Apache Druid数据查询套件详解计数、排名和分位数计算(送JSON-over-HTTP和SQL两种查询详解)
5. 数据查询
欲看此文,必看如下两篇文章:
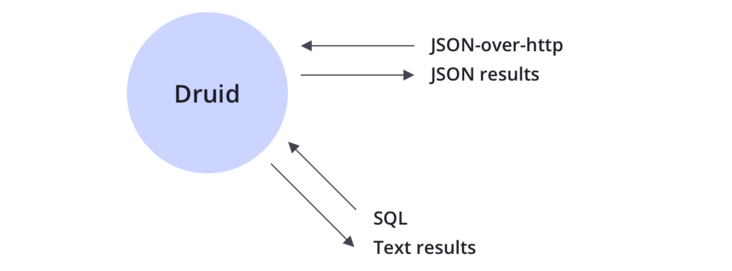
Druid支持JSON-over-HTTP和SQL两种查询方式。除了标准的SQL操作外,Druid还支持大量的唯一性操作,利用Druid提供的算法套件可以快速的进行计数,排名和分位数计算。
5.1 准备工作
5.1.1 导入大量数据
准备大量数据提供查询,我们插入1万条随机打车数据
http://localhost:8010/taxi/batchTask/100000
5.2.2 查看数据摄取进程
我们发现数据摄取进程正在运行,可以等待数据摄取任务结束
5.3 原生查询
Druid 最开始的时候是不支持 SQL 查询的,原生查询是通过查询 Broker 提供的 http server 来实现的
5.3.1 查询语法
curl -L -H'Content-Type:application/json' -XPOST --data-binary @<query_json_file> <queryable_host>:<port>/druid/v2/?pretty
5.3.2 查询案例
5.3.2.1 编辑查询JSON
# 创建查询目录 mkdir query # 编辑查询的JSON vi query/filter1.json
json 内容如下
{ "queryType":"timeseries", "dataSource":"message", "granularity":"month", "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{"type":"selector","dimension":"status","value":1}, "intervals":["2021-06-07/2022-06-07"] }
5.3.2.2 参数解释
- queryType:查询类型,timeseries代表时间序列查询
- dataSource:数据源,指定需要查询的数据源是什么
- granularity:分组粒度,指定需要进行分组的粒度是什么样的
- aggregations:聚合查询:里面我们聚合了count,对数据进行统计
- filter:数据过滤,需要查询那些数据
- intervals:查询时间的范围,注意时间范围是前闭后开的,后面的日期是查询不到的
5.3.2.3 执行查询命令
在命名行中执行下面的命令会将查询json发送到对应的broker中进行查询
--data-binary指定的查询json的路径
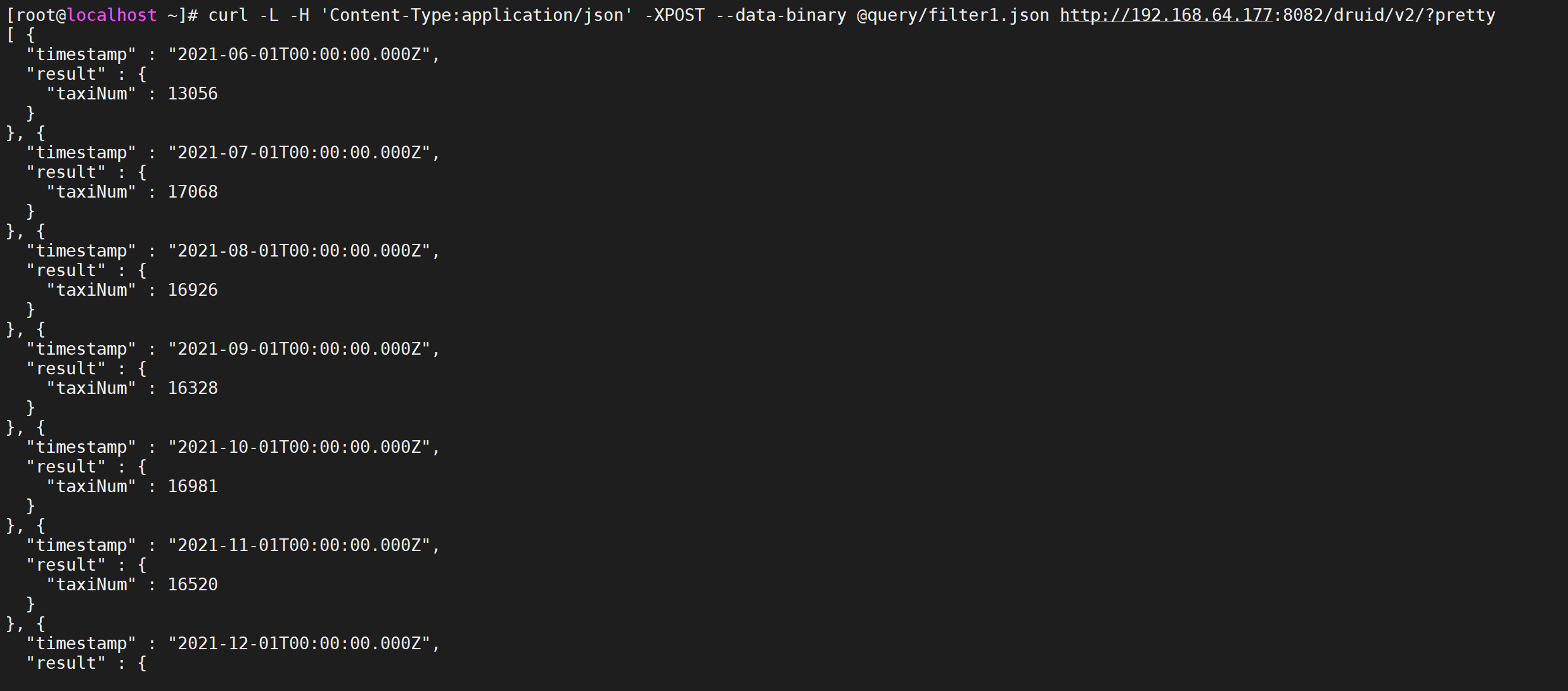
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter1.json http://192.168.64.177:8082/druid/v2/?pretty
我们查询了每个月发起打车的人数有多少
5.4 查询类型
druid查询采用的是HTTP RESTFUL方式,REST接口负责接收客户端的查询请求,客户端只需要将查询条件封装成JSON格式,通过HTTP方式将JSON查询条件发送到broker节点,查询成功会返回JSON格式的结果数据。了解一下druid提供的查询类型
5.4.1 时间序列查询
timeseries时间序列查询对于指定时间段按照查询规则返回聚合后的结果集,查询规则中可以设置查询粒度,结果排序方式以及过滤条件,过滤条件可以使用嵌套过滤,并且支持后聚合。
5.4.1.1 查询属性
时间序列查询主要包括7个主要部分
| 属性 | 描述 | 是否必须 |
|---|---|---|
queryType |
该字符串总是"timeseries"; 该字段告诉Apache Druid如何去解释这个查询 | 是 |
dataSource |
用来标识查询的的字符串或者对象,与关系型数据库中的表类似。查看数据源可以获得更多信息 | 是 |
descending |
是否对结果集进行降序排序,默认是false, 也就是升序排列 |
否 |
intervals |
ISO-8601格式的JSON对象,定义了要查询的时间范围 | 是 |
granularity |
定义了查询结果的粒度,参见 Granularity | 是 |
filter |
参见 Filters | 否 |
aggregations |
参见 聚合 | 否 |
postAggregations |
