
北京市政百姓信件分析实战——采集北京市政百姓信件内容
一、 采集北京市政百姓信件内容
什么是爬虫
网络爬虫,也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理。
互联网上的页面极多,即使是最大的爬虫系统也无法做出完整的索引。因此在公元2000年之前的万维网出现初期,搜索引擎经常找不到多少相关结果。现在的搜索引擎在这方面已经进步很多,能够即刻给出高质量结果。
爬虫还可以验证超链接和HTML代码,用于网络抓取。
利用爬虫可以做哪些有趣的事
1.爬取古诗文 http://so.gushiwen.org/mingju/ju_4652.aspx
- 《小松》 唐代 杜荀鹤
- 自小刺头深草里,而今渐觉出蓬蒿。
- 时人不识凌云木,直待凌云始道高。
2.爬取电商数据: 如意淘、惠惠购物助手、西贴、购物党https://gwdang.com/trend
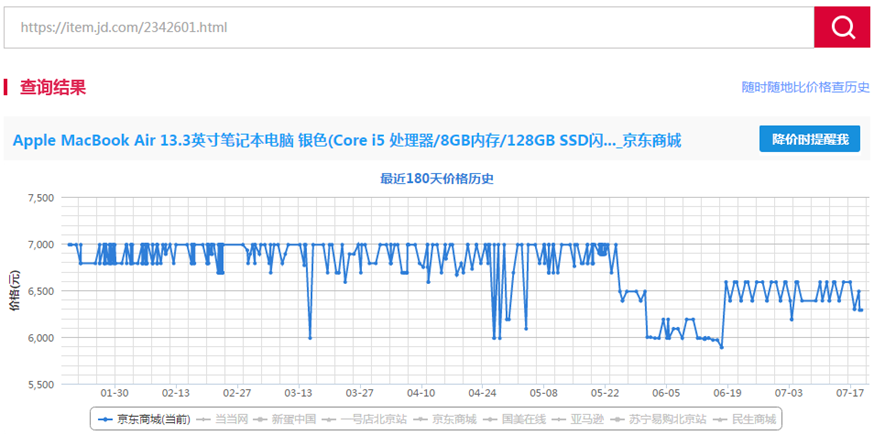
3. 爬取社会化媒体 http://ys.8wss.com/

