Java并发工具合集JUC大爆发!!!
并发工具类
通常我们所说的并发包也就是java.util.concurrent(JUC),集中了Java并发的各种工具类, 合理地使用它们能帮忙我们快速地完成功能 。
- 作者: 博学谷狂野架构师
- GitHub:GitHub地址 (有我精心准备的130本电子书PDF)
只分享干货、不吹水,让我们一起加油!😄
1. CountDownLatch
CountDownLatch是一个同步计数器,初始化的时候 传入需要计数的线程等待数,可以是需要等待执行完成的线程数,或者大于 ,一般称为发令枪。\
countdownlatch 是一个同步类工具,不涉及锁定,当count的值为零时当前线程继续运行,不涉及同步,只涉及线程通信的时候,使用它较为合适
1.1 作用
用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用),是一组线程等待其他的线程完成工作以后在执行,相当于加强版join。
注意:这是一个一次性操作 - 计数无法重置。 如果你需要一个重置的版本计数,考虑使用CyclicBarrier。
1.2 举例
我们去组团游玩一样,总共30个人,来的人要等待还没有到的人,一直等到第30个人到了,我们才开始出发,在等待过程中,其他人(线程)是等待状态不做任何事情的,一直等所有人(线程)到齐了(准备完成)才开始执行。
1.3 概念
- countDownLatch这个类使一个线程等待其他线程各自执行完毕后再执行。
- 是通过一个计数器来实现的,计数器的初始值是线程的数量。每当一个线程执行完毕后,计数器的值就-1,当计数器的值为0时,表示所有线程都执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
我们打开CountDownLatch的源代码分析,我们发现最重要的方法就是一下这两个方法:
//阻塞当前线程,等待其他线程执行完成,直到计数器计数值减到0。 public void await() throws InterruptedException; //阻塞当前线程指定的时间,如果达到时间就放行,等待其他线程执行完成,直到计数器计数值减到0。 public boolean await(long timeout, TimeUnit unit) throws InterruptedException //负责计数器的减一。 public void countDown():
1.4 应用场景
1.4.1 多线程压测
有时我们想同时启动多个线程,实现最大程度的并行性。
例如,我们想测试一个单例类。如果我们创建一个初始计数为1的CountDownLatch,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用 一次countDown()方法就可以让所有的等待线程同时恢复执行。
1.4.2 等待其他线程
例如应用程序启动类要确保在处理用户请求前,所有N个外部系统已经启动和运行了,例如处理excel中多个表单,如果一个一个出来很耗IO和性能,我们可以等100或者1000个线程都完成了表单的操作后一下子写进excel表单中。
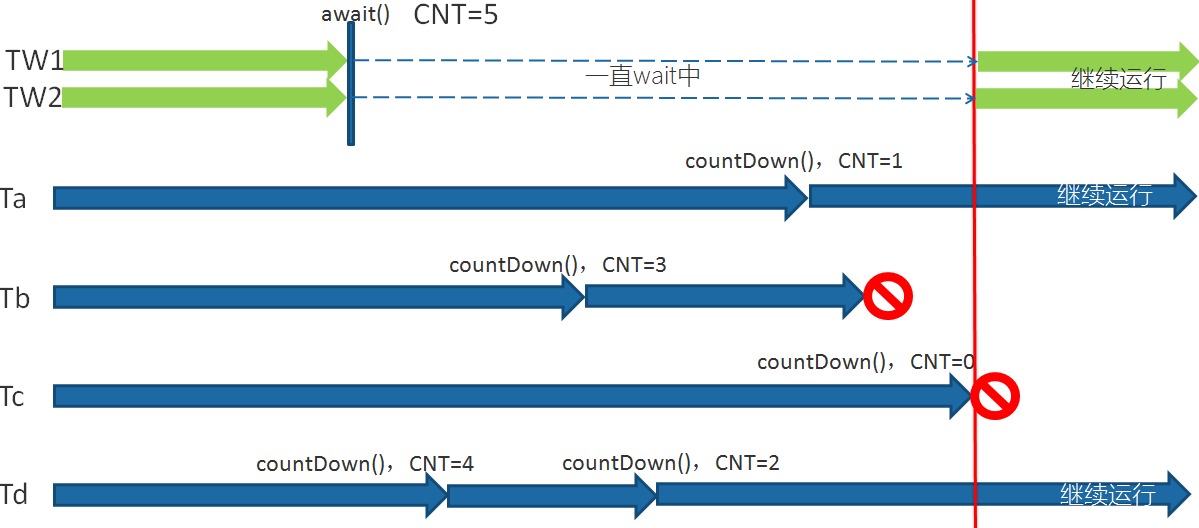
注意:一个线程不一定只能做countDown一次,也可以countDown多次
1.5 示例
1.5.1 准备完成后执行
在实际项目中可能有些线程需要资源准备完成后才能进行执行,这个时候就可以使用countDownLatch
package chapter02.countdownlatch; import java.util.Random; import java.util.concurrent.*; /** * countdownlatch 示例 */ public class CountDownLatchTest { private static ExecutorService executorService = Executors.newFixedThreadPool(10); private static Random random = new Random(); public static void execute(CountDownLatch countDownLatch) { //获取一个随机数 long sleepTime = random.nextInt(10); //获取线程ID long threadId = Thread.currentThread().getId(); System.out.println("线程ID" + threadId + ",开始执行--countDown"); try { //睡眠随机秒 Thread.sleep(sleepTime * 