参见Post Aggregations | 否 |
limit |
限制返回结果数量的整数值,默认是unlimited | 否 |
context |
可以被用来修改查询行为,包括 Grand Total 和 Zero-filling。详情可以看 上下文参数部分中的所有参数类型 | 否 |
5.4.1.2 案例
{ "queryType":"topN", "dataSource":"taxi_message", "dimension":"local", "threshold":2, "metric":"age", "granularity":"month", "aggregations":[ { "type":"longMin", "name":"age", "fieldName":"age" } ], "filter":{"type":"selector","dimension":"sex","value":"女"}, "intervals":["2021-06-07/2022-06-07"] }
5.4.2 TopN查询
topn查询是通过给定的规则和显示维度返回一个结果集,topn查询可以看做是给定排序规则,返回单一维度的group by查询,但是topn查询比group by性能更快。metric这个属性是topn专属的按照该指标排序。
5.4.2.1 查询属性
topn的查询属性如下
| 属性 | 描述 | 是否必须 |
|---|---|---|
| queryType | 该字符串总是"TopN",Druid根据该值来确定如何解析查询 | 是 |
| dataSource | 定义将要查询的字符串或者对象,与关系型数据库中的表类似。 详情可以查看 数据源 部分。 | 是 |
| intervals | ISO-8601格式的时间间隔,定义了查询的时间范围 | 是 |
| granularity | 定义查询粒度, 参见 Granularities | 是 |
| filter | 参见 Filters | 否 |
| aggregations | 参见Aggregations | 对于数值类型的metricSpec, aggregations或者postAggregations必须指定,否则非必须 |
| postAggregations | 参见postAggregations | 对于数值类型的metricSpec, aggregations或者postAggregations必须指定,否则非必须 |
| dimension | 一个string或者json对象,用来定义topN查询的维度列,详情参见DimensionSpec | 是 |
| threshold | 在topN中定义N的一个整型数字,例如:在top列表中返回多少个结果 | 是 |
| metric | 一个string或者json对象,用来指定top列表的排序。更多信息可以参见TopNMetricSpec | 是 |
| context | 参见Context | 否 |
5.4.2.2 案例
查询每个季度年龄最小的女性的前两个的城市
vi query/topN.json
{ "queryType":"topN", "dataSource":"message", "dimension":"local", "threshold":2, "metric":"age", "granularity":"quarter", "aggregations":[ { "type":"longMin", "name":"age", "fieldName":"age" } ], "filter":{"type":"selector","dimension":"sex","value":"女"}, "intervals":["2021-06-07/2022-06-07"] }
5.4.2.3 执行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/topN.json http://192.168.64.177:8082/druid/v2/?pretty
5.4.5 分组查询
在实际应用中经常需要进行分组查询,等同于sql语句中的Group by查询,如果对单个维度和指标进行分组聚合计算,推荐使用topN查询,能够获得更高的查询性能,分组查询适合多维度,多指标聚合查询
5.4.5.1 查询属性
下表内容为一个GroupBy查询的主要部分:
| 属性 | 描述 | 是否必须 |
|---|---|---|
| queryType | 该字符串应该总是"groupBy", Druid根据该值来确定如何解析查询 | 是 |
