[转载]CNN中的激活函数
[转载]CNN中的激活函数
激活函数在DNN中就已经学过了,但是在CNN中也在用。因为有些CNN网络的描述中将激活函数叫成“激活层”,就让我误以为它是一个独立的层,会在几个卷积层之后独立配置,但是今天又回顾去看VGGNET的网络设计,发现它是将卷积层和激活层合并在一起的,如图:
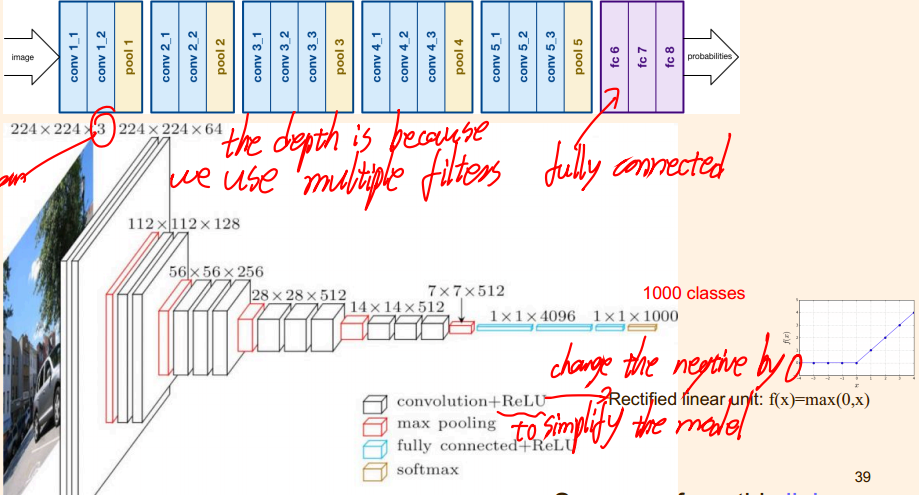
(是从笔记中截的图,所以有笔迹,见谅)
后来一想也对,因为CNN中的filter提供的线性特征,如果不加激活函数,几个卷积层复合起来其实还是多项式的形式,在网络整体中完全可以视为一层,所以只有一个卷积层加一个激活层才有意义。
顺着就多搜了点激活函数的资料,这个博主说的真不错:
来源:https://blog.csdn.net/yjl9122/article/details/70198357
激活函数
如果输入变化很小,导致输出结构发生截然不同的结果,这种情况是我们不希望看到的,为了模拟更细微的变化,输入和输出数值不只是0到1,可以是0和1之间的任何数,激活函数是用来加入非线性因素的,因为线性模型的表达力不够
这句话字面的意思很容易理解,但是在具体处理图像的时候是什么情况呢?我们知道在神经网络中,对于图像,我们主要采用了卷积的方式来处理,也就是对每个像素点赋予一个权值,这个操作显然就是线性的。但是对于我们样本来说,不一定是线性可分的,为了解决这个问题,我们可以进行线性变化,或者我们引入非线性因素,解决线性模型所不能解决的问题。
这里插一句,来比较一下上面的那些激活函数,因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的,运算特征是不断进行循环计算,所以在每代循环过程中,每个神经元的值也是在不断变化的。
这就导致了tanh特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果显示出来,但有是,在特征相差比较复杂或是相差不是特别大时,需要更细微的分类判断的时候,sigmoid效果就好了。
还有一个东西要注意,sigmoid 和 tanh作为激活函数的话,一定要注意一定要对 input 进行归一话,否则激活后的值都会进入平坦区,使隐层的输出全部趋同,但是 ReLU 并不需要输入归一化来防止它们达到饱和。构建稀疏矩阵,也就是稀疏性,这个特性可以去除数据中的冗余,最大可能保留数据的特征,也就是大多数为0的稀疏矩阵来表示。其实这个特性主要是对于Relu,它就是取的max(0,x),因为神经网络是不断反复计算,实际上变成了它在尝试不断试探如何用一个大多数为0的矩阵来尝试表达数据特征,结果因为稀疏特性的存在,反而这种方法变得运算得又快效果又好了。所以我们可以看到目前大部分的卷积神经网络中,基本上都是采用了ReLU 函数。
常用的激活函数
激活函数应该具有的性质:
(1)非线性。线性激活层对于深层神经网络没有作用,因为其作用以后仍然是输入的各种线性变换。。
(2)连续可微。梯度下降法的要求。
(3)范围最好不饱和,当有饱和的区间段时,若系统优化进入到该段,梯度近似为0,网络的学习就会停止。
(4)单调性,当激活函数是单调时,单层神经网络的误差函数是凸的,好优化。
(5)在原点处近似线性,这样当权值初始化为接近0的随机值时,网络可以学习的较快,不用可以调节网络的初始值。
目前常用的激活函数都只拥有上述性质的部分,没有一个拥有全部的~~Sigmoid函数
目前已被淘汰
缺点:
∙ 饱和时梯度值非常小。由于BP算法反向传播的时候后层的梯度是以乘性方式传递到前层,因此当层数比较多的时候,传到前层的梯度就会非常小,网络权值得不到有效的更新,即梯度耗散。如果该层的权值初始化使得f(x) 处于饱和状态时,网络基本上权值无法更新。
∙ 输出值不是以0为中心值。Tanh函数
其中σ(x) 为sigmoid函数,仍然具有饱和的问题。
ReLU函数
Alex在2012年提出的一种新的激活函数。该函数的提出很大程度的解决了BP算法在优化深层神经网络时的梯度耗散问题
优点:
∙ x>0 时,梯度恒为1,无梯度耗散问题,收敛快;
∙ 增大了网络的稀疏性。当x<0 时,该层的输出为0,训练完成后为0的神经元越多,稀疏性越大,提取出来的特征就约具有代表性,泛化能力越强。即得到同样的效果,真正起作用的神经元越少,网络的泛化性能越好
∙ 运算量很小;
缺点:
如果后层的某一个梯度特别大,导致W更新以后变得特别大,导致该层的输入<0,输出为0,这时该层就会‘die’,没有更新。当学习率比较大时可能会有40%的神经元都会在训练开始就‘die’,因此需要对学习率进行一个好的设置。
由优缺点可知max(0,x) 函数为一个双刃剑,既可以形成网络的稀疏性,也可能造成有很多永远处于‘die’的神经元,需要tradeoff。Leaky ReLU函数
改善了ReLU的死亡特性,但是也同时损失了一部分稀疏性,且增加了一个超参数,目前来说其好处不太明确
Maxout函数
泛化了ReLU和Leaky ReLU,改善了死亡特性,但是同样损失了部分稀疏性,每个非线性函数增加了两倍的参数
真实使用的时候最常用的还是ReLU函数,注意学习率的设置以及死亡节点所占的比例即可
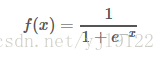
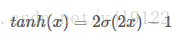
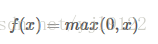
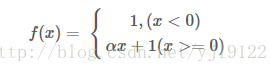
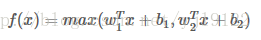
reLU的die其实很好理解,就是一旦BP的时候一个节点值的计算结果小于等于0,就会变成0,那么它在之后的BP中由于值为0,就没办法更新之后的节点的值了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号