1000); } catch (InterruptedException e) { e.printStackTrace(); } //计数器减1 countDownLatch.countDown(); System.out.println("线程ID" + threadId + ",准备任务完成耗时:" + sleepTime + "当前时间" + System.currentTimeMillis()); try { //线程等待其他任务完成后唤醒 countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("线程ID" + threadId + ",开始执行任务,当前时间:" + System.currentTimeMillis()); } public static void main(String[] args) throws InterruptedException { CountDownLatch countDownLatch = new CountDownLatch(5); for (int i = 0; i < 5; i++) { executorService.submit(() -> { execute(countDownLatch); }); } //线程等待其他任务完成后唤醒 countDownLatch.await(); Thread.sleep(1000); executorService.shutdown(); System.out.println("全部任务执行完成"); } }
1.5.2 多线程压测
在实战项目中,我们除了使用 jemter 等工具进行压测外,还可以自己动手使用 CountDownLatch 类编写压测代码。
可以说 jemter 的并发压测背后也是使用的 CountDownLatch,可见掌握 CountDownLatch 类的使用是有多么的重要, CountDownLatch是Java多线程同步器的四大金刚之一,CountDownLatch能够使一个线程等待其他线程完成各自的工作后再执行。
package chapter02.countdownlatch; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; /** * countDownLatch 压测 */ public class CountDownLatchPressure { /** * 压测业务代码 */ public void testLoad() { System.out.println("压测:" + Thread.currentThread().getId() + ":" + System.currentTimeMillis()); } /** * 压测启动 * 主线程负责压测线程准备工作 * 压测线程准备完成后 调用 start.countDown(); 启动线程执行 * @throws InterruptedException */ private void latchTest() throws InterruptedException { //压测线程数 int testThreads = 300; final CountDownLatch start = new CountDownLatch(1); final CountDownLatch end = new CountDownLatch(testThreads); //创建线程池 ExecutorService exce = Executors.newFixedThreadPool(testThreads); //准备线程准备 for (int i = 0; i < testThreads; i++) { //添加到线程池 exce.submit(() -> { try { //启动后等待 唤醒 start.await(); testLoad(); } catch (InterruptedException e) { e.printStackTrace(); } finally { //压测完成 end.countDown(); } }); } //连接池线程初始化完成 开始压测 start.countDown(); //压测完成后结束 end.await(); //关闭线程池 exce.shutdown(); } public static void main(String[] args) throws InterruptedException { CountDownLatchPressure countDownLatchPressure = new CountDownLatchPressure(); //开始压测 countDownLatchPressure.latchTest(); } }