| dataSource | 定义将要查询的字符串或者对象,与关系型数据库中的表类似。 详情可以查看 数据源 部分。 | 是 |
| dimension | 一个用来GroupBy的json List,详情参见DimensionSpec来了解提取维度的方式 | 是 |
| limitSpec | 参见limitSpec | 否 |
| having | 参见Having | 否 |
| granularity | 定义查询粒度,参见 Granularities | 是 |
| filter | 参见Filters | 否 |
| aggregations | 参见Aggregations | 否 |
| postAggregations | 参见Post Aggregations | 否 |
| intervals | ISO-8601格式的时间间隔,定义了查询的时间范围 | 是 |
| subtotalsSpec | 一个JSON数组,返回顶级维度子集分组的附加结果集。稍后将更详细地描述它。 | 否 |
| context | 参见Context | 否 |
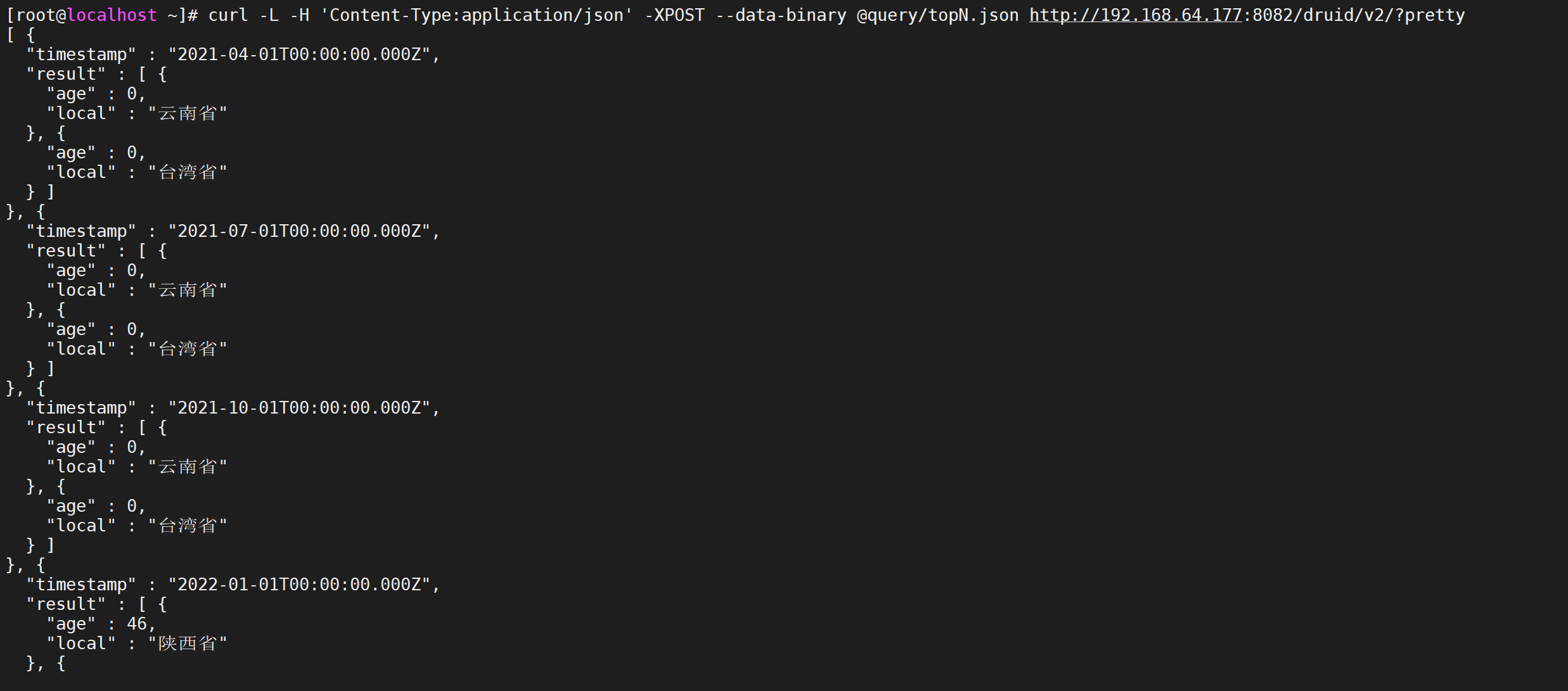
5.4.5.2 案例
每一季度统计年龄在21-31的男女打车的数量
vi query/groupBy.json
{ "queryType":"groupBy", "dataSource":"taxi_message", "granularity":"Quarter", "dimensions":["sex"], "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2022-06-07"] }
5.4.5.3 执行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/groupBy.json http://192.168.64.177:8082/druid/v2/?pretty
5.5 查询组件
在介绍具体的查询之前,我们先来了解一下各种查询都会用到的基本组件,如Filter,Aggregator,Post-Aggregator,Query,Interval等,每种组件都包含很多的细节
5.5.1 Filter
Filter就是过滤器,在查询语句中就是一个JSON对象,用来对维度进行筛选和过滤,表示维度满足Filter的行是我们需要的数据,类似sql中的where字句。Filter包含的类型如下:
5.5.1.1 选择过滤器
Selector Filter的功能类似于SQL中的
where key=value,它的json示例如下
"Filter":{"type":"selector","dimension":dimension_name,"value":target_value}
使用案例
vi query/filter1.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"month", "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{"type":"selector","dimension":"status","value":1}, "intervals":["2021-06-07/2022-06-07"] }
5.5.1.2 正则过滤器
Regex Filter 允许用户使用正则表达式进行维度的过滤筛选,任何java支持的标准正则表达式druid都支持,它的JSON格式如下:
"filter":{"type":"regex","dimension":dimension_name,"pattern":regex}
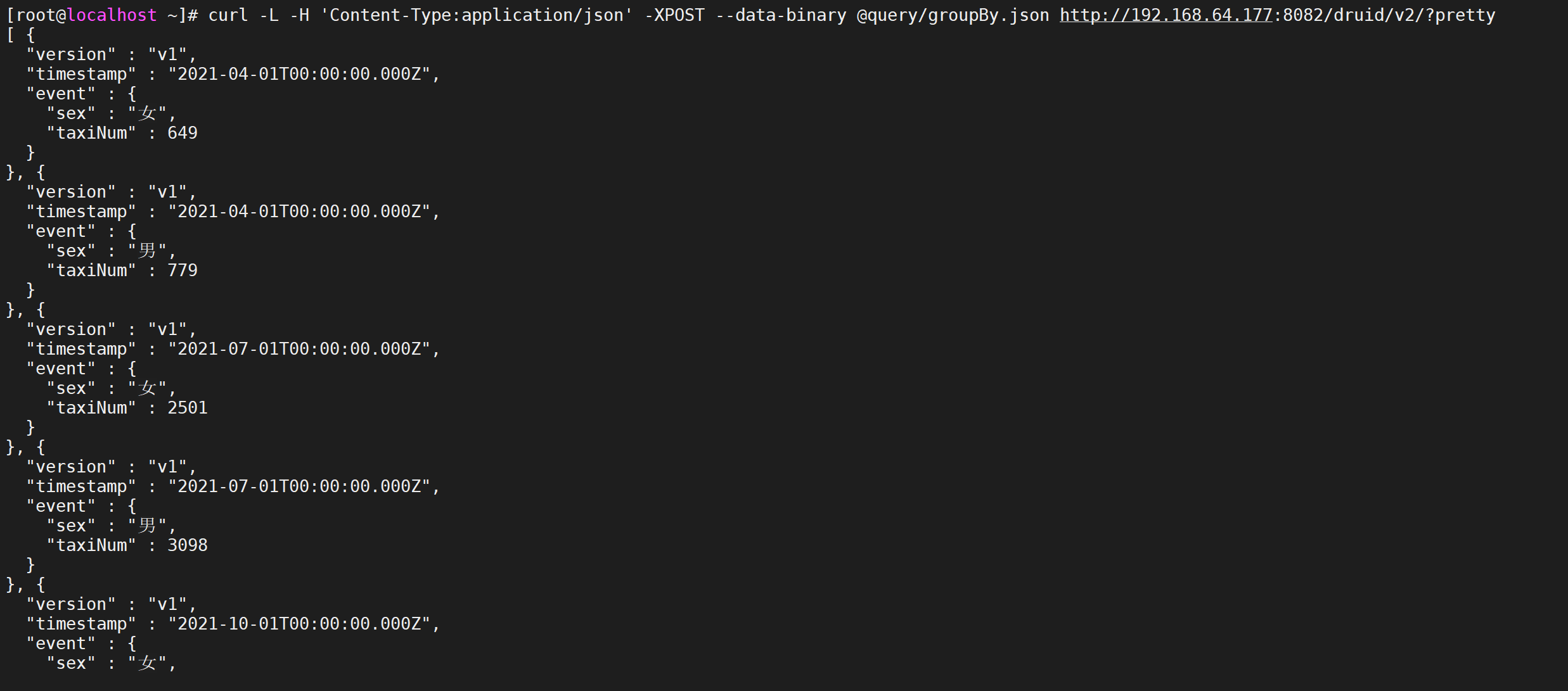
使用案例,我们搜索姓名包含数字的的用户进行聚合统计
vi query/filter2.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"month", "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{"type":"regex","dimension":"username","pattern":"[0-9]{1,}"}, "intervals":["2021-06-07/2022-06-07"] }
