[转载]关于Pretrain、Fine-tuning
[转载]关于Pretrain、Fine-tuning
这两种tricks的意思其实就是字面意思,pre-train(预训练)和fine -tuning(微调)
来源:https://blog.csdn.net/yjl9122/article/details/70198885
Pre-train的model:
就是指之前被训练好的Model, 比如很大很耗时间的model, 你又不想从头training一遍。这时候可以直接download别人训练好的model, 里面保存的都是每一层的parameter配置情况。(Caffe里对于ImageNet的一个model, 我记得是200+M的model大小)。你有了这样的model之后,可以直接拿来做testing, 前提是你的output的类别是一样的。
关于为什么可以直接使用别人的模型:
来源:https://zhuanlan.zhihu.com/p/22624331
由于ImageNet数以百万计带标签的训练集数据,使得如CaffeNet之类的预训练的模型具有非常强大的泛化能力,这些预训练的模型的中间层包含非常多一般性的视觉元素,我们只需要对他的后几层进行微调,在应用到我们的数据上,通常就可以得到非常好的结果。最重要的是,在目标任务上达到很高performance所需要的数据的量相对很少
如果不一样咋办,但是恰巧你又有一小部分的图片可以留着做fine-tuning, 一般的做法是修改最后一层softmax层的output数量,比如从Imagenet的1000类,降到只有20个类,那么自然最后的InnerProducet层,你需要重新训练,然后再经过Softmax层,再训练的时候,可以把除了最后一层之外的所有层的learning rate设置成为0, 这样在traing过程,他们的parameter 就不会变,而把最后一层的learning rate 调的大一点,让他尽快收敛,也就是Training Error尽快等于0.
这位博主写了几种fine-tuning的方法:
来源:https://blog.csdn.net/tianguiyuyu/article/details/80072238
举个例子,假设今天老板给你一个新的数据集,让你做一下图片分类,这个数据集是关于Flowers的。问题是,数据集中flower的类别很少,数据集中的数据也不多,你发现从零训练开始训练CNN的效果很差,很容易过拟合。怎么办呢,于是你想到了使用Transfer Learning,用别人已经训练好的Imagenet的模型来做。
做的方法有很多:
把Alexnet里卷积层最后一层输出的特征拿出来,然后直接用SVM分类。这是Transfer Learning,因为你用到了Alexnet中已经学到了的“知识”。
把Vggnet卷积层最后的输出拿出来,用贝叶斯分类器分类。思想基本同上。
甚至你可以把Alexnet、Vggnet的输出拿出来进行组合,自己设计一个分类器分类。这个过程中你不仅用了Alexnet的“知识”,也用了Vggnet的“知识”。
最后,你也可以直接使用fine-tune这种方法,在Alexnet的基础上,重新加上全连接层,再去训练网络。
综上,Transfer Learning关心的问题是:什么是“知识”以及如何更好地运用之前得到的“知识”。这可以有很多方法和手段。而fine-tune只是其中的一种手段。
简单来说
Transfer learning可以看成是一套完整的体系,是一种处理流程
目的是为了不抛弃从之前数据里得到的有用信息,也是为了应对新进来的大量数据的缺少标签或者由于数据更新而导致的标签变异情况至于说Fine-tune,在深度学习里面,这仅仅是一个处理手段
之所以现在大量采用fine-tune,是因为有很多人用实验证实了:单纯从自己的训练样本训练的model,效果没有fine-tune的好学术界的风气本就如此,一个被大家证实的行之有效的方法会在短时间内大量被采用。
所以很多人在大数据下面先按照标准参数训练一个模型
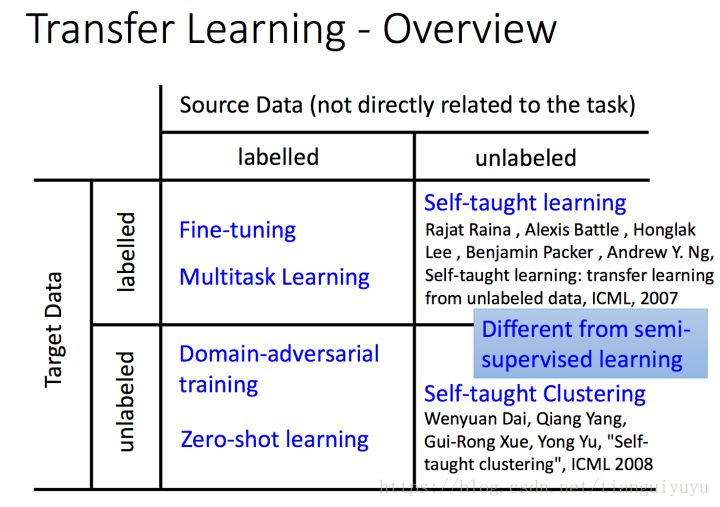
这位答主在这篇中给出了一个关于fine-tuning非常practical的例子:https://zhuanlan.zhihu.com/p/22624331

 浙公网安备 33010602011771号
浙公网安备 33010602011771号