2. CyclicBarrier
2.1 简介
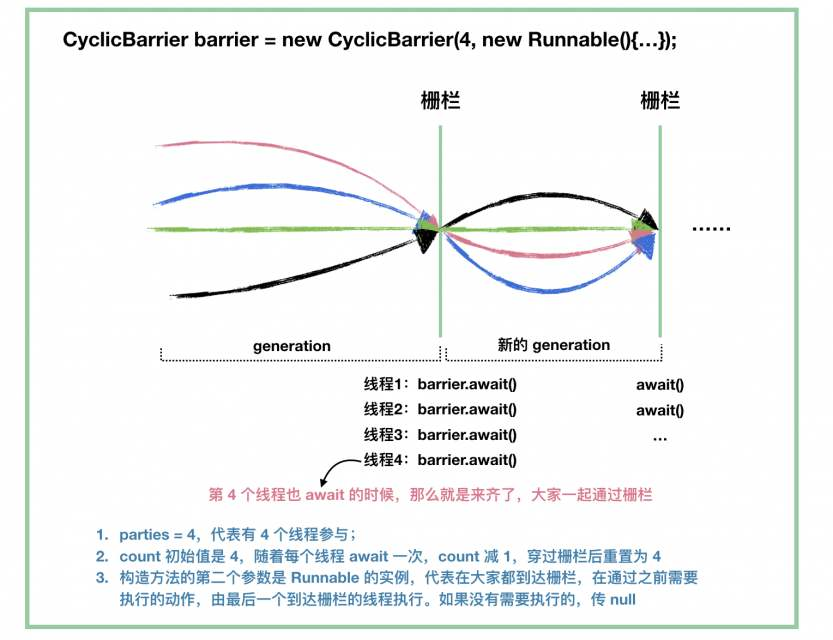
CyclicBarrier,是JDK1.5的java.util.concurrent(JUC)并发包中提供的一个并发工具类
C yclicBarrier可以使一定数量的线程反复地在栅栏位置处汇集,当线程到达栅栏位置时将调用await方法,这个方法将阻塞直到所有线程都到达栅栏位置,如果所有线程都到达栅栏位置,那么栅栏将打开,此时所有的线程都将被释放,而栅栏将被重置以便下次使用。
2.2 举例
就像生活中我们会约朋友们到某个餐厅一起吃饭,有些朋友可能会早到,有些朋友可能会晚到,但是这个餐厅规定必须等到所有人到齐之后才会让我们进去。
这里的朋友们就是各个线程,餐厅就是CyclicBarrier,感觉和 CountDownLatch是一样的,但是他们是有区别的,吃完饭之后可以选择去玩一会,去处理任务,然后等待第二次聚餐,重复循环。
2.3 功能
CyclicBarrier和CountDownLatch是非常类似的,CyclicBarrier核心的概念是在于设置一个等待线程的数量边界,到达了此边界之后进行执行。
CyclicBarrier类是一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点(Common Barrier Point)。
CyclicBarrier类是一种同步机制,它能够对处理一些算法的线程实现同。换句话讲,它就是一个所有线程必须等待的一个栅栏,直到所有线程都到达这里,然后所有线程才可以继续做其他事情。
通过调用CyclicBarrier对象的await()方法,两个线程可以实现互相等待,一旦N个线程在等待CyclicBarrier达成,所有线程将被释放掉去继续执行。
2.4 构造方法
我们可以看下 CyclicBarrier源码的构造方法
public CyclicBarrier(int parties) public CyclicBarrier(int parties, Runnable barrierAction)
2.4.1 参数介绍
-
parties : 是参与线程的个数 , 其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
-
barrierAction : 优先执行线程 ,用于在线程到达屏障时,优先执行barrierAction,方便处理更复杂的业务场景,一般用于数据的整理以及汇总,例如excel插入一样,等所有线程都插入完了,到达了屏障后,barrierAction线程开始进行保存操作,完成后,接下来由其他线程开始进行插入,然后到达屏障接着就是保存,不断循环。
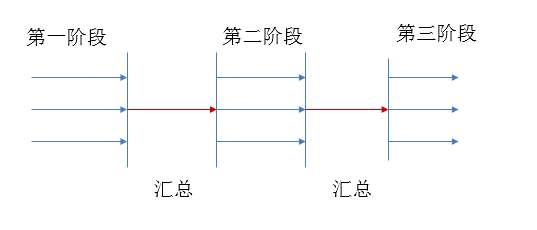
CyclicBarrier可以用于多线程计算数据,最后合并计算结果的场景。
2.5 重要方法
我们上面介绍了构造方法,下面我们介绍下CyclicBarrier中重要的方法
//阻塞当前线程,等待其他线程执行完成。 public int await() throws InterruptedException, BrokenBarrierException //阻塞当前线程指定的时间,如果达到时间就放行,等待其他线程执行完成, public int await(long timeout, TimeUnit unit) throws InterruptedException, BrokenBarrierException, TimeoutException
- 线程调用 await() 表示自己已经到达栅栏
- BrokenBarrierException 表示栅栏已经被破坏,破坏的原因可能是其中一个线程 await() 时被中断或者超时
2.6 基本使用
一个线程组的线程需要等待所有线程完成任务后再继续执行下一次任务
package chapter02.cyclicbarrier; import java.util.Random; import java.util.concurrent.BrokenBarrierException; import java.util.concurrent.CyclicBarrier; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class CyclicBarrierTest { private static Random random = new Random(); /** * 执行任务 * * @param barrier */ public static void execute(CyclicBarrier barrier) { //获取一个随机数 long sleepTime = random.nextInt(10); //获取线程id long threadId = Thread.currentThread().getId(); try { //睡眠随机秒 Thread.sleep(sleepTime * 1000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("线程ID" + threadId + ",准备任务完成耗时:" + sleepTime + "当前时间" + System.currentTimeMillis()); //线程等待其他任务完成后唤醒 try { barrier.await(); } catch (InterruptedException e) { e.printStackTrace(); } catch (BrokenBarrierException e) { e.printStackTrace(); } System.out.println("线程ID" + threadId + ",开始执行任务,当前时间:" + System.currentTimeMillis()); } public static void main(String[] args) { //初始化线程数量 int threadNum = 5; //初始化一般的线程 CyclicBarrier barrier = new CyclicBarrier(5, () -> System.out.println("整理任务开始...")); ExecutorService executor = Executors.newFixedThreadPool(threadNum); for (int i = 0; i < threadNum; i++) { executor.submit(() -> { execute(barrier); }); } } }
2.7 CyclicBarrier 与 CountDownLatch 区别
- CountDownLatch 是一次性的,CyclicBarrier 是可循环利用的
- CountDownLatch.await一般阻塞工作线程,所有的进行预备工作的线程执行countDown,而CyclicBarrier通过工作线程调用await从而自行阻塞,直到所有工作线程达到指定屏障,再大家一起往下走。
- CountDownLatch 参与的线程的职责是不一样的,有的在倒计时,有的在等待倒计时结束。CyclicBarrier 参与的线程职责是一样的。
- 在控制多个线程同时运行上,CountDownLatch可以不限线程数量,而CyclicBarrier是固定线程数。
- CyclicBarrier还可以提供一个barrierAction,合并多线程计算结果。
3. Semaphore

3.1 简介
Semaphore也叫信号量,在JDK1.5被引入,可以用来控制同时访问特定资源的线程数量,通过协调各个线程,以保证合理的使用资源。
Semaphore内部维护了一组虚拟的许可,许可的数量可以通过构造函数的参数指定。
- 访问特定资源前,必须使用acquire方法获得许可,如果许可数量为0,该线程则一直阻塞,直到有可用许可。
- 访问资源后,使用release释放许可。
Semaphore是一种在多线程环境下使用的设施,该设施负责协调各个线程,以保证它们能够正确、合理的使用公共资源的设施,也是操作系统中用于控制进程同步互斥的量。Semaphore是一种计数信号量,用于管理一组资源,内部是基于AQS的共享模式。它相当于给线程规定一个量从而控制允许活动的线程数。
可以用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源
3.2 举例
这里面令牌就像停车位一样,来了十辆车,停车位只有三个,只有三辆车能够进行,只有等其他车开走后,其他车才能开进去,和锁的不一样的地方是,锁一次只能进入一辆车,但是Semaphore允许一次进入很多车,这个令牌是可以调整的,随时可以增减令牌。
3.3 应用场景
Semaphore 是 synchronized 的加强版,作用是控制线程的并发数量。就这一点而言,单纯的synchronized 关键字是实现不了的。
Semaphore可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制
3.4 工作原理
以一个停车场是运作为例,为了简单起见,假设停车场只有三个车位,一开始三个车位都是空的。
这时如果同时来了五辆车,看门人允许其中三辆不受阻碍的进入,然后放下车拦,剩下的车则必须在入口等待,此后来的车也都不得不在入口处等待。
这时,有一辆车离开停车场,看门人得知后,打开车拦,放入一辆,如果又离开两辆,则又可以放入两辆,如此往复。