执行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter2.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.1.3 逻辑过滤器
Logincal Expression Filter包含and,not,or三种过滤器,每一种都支持嵌套,可以构建丰富的逻辑表达式,与sql中的and,not,or类似,JSON表达式如下:
"filter":{"type":"and","fields":[filter1,filter2]} "filter":{"type":"or","fields":[filter1,filter2]} "filter":{"type":"not","fields":[filter]}
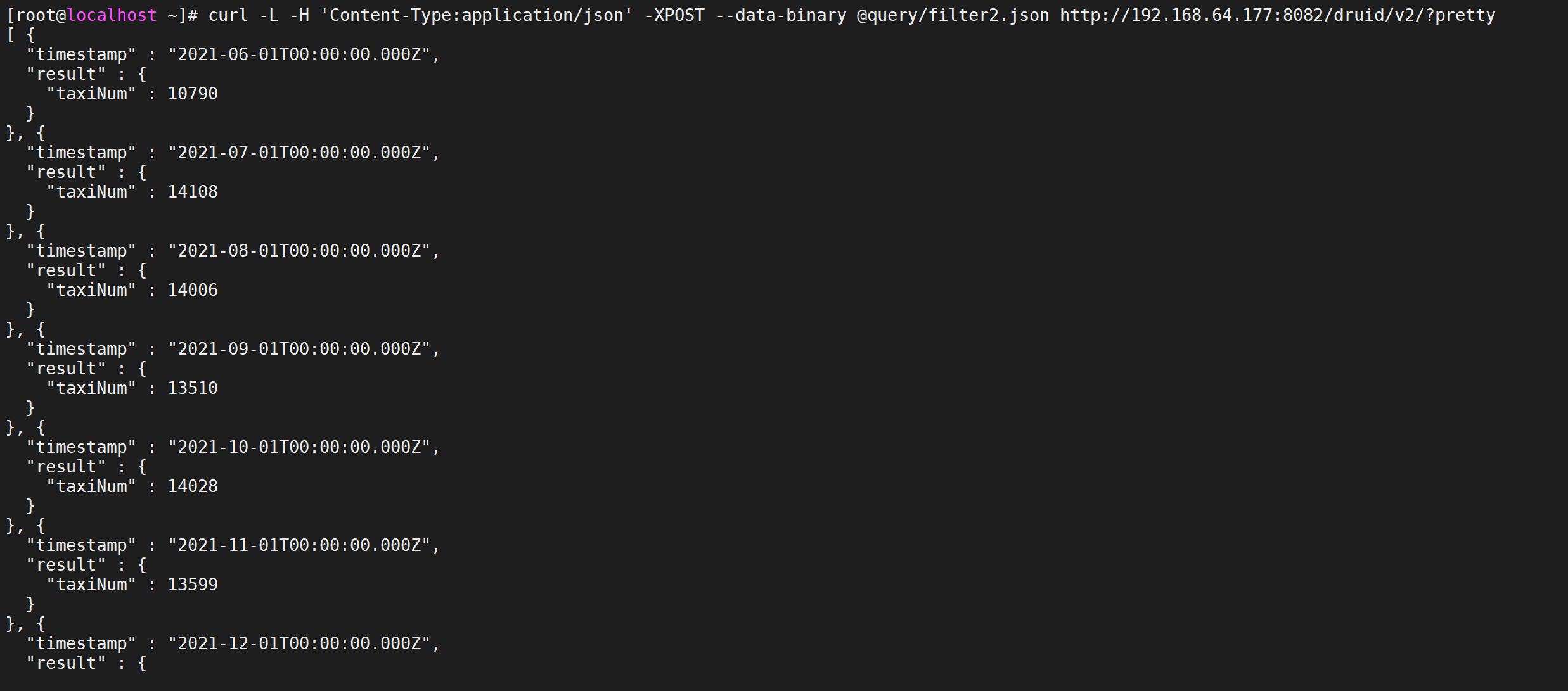
使用案例,我们查询每一个月,进行打车并且是女性的数量
vi query/filter3.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"month", "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"and", "fields":[ {"type":"selector","dimension":"status","value":1}, {"type":"selector","dimension":"sex","value":"女"} ] }, "intervals":["2021-06-07/2022-06-07"] }
进行数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter3.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.1.4 包含过滤器
In Filter类似于SQL中的in, 比如 where username in('zhangsan','lisi','zhaoliu'),它的JSON格式如下:
{ "type":"in", "dimension":"local", "values":['四川省','江西省','福建省'] }
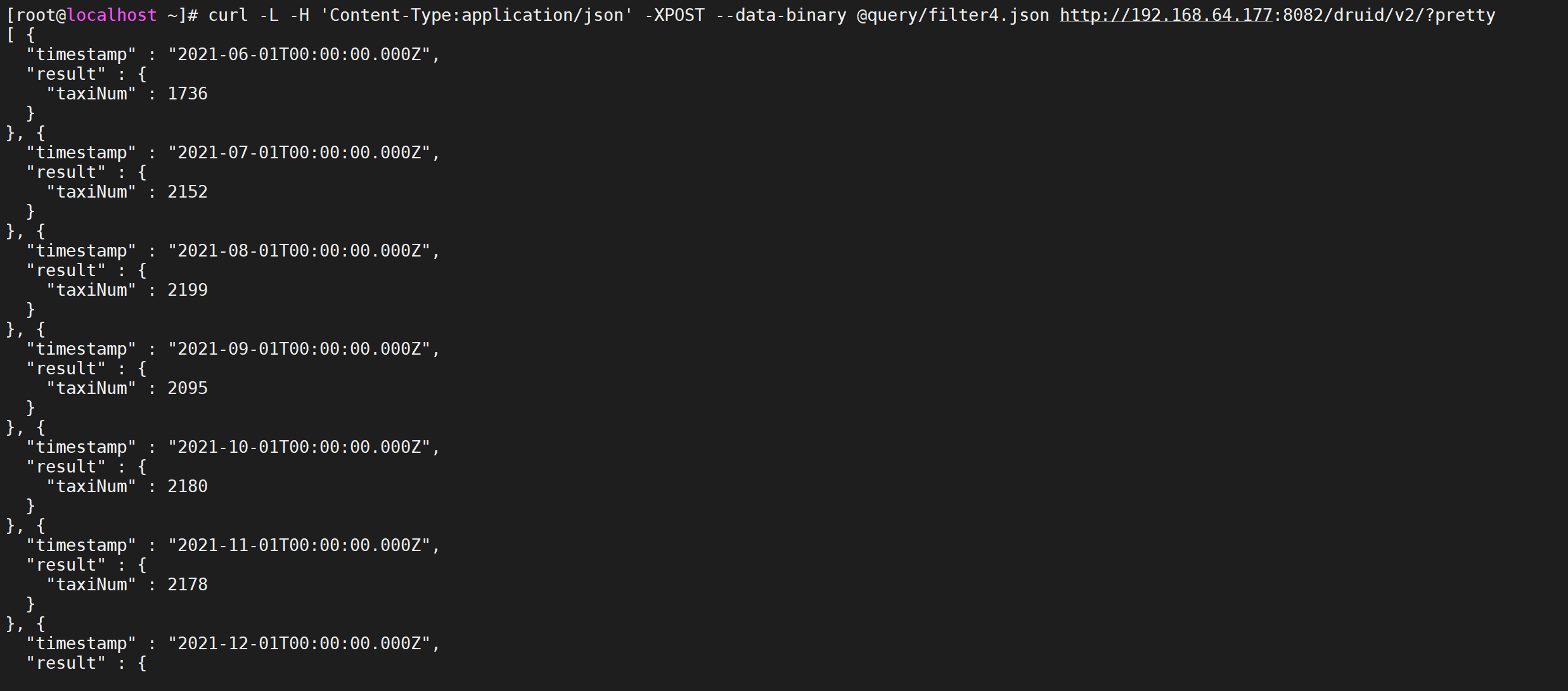
使用案例,我们查询每一个月,在四川省、江西省、福建省打车的人数
vi query/filter4.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"month", "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"in", "dimension":"local", "values":["四川省","江西省","福建省"] }, "intervals":["2021-06-07/2022-06-07"] }
进行数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter4.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.1.5 区间过滤器
Bound Filter是比较过滤器,包含大于,等于,小于三种,它默认支持的就是字符串比较,是基于字典顺序,如果使用数字进行比较,需要在查询中设定alpaNumeric的值为true,需要注意的是Bound Filter默认的大小比较为>=或者<=,因此如果使用<或>,需要指定lowerStrict值为true,或者upperStrict值为true,它的JSON格式如下: 21 <=age<=31
{ "type":"bound", "dimension":"age", "lower":"21", #默认包含等于 "upper":"31", #默认包含等于 "alphaNumeric":true #数字比较时指定alphaNumeric为true }
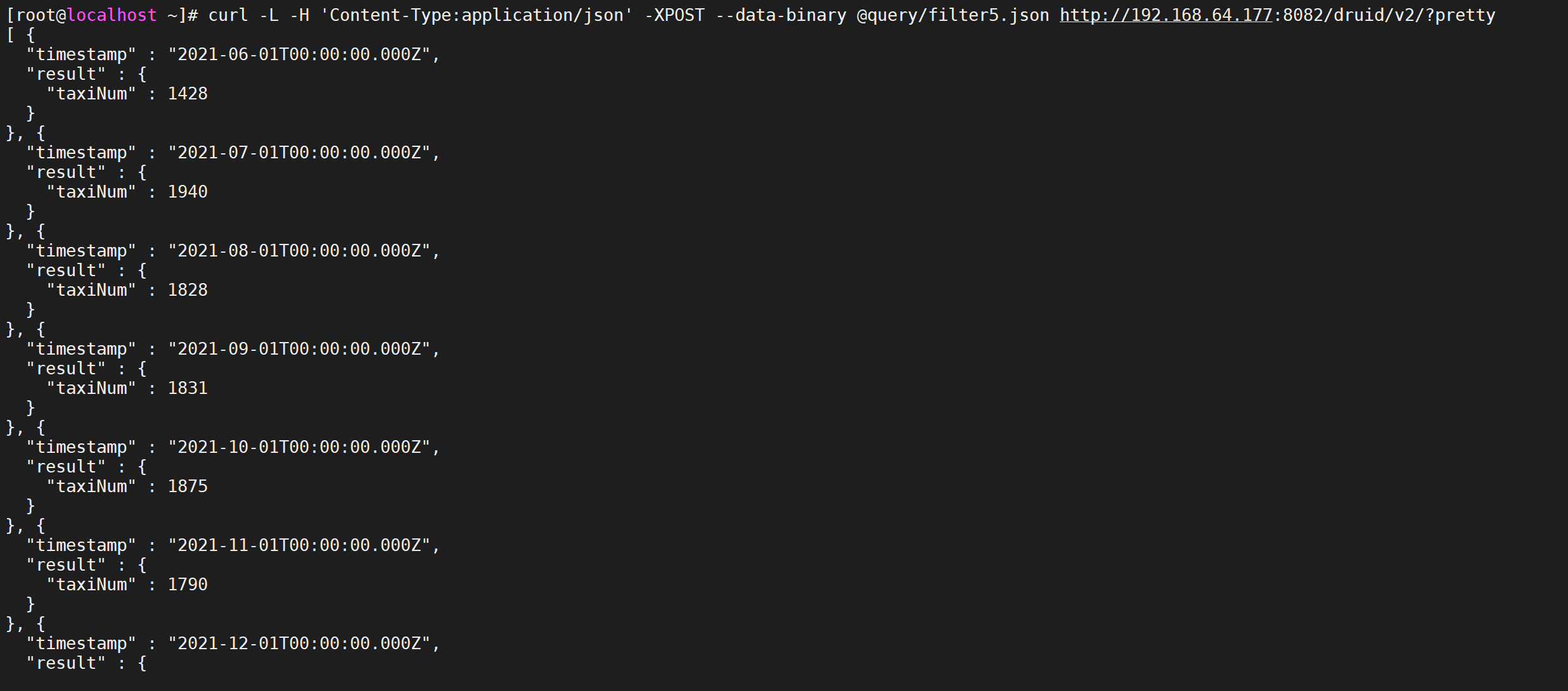
使用案例,我们查询每一个月,年龄在21-31之间打车人的数量
vi query/filter5.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"month", "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2022-06-07"] }
进行数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter5.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.2 聚合粒度
