

21:动量与学习率衰减
1:动量Momentum(惯性)
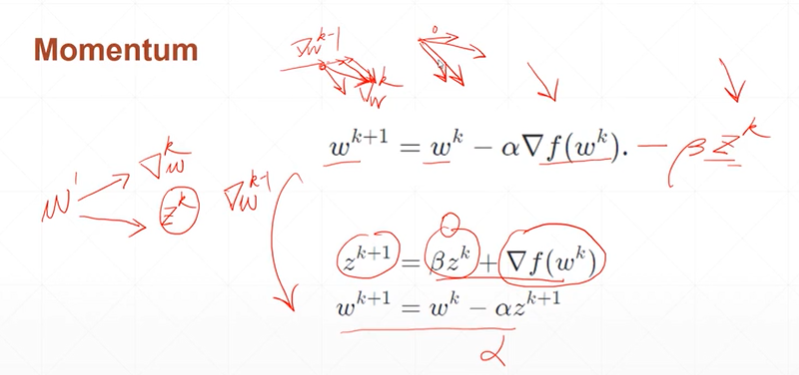
【注】简而言之:下一个梯度方向等于当前梯度的更新方向和上一个梯度方向的共同方向。
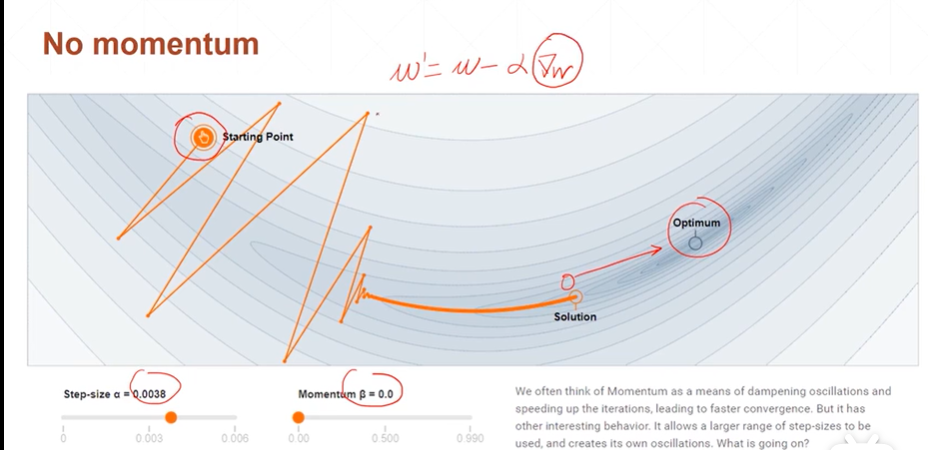
【注】当β=0,α!=0完全退化成没有添加动量的梯度更新
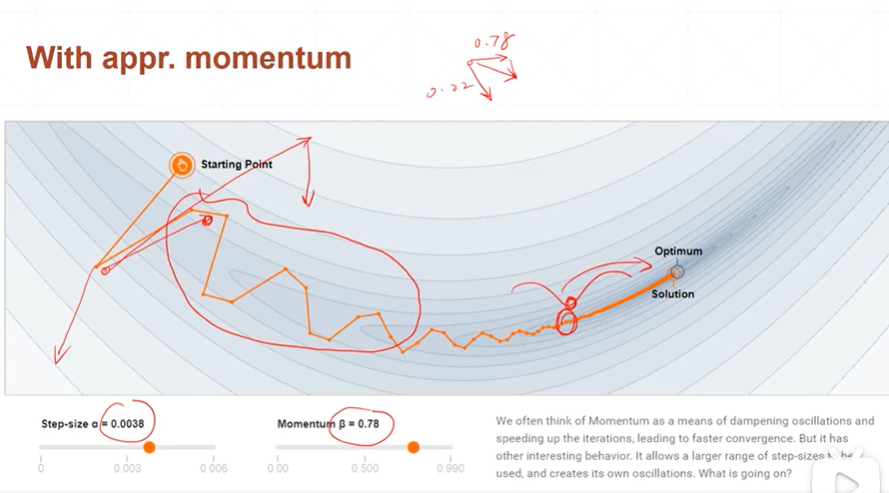
[注]当α和β都不等于0,则动量β有效,最优化时避免陷入局部极小值。
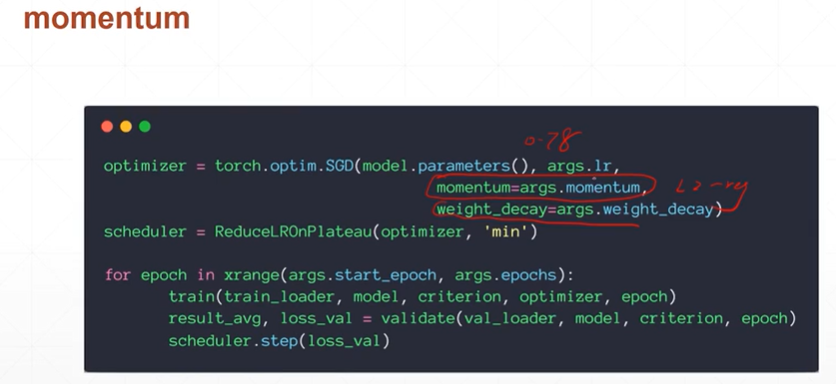
【注】在pytorch中只需要在优化器SGD中添加参数momentum就可以设置动量β。还有一些优化器例如:Adam()则momentum内嵌其中故没有momentum参数。