这个停车系统中,每辆车就好比一个线程,看门人就好比一个信号量,看门人限制了可以活动的线程,假如里面依然是三个车位,但是看门人改变了规则,要求每次只能停两辆车,那么一开始进入两辆车,后面得等到有车离开才能有车进入,但是得保证最多停两辆车。
对于Semaphore类而言,就如同一个看门人,限制了可活动的线程数。
3.5 构造方法
创建具有给定许可数的计数信号量并设置为非公平信号量
查看Semaphore源码发现他有这两个构造方法
public Semaphore(int permits) public Semaphore(int permits, boolean fair)
3.5.1 参数介绍
-
permits 是设置同时允许通过的线程数
-
fair 等于true时,创建具有给定许可数的计数信号量并设置为公平信号量。
3.6 其他方法
Semaphore类里面还有一些重要的方法
//从此信号量获取一个许可前线程将一直阻塞。相当于一辆车占了一个车位 public void acquire() throws InterruptedException //从此信号量获取给定数目许可,在提供这些许可前一直将线程阻塞。比如n=2,就相当于一辆车占了两个车位。 public void acquire(int permits) throws InterruptedException //释放一个许可,将其返回给信号量。就如同车开走返回一个车位。 public void release() //获取当前可用许可数 public void release(int permits) //获取当前可用许可数 public int availablePermits()
3.7 示例代码
共有5个车位但是有100个线程进行占用,车停几秒后会离开,释放车位给其他线程。
package chapter02.semaphore; import java.util.Random; import java.util.concurrent.*; public class SemaphoreTest { private static ExecutorService executorService = Executors.newCachedThreadPool(); private static Random random = new Random(); //阻塞队列 private static BlockingQueue<String> parks = new LinkedBlockingQueue<>(5); public static void execute(Semaphore semaphore) { //获取一个随机数 long sleepTime = random.nextInt(10); long threadId = Thread.currentThread().getId(); String park = null; try { /** * 获取许可,首先判断semaphore内部的数字是否大于0,如果大于0, * 才能获得许可,然后将初始值5减去1,线程才会接着去执行;如果没有 * 获得许可(原因是因为已经有5个线程获得到许可,semaphore内部的数字为0), * 线程会阻塞直到已经获得到许可的线程,调用release()方法,释放掉许可, * 也就是将semaphore内部的数字加1,该线程才有可能获得许可。 */ semaphore.acquire(); /** * 对应的线程会到阻塞对,对应车辆去获取到车位,如果没有拿到一致阻塞, * 直到其他车辆归还车位。 */ park = parks.take(); System.out.println("线程ID" + threadId + ",开始占用车位:" + park + ",当前剩余车位" + semaphore.availablePermits()); } catch (InterruptedException e) { e.printStackTrace(); } try { //睡眠随机秒 Thread.sleep(sleepTime * 1000); } catch (InterruptedException e) { e.printStackTrace(); } //归还车位 parks.offer(park); System.out.println("线程ID" + threadId + ",开始归还车位:" + park + ",共占用" + sleepTime + "秒"); //线程释放掉许可,通俗来将就是将semaphore内部的数字加1 semaphore.release(); } public static void main(String[] args) { //初始化线程数量 int threadNum = 100; parks.offer("车位一"); parks.offer("车位二"); parks.offer("车位三"); parks.offer("车位四"); parks.offer("车位五"); // 初始化5个许可证 Semaphore semaphore = new Semaphore(5); //可以提前释放但是车位就会被多个线程同时占用 //semaphore.release(5); for (int i = 0; i < threadNum; i++) { executorService.submit(() -> { execute(semaphore); }); } } }