聚合粒度通过granularity配置项指定聚合时间跨度,时间跨度范围要大于等于创建索引时设置的索引粒度,druid提供了三种类型的聚合粒度分别是:Simple,Duration,Period
5.5.2.1 Simple的聚合粒度
Simple的聚合粒度通过druid提供的固定时间粒度进行聚合,以字符串表示,定义查询规则的时候不需要显示设置type配置项,druid提供的常用Simple粒度:
all,none,minute,fifteen_minute,thirty_minute,hour,day,month,Quarter(季度),year;
-
all:会将起始和结束时间内所有数据聚合到一起返回一个结果集,
-
none:按照创建索引时的最小粒度做聚合计算,最小粒度是毫秒为单位,不推荐使用性能较差;
-
minute:以分钟作为聚合的最小粒度;
-
fifteen_minute:15分钟聚合;
-
thirty_minute:30分钟聚合
-
hour:一小时聚合
-
day:天聚合
-
month:月聚合
-
Quarter:季度聚合
-
year:年聚合
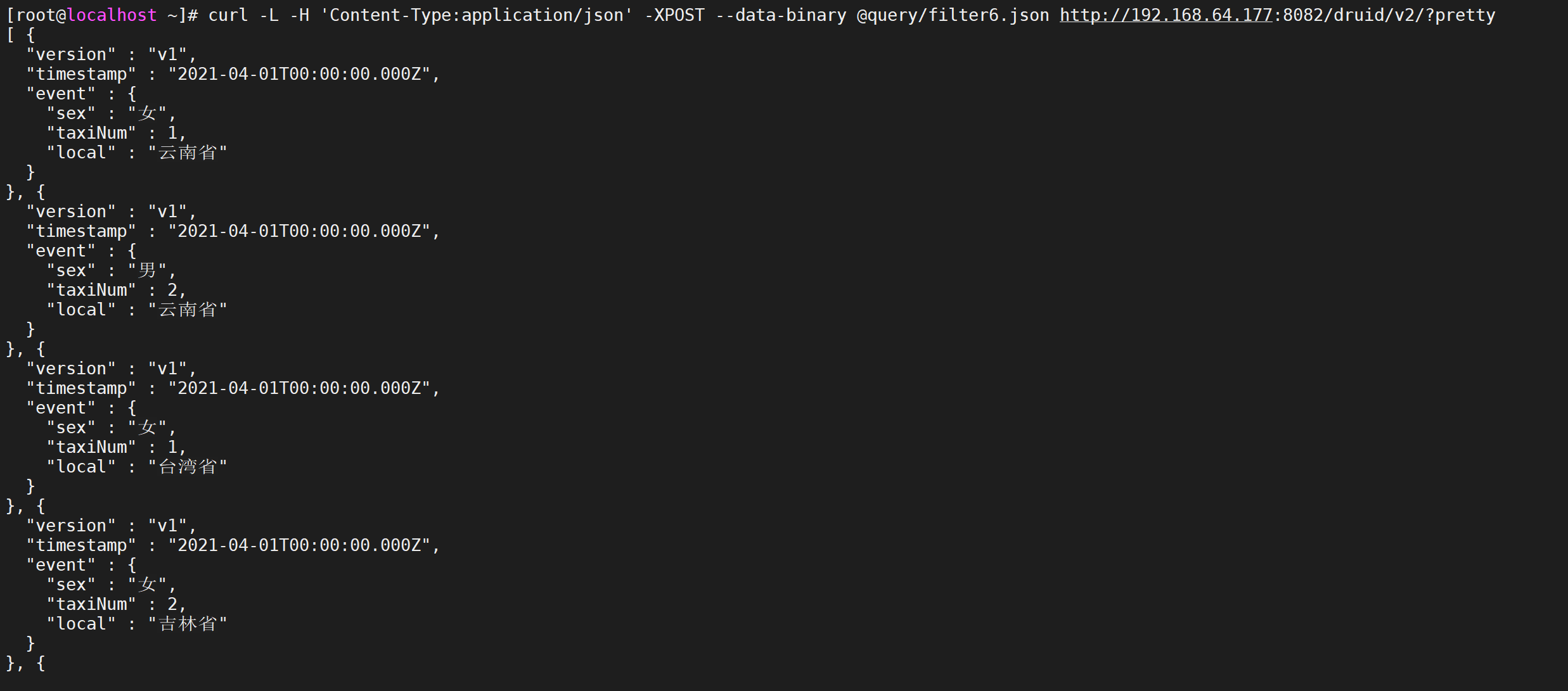
编写测试,我们这里按照季度聚合,并且我们过滤年龄是21-31的数据,并且按照地域以及性别进行分组
vi query/filter6.json
{ "queryType":"groupBy", "dataSource":"taxi_message", "granularity":"Quarter", "dimensions":["local","sex"], "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2022-06-07"] }
进行查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter6.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.2.2 Duration聚合粒度
duration聚合粒度提供了更加灵活的聚合粒度,不只局限于Simple聚合粒度提供的固定聚合粒度,而是以毫秒为单位自定义聚合粒度,比如两小时做一次聚合可以设置duration配置项为7200000毫秒,所以Simple聚合粒度不能够满足的聚合粒度可以选择使用Duration聚合粒度。
注意:使用Duration聚合粒度需要设置配置项type值为duration
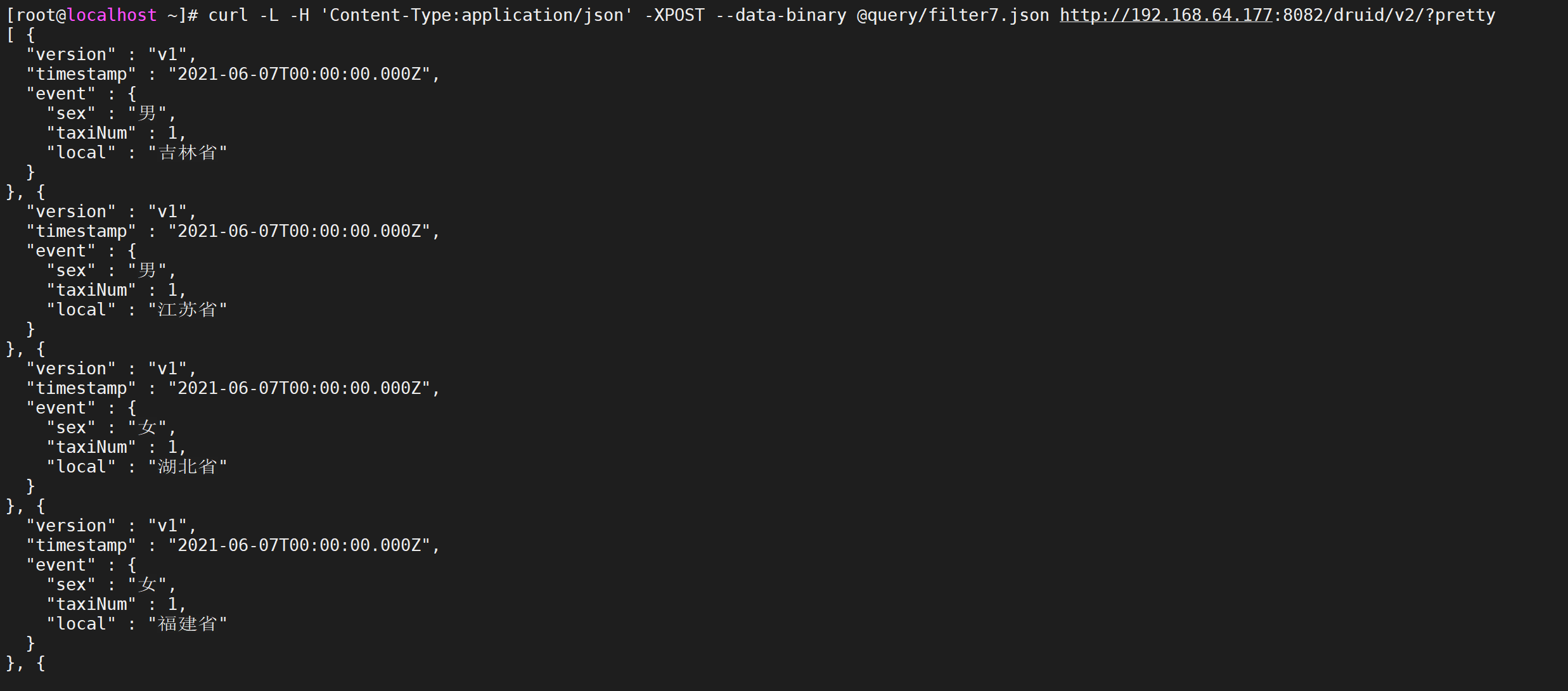
编写测试,我们按照
vi query/filter7.json
{ "queryType":"groupBy", "dataSource":"taxi_message", "granularity":{ "type":"duration", "duration":7200000 }, "dimensions":["local","sex"], "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2021-06-10"] }
数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter7.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.2.3 Period聚合粒度
Period聚合粒度采用了日期格式,常用的几种时间跨度表示方法,一小时:PT1H,一周:P1W,一天:P1D,一个月:P1M;使用Period聚合粒度需要设置配置项type值为period,
编写测试,我们按照一天进行聚合
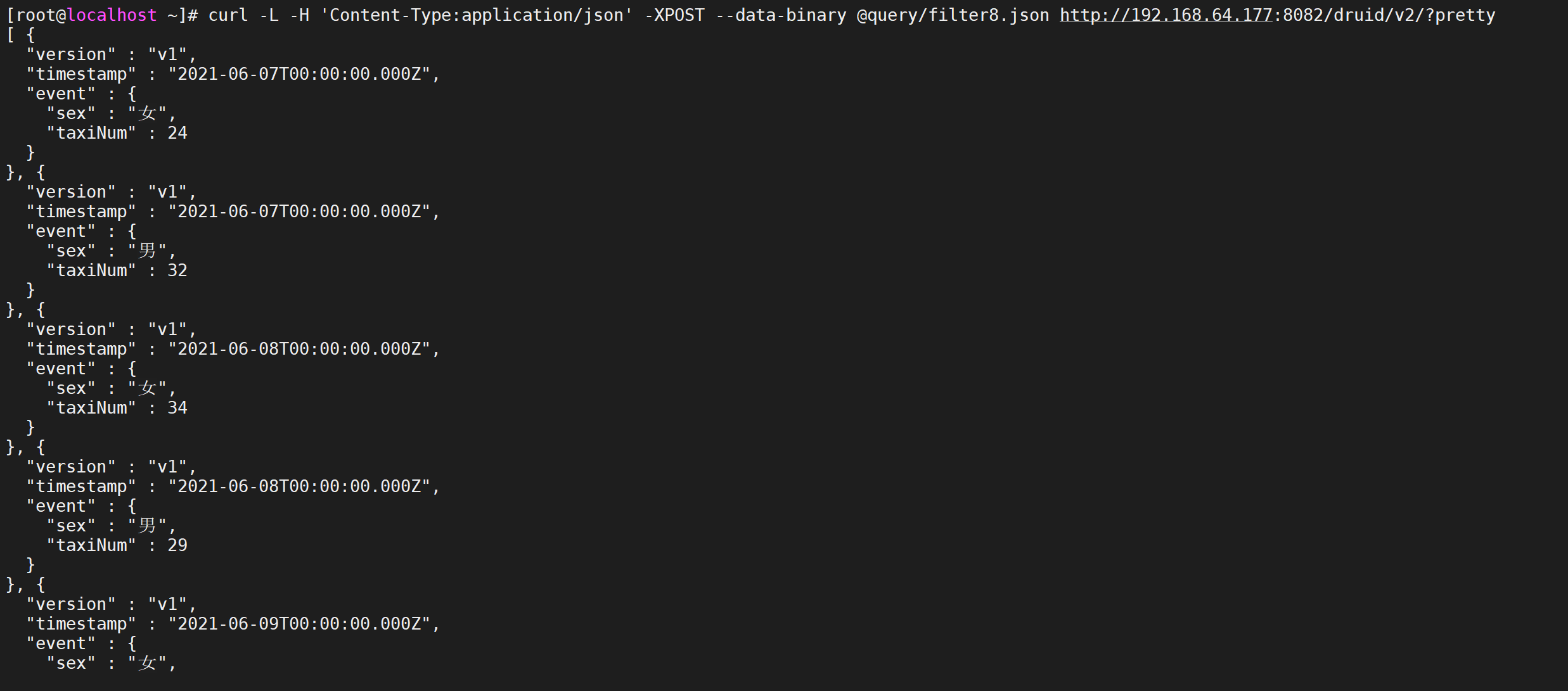
vi query/filter8.json
{ "queryType":"groupBy", "dataSource":"taxi_message", "granularity":{ "type":"period", "period":"P1D" }, "dimensions":["sex"], "aggregations":[ { "type":"count", "name":"taxiNum" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2021-06-10"] }
数据查询
