【转载】如何理解机器学习和统计中的AUC?
如何理解机器学习和统计中的AUC?
分三部分,第一部分是对 AUC 的基本介绍,包括 AUC 的定义,解释,以及算法和代码,第二部分用逻辑回归作为例子来说明如何通过直接优化 AUC 来训练,第三部分,内容完全由 @李大猫原创——如何根据 auc 值来计算真正的类别,换句话说,就是对 auc 的反向工程。
1. 什么是 AUC?
AUC 是一个模型评价指标,只能用于二分类模型的评价,对于二分类模型,还有很多其他评价指标,比如 logloss,accuracy,precision。如果你经常关注数据挖掘比赛,比如 kaggle,那你会发现 AUC 和 logloss 基本是最常见的模型评价指标。为什么 AUC 和 logloss 比 accuracy 更常用呢?因为很多机器学习的模型对分类问题的预测结果都是概率,如果要计算 accuracy,需要先把概率转化成类别,这就需要手动设置一个阈值,如果对一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面,低于这个阈值,放进另一个类别里面。所以这个阈值很大程度上影响了 accuracy 的计算。使用 AUC 或者 logloss 可以避免把预测概率转换成类别。
最后说说AUC的优势,AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,在样本不平衡的情况下,依然能够对分类器作出合理的评价。也就是说,如果使用AUC判据,那么样本不平衡问题就没那么重要了。
例如在反欺诈场景,设欺诈类样本为正例,正例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为负例,便可以获得99.9%的准确率。
但是如果使用AUC,把所有样本预测为负例,TPRate和FPRate同时为0(没有Positive),与(0,0) (1,1)连接,得出AUC仅为0.5,成功规避了样本不均匀带来的问题。
AUC 是 Area under curve 的首字母缩写。Area under curve 是什么呢,从字面理解,就是一条曲线下面区域的面积。所以我们要先来弄清楚这条曲线是什么。这个曲线有个名字,叫 ROC 曲线。ROC 曲线是统计里面的概率,最早由电子工程师在二战中提出来(更多关于 ROC 的资料可以参考维基百科)。
ROC 曲线是基于样本的真实类别和预测概率来画的,具体来说,ROC 曲线的 x 轴是伪阳性率(false positive rate),y 轴是真阳性率(true positive rate)。那么问题来了,什么是真、伪阳性率呢?对于二分类问题,一个样本的类别只有两种,我们用 0,1 分别表示两种类别,0 和 1 也可以分别叫做阴性和阳性。当我们用一个分类器进行概率的预测的时候,对于真实为 0 的样本,我们可能预测其为 0 或 1,同样对于真实为 1 的样本,我们也可能预测其为 0 或 1,这样就有四种可能性:
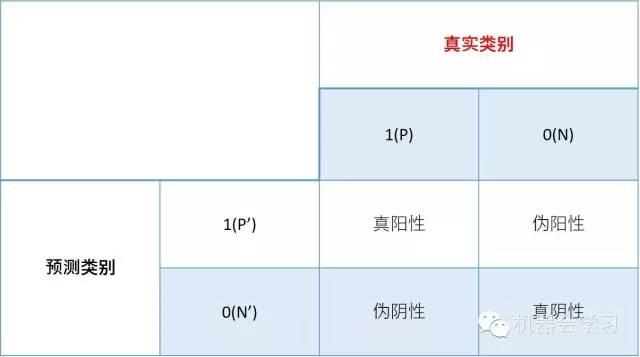
真阳性率 =(真阳性的数量)/(真阳性的数量 + 伪阴性的数量)
伪阳性率 =(伪阳性的数量)/(伪阳性的数量 + 真阴性的数量)
阈值为0,则所有样本都判断为正样本,此时伪阴性数量为0,真阳性率为1,而真阴性数量也是0,所以伪阳性率也是1;阈值为1,则所有样本都判断为负样本,此时真阳性数量为0,所以真阳性率为0,此时伪阳性数量也是0,所以伪阳性率为0。也就是说,ROC曲线一定过(0,0)和(1,1)两个点!