4.爬取金融数据,量化分析
5.爬取新闻数据,舆情、 文章聚合等
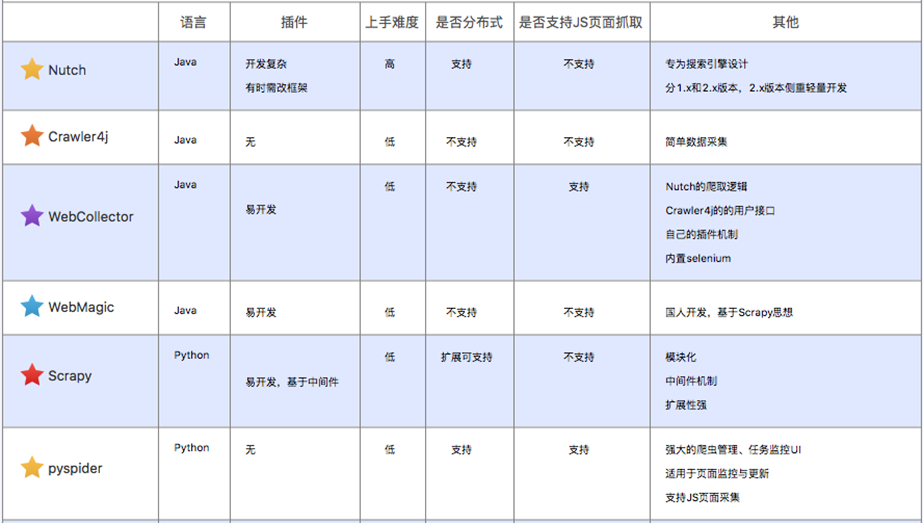
常见的爬虫框架
1.Java语言开发的分布式爬虫:Nutch
分布式爬虫,主要是解决两个方面的问题:①海量URL管理 ②网速。
Nutch一般应用于搜索引擎
Nutch依赖于Hadoop运行
2.JAVA语言开发的单机爬虫:Crawler4j、WebMagic、WebCollector
3.Python语言开发的单机爬虫:scrapy、PySpider
4.自己动手,编写爬虫
关于webmagic
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
WebMagic的设计参考了业界最优秀的爬虫Scrapy,而实现则应用了HttpClient、Jsoup等Java世界最成熟的工具,目标就是做一个Java语言Web爬虫的教科书般的实现。
网站:http://webmagic.io/
中文文档:http://webmagic.io/docs/zh/
爬虫架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy,但是实现方式更Java化一些。
而Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
WebMagic总体架构图如下:
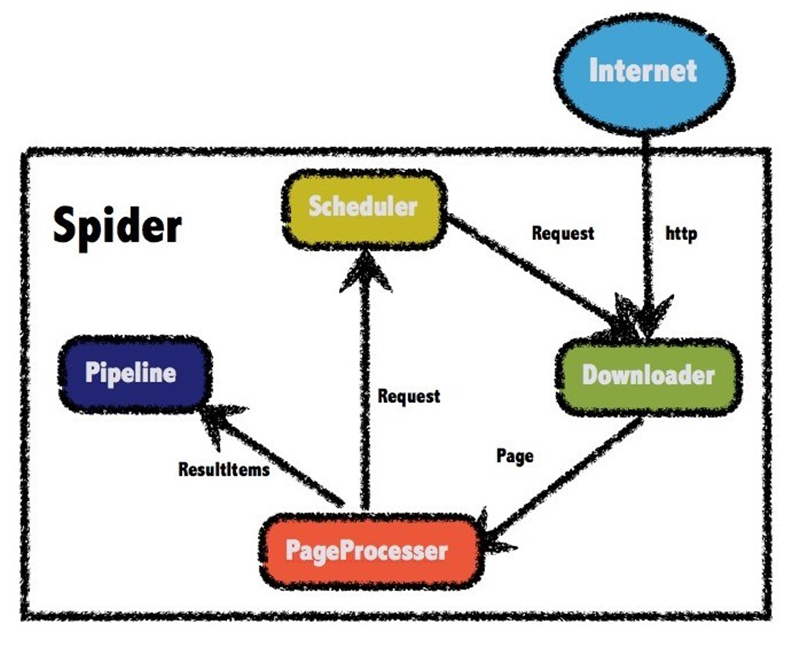
组件讲解
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
爬取策略
1.并行策略
一个并行爬虫是并行运行多个进程的爬虫。它的目标是最大化下载的速度,同时尽量减少并行的开销和下载重复的页面。为了避免下载一个页面两次,爬虫系统需要策略来处理爬虫运行时新发现的URL,因为同一个URL地址,可能被不同的爬虫进程抓到。
2.重新访问策略
网站的属性之一就是经常动态变化,而爬取网站的一小部分往往需要花费几个星期或者几个月。等到网站爬虫完成它的爬取,很多事件也已经发生了,包括增加、更新和删除。 在搜索引擎的角度,因为没有检测这些变化,会导致存储了过期资源的代价。
3.平衡礼貌策略
爬虫相比于人,可以有更快的检索速度和更深的层次,所以,他们可能使一个站点瘫痪。不需要说一个单独的爬虫一秒钟要执行多条请求,下载大的文件。一个服务器也会很难响应多线程爬虫的请求。 就像Koster所注意的那样,爬虫的使用对很多任务作都是很有用的,但是对一般的社区,也需要付出代价。使用爬虫的代价包括:
网络资源:在很长一段时间,爬虫使用相当的带宽高度并行地工作。
服务器超载:尤其是对给定服务器的访问过高时。
质量糟糕的爬虫,可能导致服务器或者路由器瘫痪,或者会尝试下载自己无法处理的页面。
个人爬虫,如果过多的人使用,可能导致网络或者服务器阻塞。
对这些问题的局部解决方法是漫游器排除协议(Robots exclusion protocol),也被称为robots.txt议定书
4.选择策略
链接跟随限制
URL规范化
路径上移爬取
主题爬取
分析网页源码结构
采集网页实验中,得到需要爬取的网页网址是重中之重,
我们以首都之窗网站为例,使用浏览器,输入网址:
http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?type=firstPage
进入该网站信件了 列表页
1.分析信件的列表页网址,选择“下页”,点击右键,选择“检查”