curl -L -H 'Content-Type:application/json' -XPOST --data-binary @query/filter8.json http://192.168.64.177:8082/druid/v2/?pretty
5.5.3 聚合器
Aggregator是聚合器,聚合器可以在数据摄入阶段和查询阶段使用,在数据摄入阶段使用聚合器能够在数据被查询之前按照维度进行聚合计算,提高查询阶段聚合计算性能,在查询过程中,使用聚合器能够实现各种不同指标的组合计算。
5.5.3.1 公共属性
聚合器的公共属性介绍
-
type:声明使用的聚合器类型;
-
name:定义返回值的字段名称,相当于sql语法中的字段别名;
-
fieldName:数据源中已定义的指标名称,该值不可以自定义,必须与数据源中的指标名一致;
5.5.3.2 计数聚合
计数聚合器,等同于sql语法中的count函数,用于计算druid roll-up合并之后的数据条数,并不是摄入的原始数据条数,在定义数据模式指标规则中必须添加一个count类型的计数指标count;
比如想查询Roll-up 后有多少条数据,查询的JSON格式如下
vi query/aggregator1.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"Quarter", "aggregations":[ { "type":"count", "name":"count" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2022-06-07"] }
5.5.3.3 求合聚合
求和聚合器,等同于sql语法中的sum函数,用户指标求和计算,druid提供两种类型的聚合器,分别是long类型和double类型的聚合器;
第一类就是longSum Aggregator ,负责整数类型的计算,JSON格式如下:
{"type":"longSum","name":out_name,"fieldName":"metric_name"}
第二类是doubleSum Aggregator,负责浮点数计算,JSON格式如下:
{"type":"doubleSum","name":out_name,"fieldName":"metric_name"}
示例
vi query/aggregator2.json
{ "queryType":"timeseries", "dataSource":"taxi_message", "granularity":"Quarter", "aggregations":[ { "type":"longSum", "name":"ageSum", "fieldName":"age" } ], "filter":{ "type":"bound", "dimension":"age", "lower":"21", "upper":"31", "alphaNumeric":true }, "intervals":["2021-06-07/2022-06-07"] }
5.6 Druid SQL
Druid SQL是一个内置的SQL层,是Druid基于JSON的本地查询语言的替代品,它由基于 Apache Calcite的解析器和规划器提供支持
Druid SQL将SQL转换为查询Broker(查询的第一个进程)上的原生Druid查询,然后作为原生Druid查询传递给数据进程。除了在Broker上 转换SQL) 的(轻微)开销之外,与原生查询相比,没有额外的性能损失。
5.6.1 基本查询
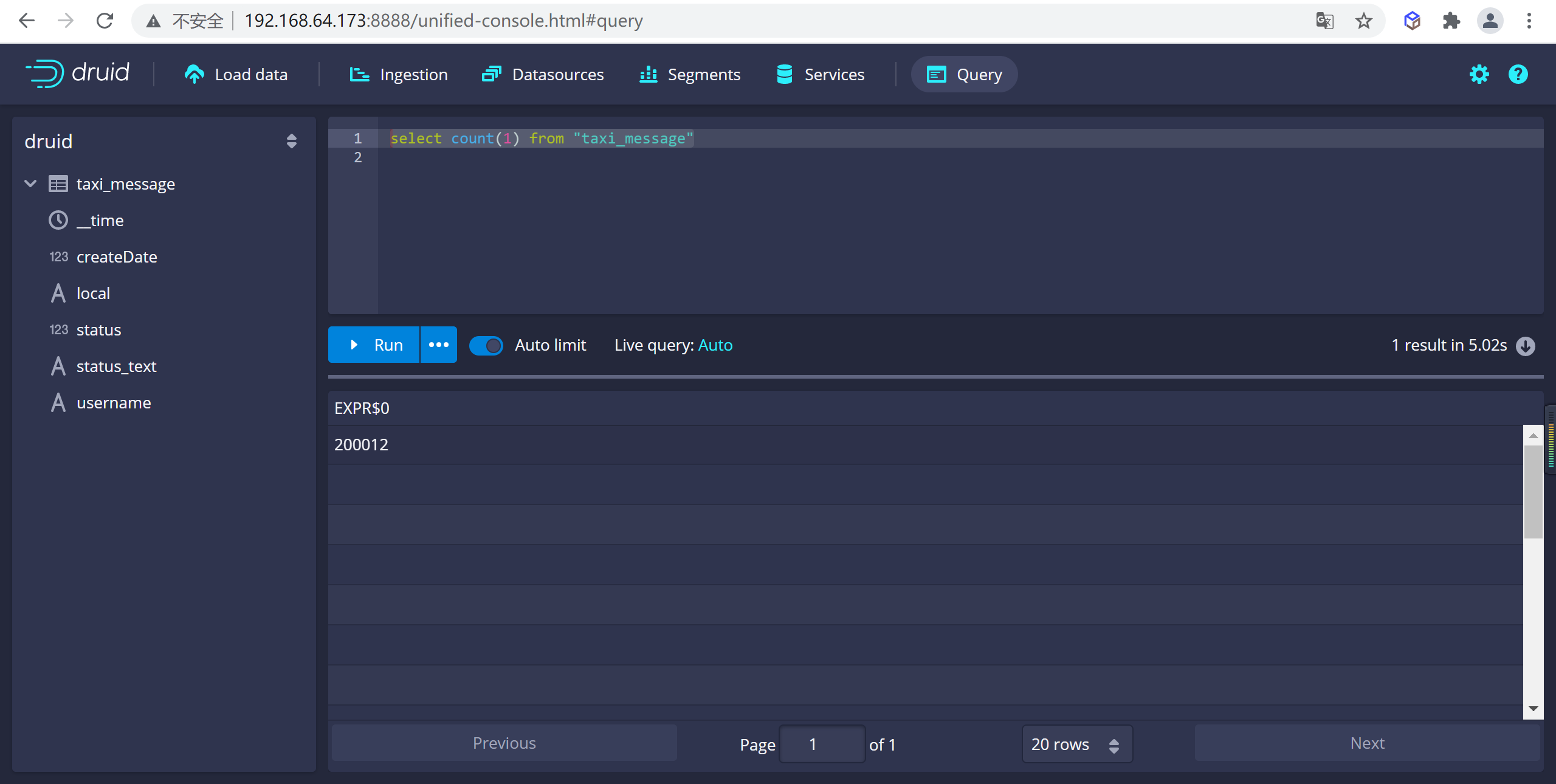
5.6.1.1 查询数据总条数
可以在druid的控制台进行查询
select count(1) from "taxi_message"
5.6.1.2 查询当前打车人数
我们可以统计出来当前的打车的人数
5.6.2 聚合功能
聚合函数可以出现在任何查询的SELECT子句中。可以使用类似语法过滤任何聚合器
AGG(expr) FILTER(WHERE whereExpr)。过滤的聚合器仅聚合与其过滤器匹配的行。同一SQL查询中的两个聚合器可能具有不同的筛选器。
只有COUNT聚合可以接受DISTINCT。
| 功能 | 笔记 |
|---|---|
COUNT(*) |
计算行数。 |
COUNT(DISTINCT expr) |