3.8 注意事项
即使创建信号量的时候,指定了信号量的大小 ,但是在通过 release()操作释放信号量仍然能释放超过配置的大小,也就有可能同时执行的线程数量比最开始设置的要大,没有任何线程获取信号量的时候,依然能够释放并且释放的有效。
推荐的做法是一个线程先 acquire 然后 release,如果释放线程和获取线程不是同一个,那么最好保证这种对应关系。不要释放过多的许可证。
4. Fork/Join
4.1 简介
java下多线程的开发可以我们自己启用多线程,线程池,还可以使用forkjoin,forkjoin可以让我们不去了解诸如Thread,Runnable等相关的知识,只要遵循forkjoin的开发模式,就可以写出很好的多线程并发程序
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join框架是一个实现了ExecutorService接口的多线程处理器。它可以把一个大的任务划分为若干个小的任务并发执行,充分利用可用的资源,进而提高应用的执行效率。
Fork/Join框架简化了并行程序的原因有 :
- 它简化了线程的创建,在框架中线程是自动被创建和管理。
- 它自动使用多个处理器,因此程序可以扩展到使用可用处理器。
4.2 举例
就像我需要处理一百万行的excel,普通的处理是一个一个的excel进行处理,但是使用Fork/Join框架后的处理方式呢,加入我们定义100条数据为一个批次,那么Fork/Join就会拆分这个excel先到中间拆分成各有50万的数据,然后还比100大就继续拆分,不断的细分,最后分到了每一个线程分得到了100条然后才开始执行。
4.3 分而治之
“分而治之” 一直是一个有效的处理大量数据的方法。著名的 MapReduce 也是采取了分而治之的思想。
简单来说,就是如果你要处理1000个数据,但是你并不具备处理1000个数据的能力,那么你可以只处理其中的10个,然后,分阶段处理100次,将100次的结果进行合成,那就是最终想要的对原始的1000个数据的处理结果。
同时forkjoin在处理某一类问题时非常的有用,哪一类问题?分而治之的问题。十大计算机经典算法:快速排序、堆排序、归并排序、二分查找、线性查找、深度优先、广度优先、Dijkstra、动态规划、朴素贝叶斯分类,有几个属于分而治之?3个,快速排序、归并排序、二分查找,还有大数据中M/R都是。
4.3.1 分治法的设计思想
将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
4.3.2 分治策略
对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同(子问题相互之间有联系就会变为动态规范算法),递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
4.4 Fork-Join原理
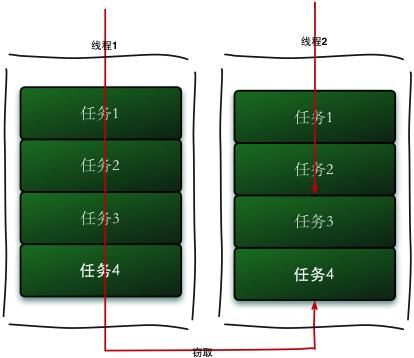
Fork/Join实现了ExecutorService,所以它的任务也需要放在线程池中执行。它的不同在于它使用了工作窃取算法,空闲的线程可以从满负荷的线程中窃取任务来帮忙执行。
由于线程池中的每个线程都有一个队列,而且线程间互不影响,那么线程每次都从自己的任务队列的头部获取一个任务出来执行。如果某个时候一个线程的任务队列空了,而其余的线程任务队列中还有任务,那么这个线程就会从其他线程的任务队列中取一个任务出来帮忙执行。就像偷取了其他人的工作一样
4.4.1 任务分割和合并
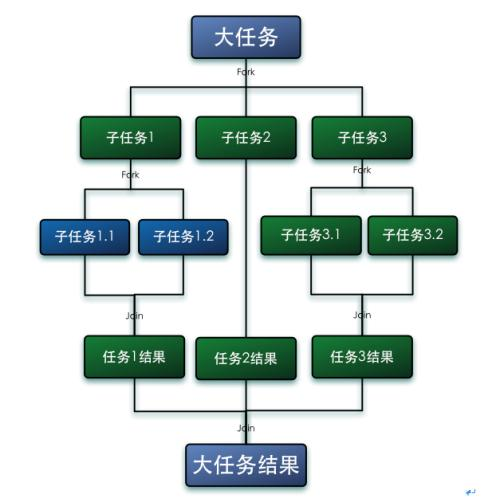
Fork/Join框架的基本思想就是将一个大任务分解(Fork)成一系列子任务,子任务可以继续往下分解,当多个不同的子任务都执行完成后,可以将它们各自的结果合并(Join)成一个大结果,最终合并成大任务的结果

我们看下面这个图