进入,如下图所示的源码界面,蓝色部分为下一页的链接,
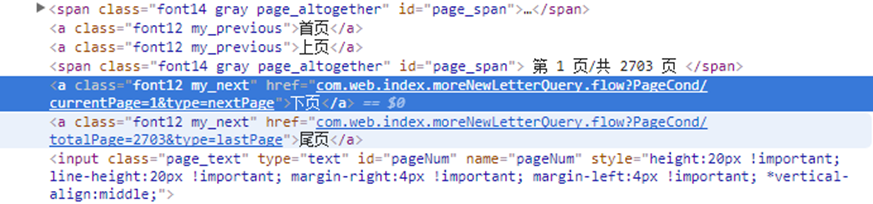
通过对多个列表页中下页的链接分析,可以发现规律:currentPage代码的为当前页面,type=nextPage为下一页的意思,即该网址链接的页面是当前页面的下一页网址。
2.分析信件的详细信息的网址,选择一条投诉信件,点击右键,选择“检查”

进入源码页,红框部分为该信件网址

另外选择一条咨询信件, 点击右键,选择“检查”
进入源码页,红框部分为该信件网址

选择信件,点击右键,选择“检查”

进入源码页,红框部分为该信件网址

通过对不同类别不同信件的网址进行分析,得出规律:网址中consult.consultDetail代码信件为咨询类型,originalId是信件的编号,网址其他部分一致。
得到这一规律后,可以利用正则对列表页的网页源码进行匹配,从而得到信件的详细页网址。
注意:对于分析网页源码首先是要在网页空白处右键,选择“查看网页源码“,检查要爬取的内容是否存在网页源码中。
搭建爬虫代码框架
1.切换目录到/data/目录下,创建名为edu1的目录
- cd /data/
- mkdir /data/edu1
2.切换目录到/data/edu1目录下,使用wget命令,下载webmagic爬虫项目所依赖的lib包
- cd /data/edu1
- wget http://192.168.1.100:60000/allfiles/second/edu1/webmagic-0.7-libs.tar.gz
将webmagic-0.7-libs.tar.gz压缩包,解压缩。
- tar -xzvf webmagic-0.7-libs.tar.gz
3.打开eclipse开发工具
新建Java Project,命名为pachong1
点击项目名pachong1,新建一个目录,命名为libs,并将/data/edu1/webmagic-0.7-libs下的所有的jar包,拷贝到libs目录下。并选中所有jar包,右键点击“Build Path” => “Add to Build Path”
4.在pachong1项目下,点击src => New => Package新建一个包
在弹出窗口中,输入包名my.webmagic
在my.webmagic包下,新建class类
将新建的类,命名为Getgov,搭建完的代码框架如下:
5.代码编写
在WebMagic里,实现一个基本的爬虫只需要编写一个类,实现 us.codecraft.webmagic.processor.PageProcessor接口即可。这个类基本上包含了抓取一个网站,需要写的所有代码。实现接口后,重写里面的getSite和process方法
- import us.codecraft.webmagic.Page;
- import us.codecraft.webmagic.Site;
- import us.codecraft.webmagic.processor.PageProcessor;
- public class Getgov implements PageProcessor {
- @Override
- public Site getSite() {
- return null;
- }
- @Override
- public void process(Page arg0) {
- }
- }
模拟爬虫为普通用户
getSite()方法,返回的数据类型为us.codecraft.webmagic.Site类型。也就是对当前爬虫,进行设置,包括编码、抓取间隔、超时时间、重试次数等,也包括一些模拟的参数,例如User Agent、cookie,以及代理的设置。
- private Site site = Site.me().setDomain("club.jd.com").setSleepTime(2000);
如果想设置更详细内容,可以这样做:
- private Site site = Site.me()
- .setDomain("club.jd.com")
- .setSleepTime(2000)
- .addCookie("TrackID", "1_VWwvLYiy1FUr7wSr6HHmHhadG8d1-Qv-TVaw8JwcFG4EksqyLyx1SO7O06_Y_XUCyQMksp3RVb2ezA")
- .addCookie("__jda", "122270672.1507607632.1423495705.1479785414.1479794553.92")
- .addCookie("__jdb", "122270672.1.1507607632|92.1479794553")
- .addCookie("__jdc", "122270672")
- .addCookie("__jdu", "1507607632")
- .addCookie("__jdv", "122270672|direct|-|none|-|1478747025001")
- .addCookie("areaId", "1")
- .addCookie("cn", "0")
- .addCookie("ipLoc-djd", "1-72-2799-0")
- .addCookie("ipLocation", "%u5317%u4EAC")
- .addCookie("mx", "0_X")
- .addCookie("rkv", "V0800")
- .addCookie("user-key", "216123d5-4ed3-47b0-9289-12345")
- .addCookie("xtest", "4657.553.d9798cdf31c02d86b8b81cc119d94836.b7a782741f667201b54880c925faec4b")
- .addHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11")
- .addHeader("Accept", "text/html;q=0.9,*/*;q=0.8")
- .addHeader("Accept-Charset", "ISO-8859-1,utf-8;q=0.7,*;q=0.3")
- .addHeader("Connection", "close")
- .addHeader("Referer", "https://www.jd.com/")
- .setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.65 Safari/537.31");