计算expr的不同值,可以是string,numeric或hyperUnique。默认情况下,这是近似值,使用HyperLogLog的变体。要获得准确的计数,请将“useApproximateCountDistinct”设置为“false”。如果这样做,expr必须是字符串或数字,因为使用hyperUnique列无法进行精确计数。另见APPROX_COUNT_DISTINCT(expr)。在精确模式下,每个查询只允许一个不同的计数。 |
SUM(expr) |
求和数。 |
MIN(expr) |
采用最少的数字。 |
MAX(expr) |
取最大数字。 |
AVG(expr) |
平均数。 |
APPROX_COUNT_DISTINCT(expr) |
计算expr的不同值,可以是常规列或hyperUnique列。无论“useApproximateCountDistinct”的值如何,这始终是近似值。另见COUNT(DISTINCT expr)。 |
APPROX_COUNT_DISTINCT_DS_HLL(expr, [lgK, tgtHllType]) |
计算expr的不同值,可以是常规列或HLL草图列。的lgK和tgtHllType参数的HLL草图文档中描述。无论“useApproximateCountDistinct”的值如何,这始终是近似值。另见COUNT(DISTINCT expr)。该DataSketches扩展必须加载使用此功能。 |
APPROX_COUNT_DISTINCT_DS_THETA(expr, [size]) |
计算expr的不同值,可以是常规列或Theta sketch列。该size参数在Theta sketch文档中描述。无论“useApproximateCountDistinct”的值如何,这始终是近似值。另见COUNT(DISTINCT expr)。该DataSketches扩展必须加载使用此功能。 |
APPROX_QUANTILE(expr, probability, [resolution]) |
计算numeric或approxHistogram exprs的近似分位数。“概率”应该在0和1之间(不包括)。“分辨率”是用于计算的质心数。分辨率越高,结果越精确,但开销也越高。如果未提供,则默认分辨率为50. 必须加载近似直方图扩展才能使用此功能。 |
APPROX_QUANTILE_DS(expr, probability, [k]) |
计算数值或Quantiles草图 exprs的近似分位数。“概率”应该在0和1之间(不包括)。该k参数在Quantiles草图文档中描述。该DataSketches扩展必须加载使用此功能。 |
APPROX_QUANTILE_FIXED_BUCKETS(expr, probability, numBuckets, lowerLimit, upperLimit, [outlierHandlingMode]) |
计算数字或固定桶直方图 exprs的近似分位数。“概率”应该在0和1之间(不包括)。的numBuckets,lowerLimit,upperLimit,和outlierHandlingMode参数在固定桶中描述直方图文档。在近似直方图扩展必须加载使用此功能。 |
BLOOM_FILTER(expr, numEntries) |
根据生成的值计算布隆过滤器,在假定正比率增加之前expr使用numEntries最大数量的不同值。有关其他详细信息,请参阅bloom filter扩展文档 |
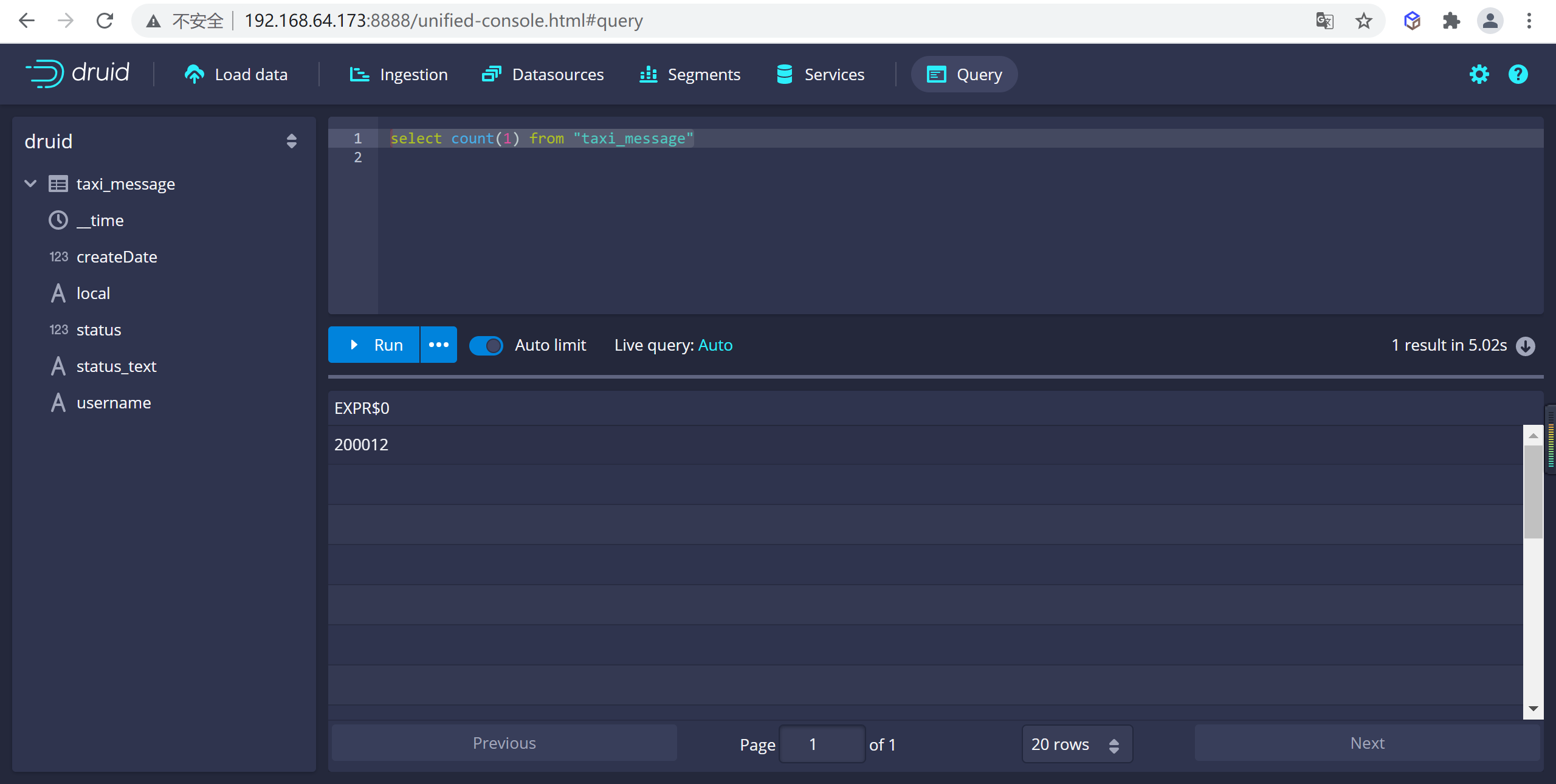
5.6.2.1 查询数据总条数
可以在druid的控制台进行查询
select count(1) from "taxi_message"
5.7 客户端API
我们在这里实现SpringBoot+Mybatis实现SQL查询ApacheDruid数据
5.7.1 引入Pom依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.2.0</version> </dependency> <dependency> <groupId>org.apache.calcite.avatica</groupId> <artifactId>avatica</artifactId> <version>1.18.0</version> </dependency> <dependency> <groupId>org.apache.calcite.avatica</groupId> <artifactId>avatica-server</artifactId> <version>1.18.0</version> </dependency> </dependencies>