首先main Task 先fork成 0,1两个任务 接着,因为还是太大,继续fork成 0-0,0-1,1-0,1-1 然后进行计算计算完成后进行join操作,0-0,1-1 join到0, 1-0,1-1 join到1 然后 0和1继续join到mainTask,完成计算任务。
4.4.2 工作密取
即当前线程的Task已经全被执行完毕,则自动取到其他线程的Task池中取出Task继续执行即如果一个工作线程没有事情要做,它可以从其他仍然忙碌的线程窃取任务。
ForkJoinPool中维护着多个线程(一般为CPU核数)在不断地执行Task,每个线程除了执行自己职务内的Task之外,还会根据自己工作线程的闲置情况去获取其他繁忙的工作线程的Task,如此一来就能能够减少线程阻塞或是闲置的时间,提高CPU利用率。
4.5 相关子类
我们已经很清楚 Fork/Join 框架的需求了,那么我们可以思考一下,如果让我们来设计一个 Fork/Join 框架,该如何设计?这个思考有助于你理解 Fork/Join 框架的设计。
第一步分割任务。首先我们需要有一个 fork 类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
第二步执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join 使用两个类来完成以上两件事情:
4.5.1 ForkJoinTask
我们要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务中执行 fork() 和 join() 操作的机制,通常情况下我们不需要直接继承 ForkJoinTask 类,而只需要继承它的子类,Fork/Join 框架提供了以下两个子类:
4.5.1.1 RecursiveAction
用于没有返回结果的任务
4.5.1.2 RecursiveTask
用于有返回结果的任务。
4.5.2 ForkJoinPool
ForkJoinTask 需要通过 ForkJoinPool 来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务
4.6 Fork/Join使用
Task要通过ForkJoinPool来执行,使用submit 或 invoke 提交,两者的区别是:invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码;submit是异步执行,join()和get方法当任务完成的时候返回计算结果
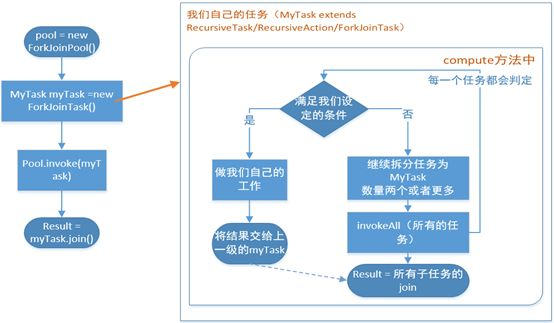
在我们自己实现的compute方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用invokeAll方法时,又会进入compute方法,看看当前子任务是否需要继续分割成孙任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
4.6.1 任务的提交逻辑
fork/join其实大部分逻辑处理操作都集中在提交任务和处理任务这两块,了解任务的提交基本上后面就很容易理解了, fork/join提交任务主要分为两种:
4.6.1.1 第一次提交到forkJoinPool
//创建初始化任务 SubmitTask submitTask = new SubmitTask(start, end); //将初始任务扔进连接池中执行 forkJoinPool.invoke(submitTask);
4.6.1.2 任务切分之后的提交
//没有达到阈值 计算一个中间值 long mid = (start + end) / 2; //拆分 左边的 SubmitTask left = new SubmitTask(start, mid); //拆分右边的 SubmitTask right = new SubmitTask(mid + 1, end); //添加到任务列表 invokeAll(left, right);
4.6.1.3 合并任务
//合并结果并返回 return left.join() + right.join();
4.6.1.4 代码案例