有了上面两个公式,我们就可以计算真、伪阳性率了。但是如何根据预测的概率得到真伪阳性、阴性的数量。
我们来看一个具体例子,比如有 5 个样本:
真实的类别(标签)是 y=c(1,1,0,0,1)
一个分类器预测样本为 1 的概率是 p=c(0.5,0.6,0.55,0.4,0.7)
如文章一开始所说,我们需要选定阈值才能把概率转化为类别,选定不同的阈值会得到不同的结果。如果我们选定的阈值为 0.1,那 5 个样本被分进 1 的类别,如果选定 0.3,结果仍然一样。如果选了 0.45 作为阈值,那么只有样本 4 被分进 0,其余都进入 1 类。一旦得到了类别,我们就可以计算相应的真、伪阳性率,当我们把选择不同阈值计算得到的所有不同真、伪阳性率连起来,就画出了 ROC 曲线,这也是为什么auc可以避免阈值的影响的原因,因为它考虑了所有的阈值,我们不需要手动做这个,因为很多程序包可以自动计算真、伪阳性率,比如在 R 里面,下面的代码可以计算以上例子的真、伪阳性率并且画出 ROC 曲线:
library(ROCR)
p=c(0.5,0.6,0.55,0.4,0.7)
y=c(1,1,0,0,1)
pred = prediction(p, y)
perf = performance(pred,"tpr","fpr")
plot(perf,col="blue",lty=3, lwd=3,cex.lab=1.5, cex.axis=2, cex.main=1.5,main="ROC plot")
上面代码可以画出下图:
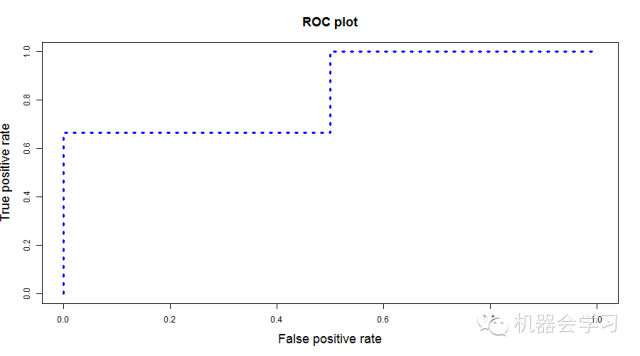
得到了 ROC 曲线,那么曲线下面的面积也就可以算出来了,同样,我们可以通过程序得到面积:
auc = performance(pred,"auc")
auc = unlist(slot(auc, "y.values"))
这个 ROC 的面积也就是我们要计算的 AUC 值。
通过 AUC 的定义我们知道了 AUC 是什么,怎么算,但是它的意义是什么呢。如果从定义来理解 AUC 的含义,比较困难,实际上 AUC 和 Mann–Whitney U test 有密切的联系,我会在第三部说明。从 Mann–Whitney U statistic 的角度来解释,AUC 就是从所有 1 样本中随机选取一个样本, 从所有 0 样本中随机选取一个样本,然后根据你的分类器对两个随机样本进行预测,把 1 样本预测为 1 的概率为 p1,把 0 样本预测为 1 的概率为 p0,p1>p0 的概率就等于 AUC。所以 AUC 反应的是分类器对样本的排序能力。根据这个解释,如果我们完全随机的对样本分类,那么 AUC 应该接近 0.5。另外值得注意的是,AUC 对样本类别是否均衡并不敏感,这也是不均衡样本通常用 AUC 评价分类器性能的一个原因。
有朋友用 python,下面代码用于在 python 里面计算 auc:
from sklearn import metrics
def aucfun(act,pred):
fpr, tpr, thresholds = metrics.roc_curve(act, pred, pos_label=1)
return metrics.auc(fpr, tpr)
2. 可以直接优化 AUC 来训练分类器吗?
