,我们可以对着三个元素进行比较,取大小居中的那个元素作为该算法的“轴”。
二、快速排序算法的串行实现
快速排序很明显的是一个递归的程序。编写递归程序一个很重的要点就是确定在什么条件下终止递归操作。主函数代码如下:
1: void quick_sort_function(int *array, int start, int last){
2: 3: int part_position;
4: 5: if(start >= last)
6: return;
7: 8: part_position = part_array_head(array, start, last); 9: quick_sort_function(array, start, part_position-1); 10: quick_sort_function(array, part_position+1, last); 11: }主函数代码很简单,一个终止递归的条件,一个递归方式。在主函数中,核心函数为part_array_head,其代码如下:
1: int part_array_head(int *array, int start, int last){
2: 3: int position_value = array[start];
4: 5: while(start < last){
6: while(start < last && array[last] >= position_value)
7: last--; 8: array[start] = array[last]; 9: 10: while(start < last && array[start] <= position_value)
11: start++; 12: array[last] = array[start]; 13: } 14: 15: array[start] = position_value; 16: 17: return start;
18: }从代码可以看出,快速排序的代码相对姜丹,总共不过三十行代码。本人是非常喜欢递归操作的。下面我们将对快速排序进行并行化分析。
三、快速排序并行化分析
在并行编程策略中,有一种策略非常适合递归算法,自然也就成为我们快速排序并行化的首选策略。这种策略为“分治策略”,这种策略的核心思想就是将一个大而复杂的问题分解成若干个子问题分而治之。若分解后的子问题依然过大或者是过于复杂,则可反复利用分治策略,直到很容易的求解子问题未知。
有此看出,分治策略也符合递归的思想。要实现分治策略,主要分为三步:1、将大问题分解成小问题;2、求解小问题;3、归并小问题的解,得到最终结果。其中各个小问题的求解就是我们并行化的所在。分治策略的说明图如下:
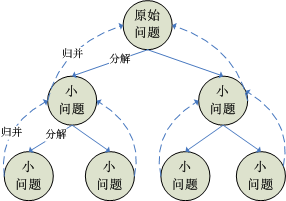
在快速排序算法中,我们就是将原无序数组按照一定得规则拆分成一个个子数组,即上图中的“分解”过程,每个子数组的排序可并行执行。当各子数组排序完毕后,依此将结构传给其父数组,得到最终的结果,即上图中的“归并”过程。
基于以上的分析,我们给出快速排序算法MPI的实现如下:
四、快速排序的MPI并行实现
因为分治策略的特殊性,我们进行快速排序算法的进程数目为2^m个。我们依然用进程p0来读取原数组,最终的排序结果也会由进程p0打印出来。
在该算法中,我们如果知道进程数目为2^m个,就应该能够求出m。因此我写了一个实现函数,求一个整数的以2为底的对数的算法。该算法的具体实现为:
1: int log_int(int root, int num){
2: 3: int i, j;
4: 5: i = 1; 6: j = root; 7: 8: while(j < num){
9: j *= root; 10: i++; 11: } 12: 13: if(j > num)
14: i--; 15: 16: return i;
17: }该并行算法的主函数为:
1: void quick_sort_mpi(int *argv, char ***argc){
2: 3: int process_id;
4: int process_size;
5: 6: int *init_array;
7: int array_length;
8: 9: int log_num;
10: int k;
11: 12: mpi_start(argv, argc, &process_size, &process_id, MPI_COMM_WORLD); 13: 14: if(process_size % 2 != 0){
15: if(!process_id)
16: printf("the size of the process must is the multipe of 2");
17: 18: MPI_Abort(MPI_COMM_WORLD, PROCESS_SIZE_ERROR); 19: } 20: 21: log_num = log_int(2, process_size); 22: array_length = ARRAY_LENGTH; 23: 24: if(!process_id){
25: init_array = (int *)my_mpi_malloc(0, sizeof(int) * array_length);
26: array_builder(init_array, array_length); 27: array_int_print(array_length, init_array); 28: } 29: 30: //对数组进行快速排序
31: quick_sort_mpi_function(init_array, array_length, log_num, process_id, 0, MPI_COMM_WORLD); 32: 33: if(!process_id)
34: array_int_print(array_length, init_array); 35: 36: MPI_Finalize(); 37: }在程序中出现的子函数在这里就不一一介绍了,其中主要的函数在上一篇枚举排序的MPI算法中都有所介绍。主函数的核心就是quic_sort_mpi_fuction函数,
该函数真正实现了快速排序,其代码如下:
1: void quick_sort_mpi_function(
2: int *init_array, //待排序数组
