GBT、GBDT、GBRT与Xgboost
GBT、GBDT、GBRT与Xgboost
我们首先介绍下提升树,再依此介绍梯度提升树、GBDT、GBRT,最后介绍Xgboost.
- 提升树(boosting tree)
提升树(boosting tree)是以决策树为基本学习器的提升方法,它被认为是统计学习中性能最好的方法之一。对于分类问题,提升树的决策树是二叉决策树,对于回归问题,提升树中的决策是二叉回归树。
提升树模型可以表示为决策树为基学习器的加法模型:
其中, 表示第
个决策树,
为第
个决策树的参数,
为决策树的数量。
提升树采用前向分步算法,

不同问题的提升树学习算法主要区别在于使用的损失函数不同(设预测值为 ,真实值为
):

提升树的学习思想有点类似一打高尔夫球,先粗略的打一杆,然后在之前的基础上逐步靠近球洞,也就是说每一棵树学习的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
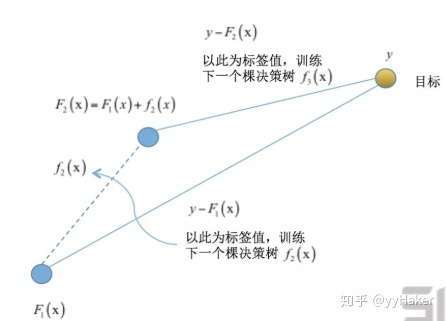
例如在回归问题中,提升树采用平方误差损失函数,此时:
其中 为当前模型拟合数据的残差。所以对回归问题的提升树算法,第
个决策树
只需要简单拟合当前模型的残差。
详细的回归提升树算法如下:

2. 梯度提升树(GBT)
Freidman提出了梯度提升树算法(GBT)。
梯度提升树(GBT)的一个核心思想是利用损失函数的负梯度在当前模型的值作为残差的近似值,本质上是对损失函数进行一阶泰勒展开,从而拟合一个回归树。至于为什么用损失函数的负梯度替代残差,看这里:https://www.cnblogs.com/jiading/articles/12899791.html
看了之前的不少回答感觉都没答到点子上,题主问的是为什么前向分步时不直接拟合残差?
简单来讲就一句话,为了可以扩展到更复杂的损失函数中。
这时候你可能就有疑问了,难道不是所有的损失函数都在
时最小吗?
那可能你忘了正则项这一回事,如果只是经验风险最小化的话非常容易过拟合,所以一个合理的办法就是在每个基模型中加入正则项,所以在有正则项的情况下就不再是
时损失函数最小了,所以我们需要计算损失函数的梯度,而不能直接使用分模型来拟合残差。
回忆泰勒展开公式:
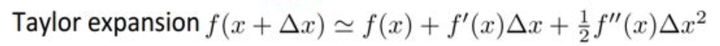
将损失函数使用一阶泰勒展开公式( 相当于这里的
):
则有:
要使得损失函数降低,则根据梯度下降的思想让损失函数对 进行求导,按照负梯度更新改值,则损失函数是下降的,即:

这里我们相当于获得了样本的标签,接下来就是用这个标签来训练决策树。
另外,梯度提升树用于分类模型时,是梯度提升决策树GBDT;用于回归模型时,是梯度提升回归树GBRT,二者的区别主要是损失函数不同。
例如GBRT算法的伪代码如下:

另外,Freidman从bagging策略受到启发,采用随机梯度提升来修改了原始的梯度提升算法,即每一轮迭代中,新的决策树拟合的是原始训练集的一个子集(而并不是原始训练集)的残差,这个子集是通过对原始训练集的无放回随机采样而来,类似于自助采样法。
这种方法引入了随机性,有助于改善过拟合,另一个好处是未被采样的另一部分字集可以用来计算包外估计误差。
GBT和随机森林(RF)的比较:
(1)从模型框架的角度看:

(2)从偏差分解的角度来看:

(3)如果在梯度提升树和随机森林之间二选一,几乎总是建议选择梯度提升树。

3. Xgboost
Xgboost也使用与提升树相同的前向分步算法,其区别在于:Xgboost通过结构风险最小化来确定下一个决策树的参数 :
其中:

与提升树不同的是,Xgboost还使用了二阶泰勒展开。
定义:
其中 分别为损失函数
对
的一阶导数和二阶导数。
回忆到泰勒展开式是:
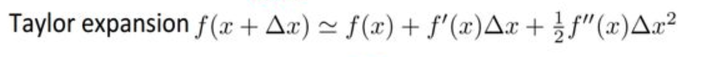
因此我们对损失函数二阶泰勒展开有( 相当于这里的
):
可以看到提升树(GBT)只使用了一阶泰勒展开.
另外正则化项由两部分构成:
该部分表示决策树的复杂度,其中 为叶节点的个数,
为每个叶节点的输出值,
为系数,控制这两个部分的比重。

该复杂度是一个经验公式。事实上还有很多其他的定义复杂度的方式,只是这个公式效果还不错。
然后用类似牛顿法的方式进行迭代。在训练决策树时,还采用了类似于随机森林的策略,对特征向量的分量进行抽样。
Xgboost相比与GBDT:
(1) 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。例如,xgboost支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)
(2) xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
(3)列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样(即每次的输入特征不是全部特征),不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
(4)并行化处理:在训练之前,预先对每个特征内部进行了排序找出候选切割点,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行,即在不同的特征属性上采用多线程并行方式寻找最佳分割点。
(个人认为后面两个,更改的GBDT也可以做到,相比于GBDT,Xgboost最重要的优点还是用到了二阶泰勒展开信息和加入正则项)
参考资源:
【1】
【2】
集成学习综述-从决策树到XGBoostmp.weixin.qq.com
【3】
yuyuqi:ID3、C4.5、CART、随机森林、bagging、boosting、Adaboost、GBDT、xgboost算法总结zhuanlan.zhihu.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号