CNN常用图片分类网络
CNN常用图片分类网络
-
这些图片分类网络之间的关系,以及他们和RCNN等网络之间的关系,看这篇回答,说的非常好:https://www.zhihu.com/question/43370067
我稍微摘录一点:
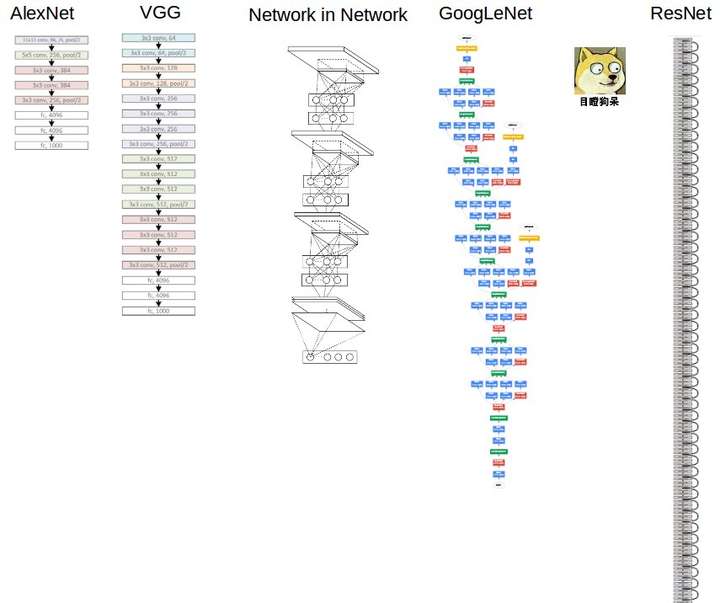
首先作者给的那个图对于从整体掌握这些网络非常有帮助:
![img]()
由于从这些pretrained网络抽出来的deep feature有良好的generalization的能力,可以应用到其他不同的CV问题,而且比传统的hand-craft feature如SIFT,bag of word要好一大截,所以得到广泛应用。目前大部分的high-level vision相关的问题,都是利用基于CNN的方法了。
最近出现蛮多论文,里面在benchmark上面的比较是自己方法的核心网络换成resnet,然后去比别人基于vgg或者alexnet的方法,自然要好不少。
对于某个CV的问题,选一个优秀的核心网络作为基础,然后fine-tune, 已经是套路。fine-tune的原因一是训练AlexNet等网络需要imagenet, places等million级别的数据,一般的CV任务都没有这么多数据。二是因为pre-trained model本身的feature已经足够generalizable,可以立刻应用到另外一个CV任务
AlexNet - > VGG: VGG可以看成是加深版本的AlexNet. 都是conv layer + FC layer
Network in Network -> GoogLeNet: NIN利用Global average pooling去掉了FC layer, 大大减少了模型大小,本身的网络套网络的结构,也激发了后来的GoogLeNet里面的各种sub-network和inception结构的设计
ResNet:这个网络跟前面几个网络都不同。
这里潜在的一个问题是这些CNN网络都是在ImageNet上面1.2million数据训练出来的,很难分析是否数据源本身会对CNN造成影响
-
VGGNet
就用一个课件来说明吧,VGGNet从原理上来看其实也不是很复杂:
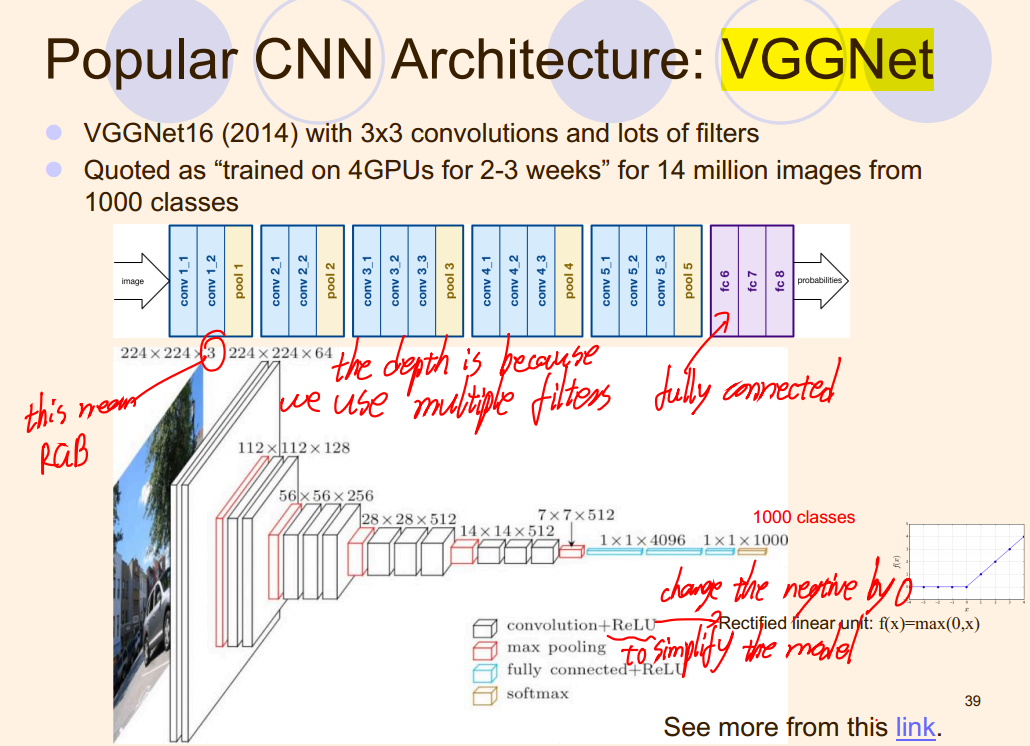
-
ResNet
看这篇文章:https://blog.csdn.net/lanran2/article/details/79057994
-
LeNet
这种比较简单的都只用图片示意了:
![img]()
来源:https://www.jianshu.com/p/58168fec534d
- 输入尺寸是32*32像素
- 卷积层:3个
- 降采样层:2个
- 全连接层:1个
- 输出:10个类别(数字0-9的概率)
-
AlexNet
看这篇文章吧:https://my.oschina.net/u/876354/blog/1633143
许多tricks,例如dropout、overlapping pooling等都是在这个网络中使用的
一幅图来总结下:
![img]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号