答案是肯定的,我在这里给出一个简单的例子,通过直接优化 AUC 来训练一个逻辑回归模型。大家应该知道逻辑回归通常是通过极大似然估计来训练的,也就是最大化极大似然函数,这是统计里的概念,在机器学习里,对应 logloss 函数。我们通过下面的例子来训练一个逻辑回归是的 AUC 最大化:
#生成训练数据
set.seed(1999)
x1 = rnorm(1000)
x2 = rnorm(1000)
z = 1 + 2*x1 + 3*x2
pr = 1/(1+exp(-z))
y = rbinom(1000,1,pr)
#使用logloss作为训练目标函数
df = data.frame(y=y,x1=x1,x2=x2)
glm.fit=glm( y~x1+x2,data=df,family="binomial")
#下面使用auc作为训练目标函数
library(ROCR)
CalAUC <- function(real,pred){
rocr.pred=prediction(pred,real)
rocr.perf=performance(rocr.pred,'auc')
as.numeric(rocr.perf@y.values)
}
#初始值
beta0=c(1,1,1)
loss <- function(beta){
z=beta[1]+beta[2]*x1+beta[3]*x2
pred=1/(1+exp(-z))
-CalAUC(y,pred)
}
res=optim(beta0,loss,method = "Nelder-Mead",control = list(maxit = 100))
cat("直接用AUC训练:",-res$value)
cat("使用glm函数",CalAUC(y,glm.fit$fitted.values))
程序输出结果:
直接用 AUC 训练: 0.9339833
使用 glm 函数 0.9338208
可见,通过直接优化 AUC,我们得到的 AUC 比直接优化 logloss 稍大一点点点点。
根据 @西方不得不败 提示,glmnet 包自带根据 AUC 来训练逻辑回归的功能,这里就不展开说啦。
理论上讲,直接优化 AUC 在一定条件下就是 rankboost 算法(感兴趣可以参见 paper)。
对于最近十分火热的 xgboost 包,也提供了直接优化 AUC 的功能,使用起来很简单,只要把目标函数设置为:
objective = 'rank:pairwise'
3. 从 AUC 到真实类别(label)?
最开始思考这个问题是做一个网上的比赛,二分类问题,每次提交一组预测系统会计算出一个 AUC 值,因为这个比赛只有 5000 样本,并且系统显示的 AUC 值有小数点后面 7、8 位,所以我想是否可以通过可能通过 AUC 值计算出样本的真实 label 来。也许并没有实际价值,但是问题本身是很有趣的,像是在破解密码。
一个 naive 但是可行但是效率很低的办法, 就是每次生成一组预测值,里面只有一个样本预测为 1,其余都是 0,然后提交预测计算 AUC,然后根据这个 AUC 来判断此样本的 label,但是这样效率太低了,5000 个样本,需要 5000 次提交。
思考了很久,最后发现可以通过 AUC 的另一个计算公式入手。也就是第一部分说的 U statistic。
3.1 根据一个 AUC 值计算样本中 0,1 的数目
根据 AUC 与 U statistic 的联系,我们可以用下面的代码计算 AUC:
auc=(sum(rank(c(p(label==1),p(label==0)))[1:n1])-n1*(n1+1)/2)/n0/n1
上面 label 表示样本的真实类别,p 表示预测为 1 的概率,rank 是 R 的内置函数,n0 表示真实数据中 0 的数目,n1 表示 1 的数目,n0+n1=n 表示数据所有样本数目,根据这个简单的一行代码,我们可以不用任何包来计算 AUC。
上面公式很有趣,n0,n1 还有 label 都是固定的,p 不同导致 auc 不一致,观察 sum 里面,可以发现这个 sum 本质是什么?就是计算 pred 里面对应的真实 label 为 1 的那些预测值的 rank 的和。
继续使用第一部分的例子,5 个样本的预测值的 rank:
rank(c(0.5,0.6,0.55,0.4,0.7))
[1] 2 4 3 1 5
其中真实为 1 的样本(1,2,5)的对应 rank 是 2,4,5,这三个 rank 值的和 2+4+5=11,n0=2,n1=3,于是根据上面的 AUC 公式:(11-3*(3+1)/2)/2/3=5/6=0.83333,这个结果与我们在第一部分用 AUC 定义算的值完全一样。
所以说,真正影响 auc 的,就是预测值里面对本来是 1 的样本的预测的 rank 的和。