这里一些项目内容,例如setDomain的值、setUserAgent的值,可以从这里获取
这里的setDomain是请求的Host地址
最终,将site对象,在getSite方法作为结果返回。
处理页面内容
process方法,是webmagic爬虫的核心部分,可以从下载到的Html页面,抽取到想要的信息。WebMagic里主要使用了三种抽取技术:XPath、正则表达式和CSS选择器。
- page.putField("allhtml", page.getHtml().toString());
设置Scheduler
Scheduler是WebMagic中进行URL管理的组件。一般来说,Scheduler包括两个作用:①对待抓取的URL队列进行管理; ②对已抓取的URL进行去重。
WebMagic内置了几个常用的Scheduler:
通过观察url可以发现规律,currentPage表示页码,并从1开始依次增加,type=nextPage表示抓取当前页面的下一页,
addTargetRequests(List requests) 添加url 去抓取,使用for循环,得到想抓取的url,并将抓取的url放到内存队列中存储。
由此抓取该网站列表页:
- for (int i = 1; i < 2702; i++) {
- urlstr = "http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?PageCond/currentPage="
- + i + "&type=nextPage";
- page.addTargetRequest(urlstr);
使用正则表达式匹配列表页中的详细页的链接,得到链接以后通过addTargetRequests抓取详细页。
- page.addTargetRequests(page.getHtml().links()
- .regex("(com.web.\\w+.\\w+.flow\\?originalId=\\w+)").all());
在main函数中,Spider是爬虫启动的入口。在启动爬虫之前,我们需要使用一个PageProcessor创建一个Spider对象,然后使用run()进行启动。同时Spider的其他组件(Downloader、Scheduler、Pipeline)都可以通过set方法来进行设置。
- Spider.create(new Getgov())
- .addUrl("http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?type=firstPage")
- .addPipeline(new FilePipeline("/data/edu1"))
- .thread(5)
- .run();
在此段代码中
.addUrl 爬虫初始化时,需要爬取的第一个页面。
.addPipeline(new FilePipeline("/data/edu1"))设置爬取结果存储形式和位置,保存位置是/data/edu1。
.addPipeline(new ConsolePipeline()) 设置爬取结果存储形式和位置,这里将结果同时输出到console页面。
.setScheduler(new FileCacheQueueScheduler()) 使用文件保存抓取的URL,可以在关闭程序并下次启动时,从之前抓取的URL继续抓取。需指定路径,会建立.urls.txt和.cursor.txt两个文件。
执行测试
完整代码如下
- package my.webmagic;
- import us.codecraft.webmagic.Page;
- import us.codecraft.webmagic.Site;
- import us.codecraft.webmagic.Spider;
- import us.codecraft.webmagic.pipeline.FilePipeline;
- import us.codecraft.webmagic.processor.PageProcessor;
- import us.codecraft.webmagic.scheduler.FileCacheQueueScheduler;
- public class Getgov implements PageProcessor {
- private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
- public void process(Page page) {
- page.putField("allhtml", page.getHtml().toString());
- String urlstr = null;
- for (int i = 1; i < 2702; i++) {
- urlstr = "http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?PageCond/currentPage="
- + i + "&type=nextPage";
- page.addTargetRequest(urlstr);
- page.addTargetRequests(page.getHtml().links()
- .regex("(com.web.\\w+.\\w+.flow\\?originalId=\\w+)").all());
- }
- }
- public Site getSite() {
- return site;
- }
- public static void main(String[] args) {
- Spider.create(new Getgov())
- .addUrl("http://rexian.beijing.gov.cn/default/com.web.index.moreNewLetterQuery.flow?type=firstPage")
- .addPipeline(new FilePipeline("/data/edu1"))
- .setScheduler(new FileCacheQueueScheduler("/data/edu1"))
- .thread(5)
- .run();
- }
- }
在项目上,右键,点击Run As => Java Application
打开桌面“终端模拟器”,进入命令行模式
切换目录到/data/edu1/rexian.beijing.gov.cn下,查看数据情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号