weight_decay参数则是为了将权值参数的范数逼近为0,以减弱过拟合现象。
2:学习率learning rate
(2.1)learning rate 的几种情况
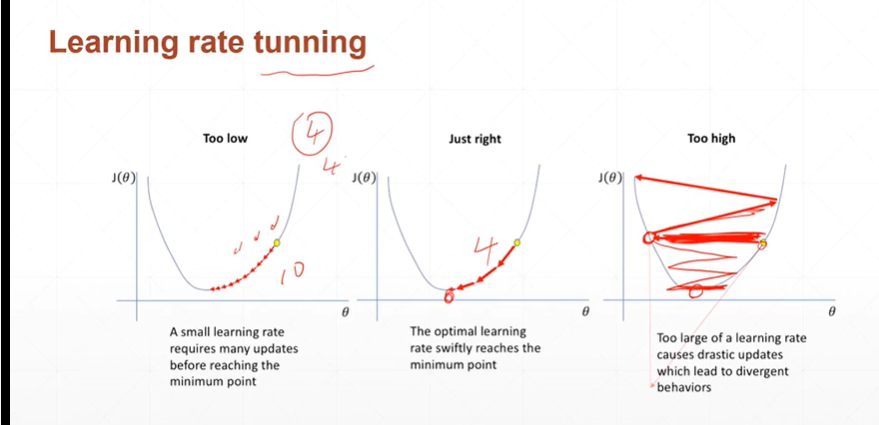
(2.2)如何选择learning rate(learning rate decay动态学习率)
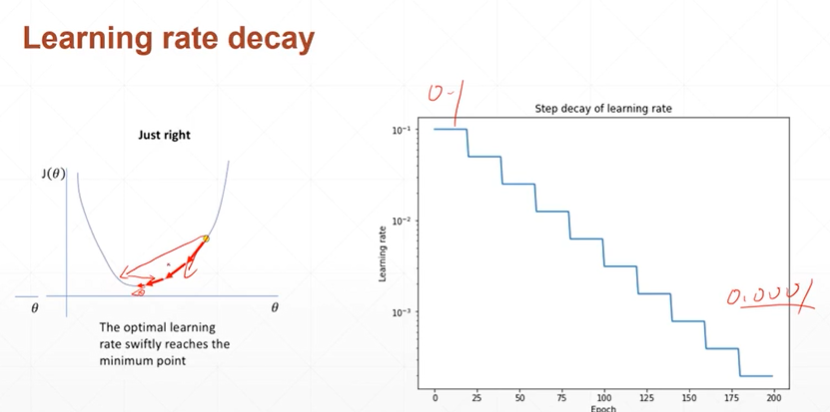
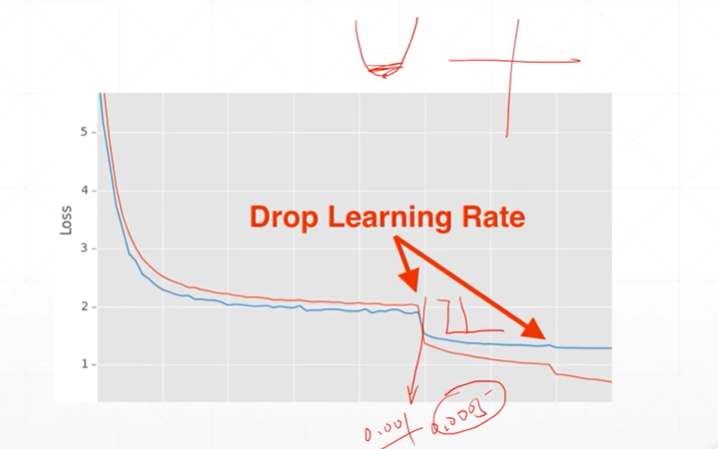
[注]learning rate decay的好处是当一个lr导致在两边振荡时,减少lr可以更有效的找到最优解。
(2.3)选择lr decay的两种方案(1:监听-微调;2:定时衰减)