package chapter02.forkjoin; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveTask; /** * 计算 0-10000 阶乘 */ public class SubmitTask extends RecursiveTask<Long> { /** * 起始值 */ private long start; /** * 结束值 */ private long end; /** * 阈值 */ private long threshold = 10L; public SubmitTask(long start, long end) { this.start = start; this.end = end; } /** * 计算逻辑 * 进行任务的拆分 以及 达到阈值的计算 * * @return */ @Override protected Long compute() { //校验是否达到了阈值 if (isLessThanThreshold()) { //处理并返回结果 return handle(); } else { //没有达到阈值 计算一个中间值 long mid = (start + end) / 2; //拆分 左边的 SubmitTask left = new SubmitTask(start, mid); //拆分右边的 SubmitTask right = new SubmitTask(mid + 1, end); //添加到任务列表 invokeAll(left, right); //合并结果并返回 return left.join() + right.join(); } } /** * 处理的任务 * * @return */ public Long handle() { long sum = 0; for (long i = start; i <= end; i++) { sum += i; try { Thread.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } return sum; } /*是否达到了阈值*/ private boolean isLessThanThreshold() { return end - start <= threshold; } /** * forkJoin 方式调用 * * @param start * @param end */ public static void forkJoinInvok(long start, long end) { long sum = 0; long currentTime = System.currentTimeMillis(); //创建ForkJoinPool 连接池 ForkJoinPool forkJoinPool = new ForkJoinPool(); //创建初始化任务 SubmitTask submitTask = new SubmitTask(start, end); //将初始任务扔进连接池中执行 forkJoinPool.invoke(submitTask); //forkJoinPool.submit(submitTask); // System.out.println("异步方式,任务结束才会调用该方法,当前耗时"+(System.currentTimeMillis() - currentTime)); //等待返回结果 sum = submitTask.join(); //forkjoin调用方式耗时 System.out.println("forkJoin调用:result:" + sum); System.out.println("forkJoin调用耗时:" + (System.currentTimeMillis() - currentTime)); } /** * 普通方式调用 * * @param start * @param end */ public static void normalInvok(long start, long end) { long sum = 0; long currentTime = System.currentTimeMillis(); for (long i = start; i <= end; i++) { sum += i; try { Thread.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } //普通调动方式耗时 System.out.println("普通调用:result:" + sum); System.out.println("普通调用耗时:" + (System.currentTimeMillis() - currentTime)); } public static void main(String[] args) { //起始值的大小 long start = 0; //结束值的大小 long end = 10000; //forkJoin 调用 forkJoinInvok(start, end); System.out.println("========================"); //普通调用 normalInvok(start, end); } }
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!