5.7.1.1 配置数据源连接
在application.yml中配置数据库的连接信息
- 连接时需注意Druid时区和JVM时区,不设置时区时默认采用JVM时区
- 文档参考地址:https://calcite.apache.org/avatica/docs/client_reference.html
spring: datasource: # 连接池信息 url: jdbc:avatica:remote:url=http://192.168.64.177:8082/druid/v2/sql/avatica/ # 驱动信息 driver-class-name: org.apache.calcite.avatica.remote.Driver
5.7.2 编写代码
5.7.2.1 编写实体类
public class TaxiMessage { private String __time; private Integer age; private Integer createDate; private String local; private String sex; private Integer status; private String statusText; private String username; //setter getter 忽略 @Override public String toString() { return "TaxiMessage{" + "__time='" + __time + '\'' + ", age=" + age + ", createDate=" + createDate + ", local='" + local + '\'' + ", sex='" + sex + '\'' + ", status=" + status + ", statusText='" + statusText + '\'' + ", username='" + username + '\'' + '}'; } }
5.7.2.2 编写mapper
所有字段名、表名必须使用如下方式标识
\"表名\"
@Mapper public interface TaxiMessageMapper { @Select("SELECT * FROM \"taxi_message\" where username=#{username}") public TaxiMessage findByUserName(String username); }
5.7.2.3 编写Service
@Service public class TaxiMessageService { @Autowired private TaxiMessageMapper taxiMessageMapper; public TaxiMessage findByUserName(String username) { return taxiMessageMapper.findByUserName(username); } }
5.7.2.4 编写启动类
@SpringBootApplication @MapperScan(basePackages = "com.heima.druid.mapper") public class Application { public static void main(String[] args) { SpringApplication.run(Application.class); } }
5.7.2.5 编写测试类
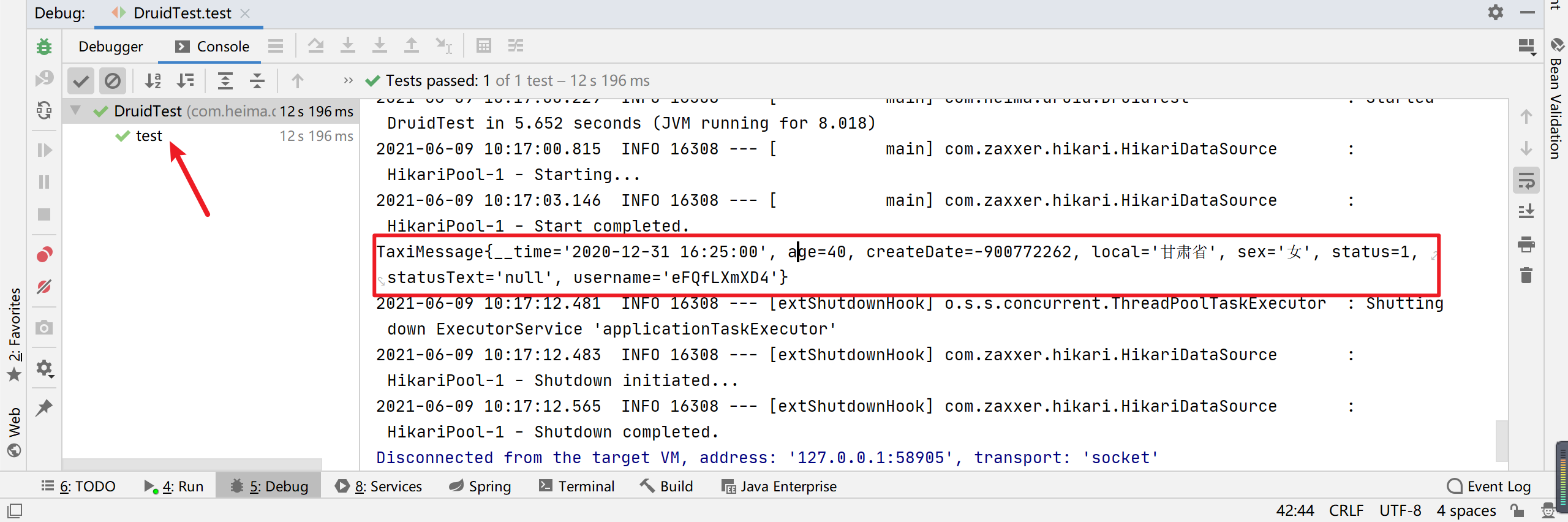
@RunWith(SpringRunner.class) @SpringBootTest(classes = Application.class) public class DruidTest { @Autowired private TaxiMessageService taxiMessageService; @Test public void test() { TaxiMessage taxiMessage = taxiMessageService.findByUserName("eFQfLXmXD4"); System.out.println(taxiMessage); Assert.assertNotNull(taxiMessage); } }
5.7.2.6 运行测试
本文由
传智教育博学谷教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通