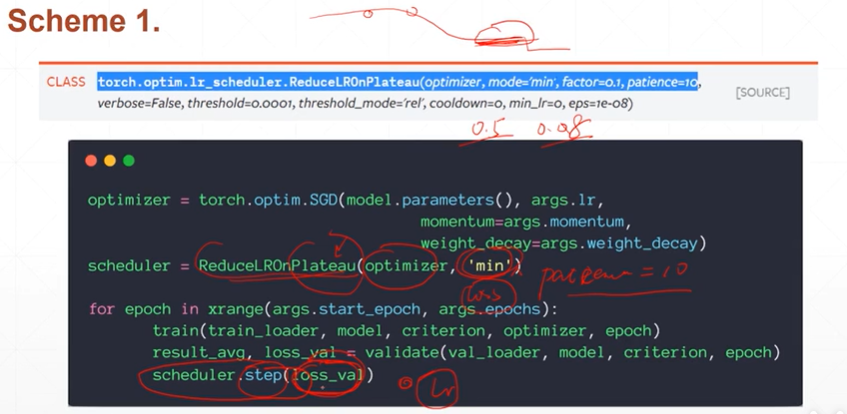
[注]当loss处于平坦期时(ReducelROnPlateau()函数可以对优化器进行管理,scheduler.step()函数可以用来监听loss是否连续多次没有改变),可以通过减少因子进行lr调整。
[注]torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)mode='min'在发现loss不再降低或者acc不再提高之后,降低学习率。patience为多少次不降低。factor为衰减因子。
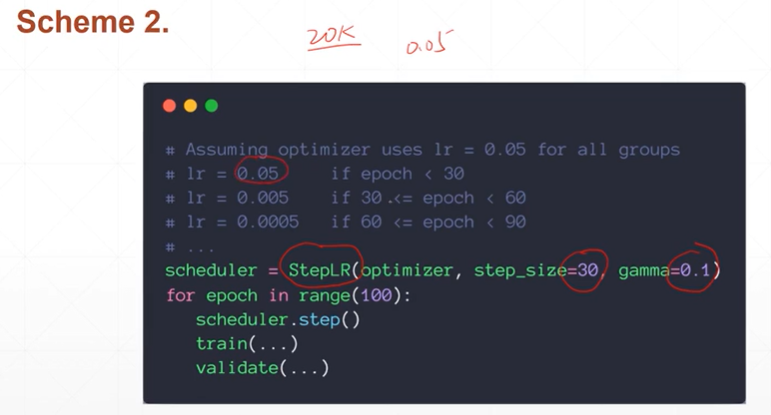
[注]直接设置,每隔多久step_size将lr衰减为原来的gamma倍。