要破解真实 label,第一部要做的是找到样本里面 0 和 1 的数目,也就是 n0 和 n1 等于多少。这个问题不复杂。要知道相同预测值的 rank 也一致,就是说如果所有样本的预测只取 0 或者 1,那对应的 rank 只有两个 unique 数值。
再观察 AUC 公式里面的 sum:
sum(rank(c(pred(label1),pred(label0)))[1:n1])
这个 sum 是 n1 个数值的和,这 n1 个数值,当我们的 pred 只有两个不同取值的时候,仅包括两个 unique 的数值。继续用上面例子,一共有 5 个样本,我们生成第一组预测 p 如下:
> p=c(1,1,1,0,0)
> rank(p)
[1] 4.0 4.0 4.0 1.5 1.5
可见 p 的 rank 只有两个不同取值,1.5 和 4,这是因为预测概率 p 也只有两个不同取值。
然后我们还知道 sum 是 n1 个数的 sum,我们不知道的是这 n1 个数,里面有几个 1.5,几个 4,假设其中有 k1 个 1.5,k2 个 4,可以列出一个方程:
k1+k2=n1
k11.5+k24=sum(rank(c(p(label1),p(label0)))[1:n1])=aucn0n1+n1(1+n1)/2
所以最终得到下面的方程组:
k1+k2=n1
k11.5+k24=0.833333n0n1+n1(1+n1)/2
n0+n1=5
其中 k1,k2 和 n1 未知,两个方程,3 个未知数,属于不定方程组,但是要知道 k1,k2, 和 n1 都是整数,并且有取值范围,要借出来很简单,写一个 for 循环,1 秒中就可以找到一组满足 3 个方程多 k1,k2 以及 n1。
如果我们变更 p,比如 p=c(rep(1,m),rep(0,5-m)), 通过一样的算法,可以计算出来前 m 个样本中 1 的数量。
通过这个算法,我可以算出来这个贷款预测比赛测试数据中有 509 个 1 和 4491 个 0。
做到这里,差点就放弃了,但是后来突然又有了灵感,找到了下面的算法:
3.2 根据 AUC 破解样本的真实 label
这里就省略思考过程了, 直接来破解算法:
对于一组总数为 n 的测试样本,我们先来计算
m=floor(log(n,base=2))+1
这个 m 表示我们通过两次 auc 计算可以计算出至少多少个样本的真实 label,比如 n=5000,那么 m=13
也就是说通过我们两次提交,可以最少得到 13 个样本的 label。这 13 个样本是可以自己随便指定的,比如我们对前 13 个样本感兴趣,那么具体做法如下:
fix1=2^c(0:12)
fix2=c(fix1[-1],fix1[1])
unfixed=setdiff(1:5000,fix1)
p1=c(fix1,unfixed)#第1组预测
p2=c(fix2,unfixed)#第2组预测
使用上面的两组预测 p1 和 p2 分别计算 AUC,得到 auc1 和 auc2,根据上面给出的 auc 算法:
sum(rank(c(p1(label==1),p1(label==0)))[1:n1])-n1*(1+n1)/2=auc1*n0*n1
sum(rank(c(p2(label==1),p2(label==0)))[1:n1])-n1*(1+n1)/2=auc2*n0*n1
两个公式相减:
sum(rank(c(p1(label==1),p1(label==0)))[1:n1])-sum(rank(c(p2(label==1),p2(label==0)))[1:n1])-n1*(1+n1)/2=(auc1-auc2)*n0*n1
得到的这个等式里,我们已经通过上面的方法找到了 n0 和 n1,auc1 和 auc2 是已知,所以等式右面值可以算出,那么等式左面呢,因为我们两个预测结果 p1 和 p2 只有前三个点的预测之不一样,其余点的预测值一样,rank 也一样,那么等式左面的两个 sum 的差,其实只由前 13 个样本的真实 label 决定,具体来说:
sum1-sum2=y1*(fix1[1]-fix2[1])+y2*(fix1[2]-fix2[2])+...+y13*(fix1[13]-fix2[13])
=y1*(-1)+y2*(-2)+...+y12*(-2048)+y13*(4095)
上面的方程里面 yi 代表样本 i 的真实 label,有且只有唯一解,以为这个方程本质上就是 10 进制数用 2 进制表达。所以通过两次 auc 计算,我们可以找到 13 个点的真实标签。比如对上面提到的贷款预测比赛,选定前 13 个 label,auc1=0.50220853,auc2= 0.5017588,然后就可以算出来前 13 个 test 样本只有第三个样本是 0,其余都是 1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号