3: int array_length, //待排序数组长度
4: int log_num, //进程数取2为底的对数
5: int process_id, //当前活动进程ID
6: int part_process_id, //对数组进行拆分的进程ID
7: MPI_Comm comm){ 8: 9: int *local_array;
10: int local_array_length = 0;
11: 12: int send_array_length;
13: 14: int partion_position;
15: 16: //取得要接收数据的进程号的进程号
17: int receive_process_id;
18: int j;
19: 20: MPI_Status status; 21: 22: if(log_num == 0){
23: if(process_id == part_process_id && array_length > 1)
24: quick_sort_function(init_array, 0, array_length-1); 25: 26: return;
27: } 28: 29: receive_process_id = part_process_id + pow_int(2, log_num - 1); 30: 31: //当活动进程为数组拆分进程时,按照快速排序方法对数组分成两部分
32: if(process_id == part_process_id){
33: partion_position = part_array_head(init_array, 0, array_length-1); 34: send_array_length = array_length - partion_position -1; 35: local_array_length = partion_position; 36: 37: MPI_Send((void *)&send_array_length, 1, MPI_INT,
38: receive_process_id, LENGTH_MESSAGE, comm); 39: 40: if(send_array_length > 0)
41: MPI_Send((void *)(init_array + partion_position +1), send_array_length,
42: MPI_INT, receive_process_id, DATA_MESSAGE, comm); 43: } 44: 45: //当活动进程为待接收数据的进程时,接收从拆分进程发送过来的数据
46: if(process_id == receive_process_id){
47: 48: MPI_Recv((void *)&local_array_length, 1, MPI_INT, part_process_id,
49: LENGTH_MESSAGE, comm, &status); 50: 51: if(local_array_length >0)
52: {53: local_array = (int *)my_mpi_malloc(process_id, sizeof(int) * local_array_length);
54: MPI_Recv((void *)local_array, local_array_length, MPI_INT, part_process_id,
55: DATA_MESSAGE, comm, &status); 56: 57: } 58: } 59: 60: j = local_array_length; 61: MPI_Bcast(&j, 1, MPI_INT, part_process_id, comm);62: if(j > 1){
64: quick_sort_mpi_function(init_array, local_array_length, log_num -1, 65: process_id, part_process_id, comm); 66: } 67: 68: j = local_array_length; 69: MPI_Bcast(&j, 1, MPI_INT, receive_process_id, MPI_COMM_WORLD);70: if(j > 1)
71: quick_sort_mpi_function(local_array, local_array_length, log_num-1, 72: process_id, receive_process_id, comm); 73: 74: if(process_id == receive_process_id && local_array_length >0)
75: MPI_Send((void *)local_array, local_array_length, MPI_INT,
76: part_process_id, DATA_MESSAGE_SORT, MPI_COMM_WORLD); 77: 78: if(process_id == part_process_id && send_array_length > 0)
79: MPI_Recv((void *)(init_array + partion_position +1), send_array_length,
80: MPI_INT, receive_process_id, DATA_MESSAGE_SORT, MPI_COMM_WORLD, &status); 81: }该算法基本继承了并行编程策略的分治所发思想:分解 --- 求解 --- 归并。
五、MPI函数的说明
在该算法中,用到了MPI两个重要的通信函数MPI_Send和MPI_Recv,发送和接受函数。这两个函数实现了两个进程间的通信。同时,这两个函数是阻塞通信函数,即:
进程在没有接受到或发送完数据的情况下,将阻塞。
这样我们就完成了快速排序算法并行化得描述和实现,在这两篇中,分别介绍了并行编程策略的两个策略:单程序多数据流策略和分治策略。下篇将介绍并行正则采样
排序算法的设计和实现。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· [AI/GPT/综述] AI Agent的设计模式综述