Spark基础实验六——Spark Streaming 编程初级实践
一、实验目的
(1)通过实验学习日志采集工具 Flume 的安装和使用方法;
(2)掌握采用 Flume 作为 Spark Streaming 数据源的编程方法。
二、实验平台
操作系统: Ubuntu16.04
Spark 版本:2.1.0
Flume 版本:1.7.0
三、实验内容和要求
1.安装 Flume
Flume 是 Cloudera 提供的一个分布式、可靠、可用的系统,它能够将不同数据源的海量
日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。Flume 的
核心是把数据从数据源收集过来,再送到目的地。请到 Flume 官网下载 Flume1.7.0 安装文
件,下载地址如下:
http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
或者也可以直接到本教程官网的 “ 下 载 专 区 ” 中 的 “ 软 件 ” 目 录 中 下 载
apache-flume-1.7.0-bin.tar.gz。
下载后,把 Flume1.7.0 安装到 Linux 系统的“/usr/local/flume”目录下,具体安装和使
用方法可以参考教程官网的“实验指南”栏目中的“日志采集工具 Flume 的安装与使用方
法”。
参考博客:https://dblab.xmu.edu.cn/blog/1102/
下载成功
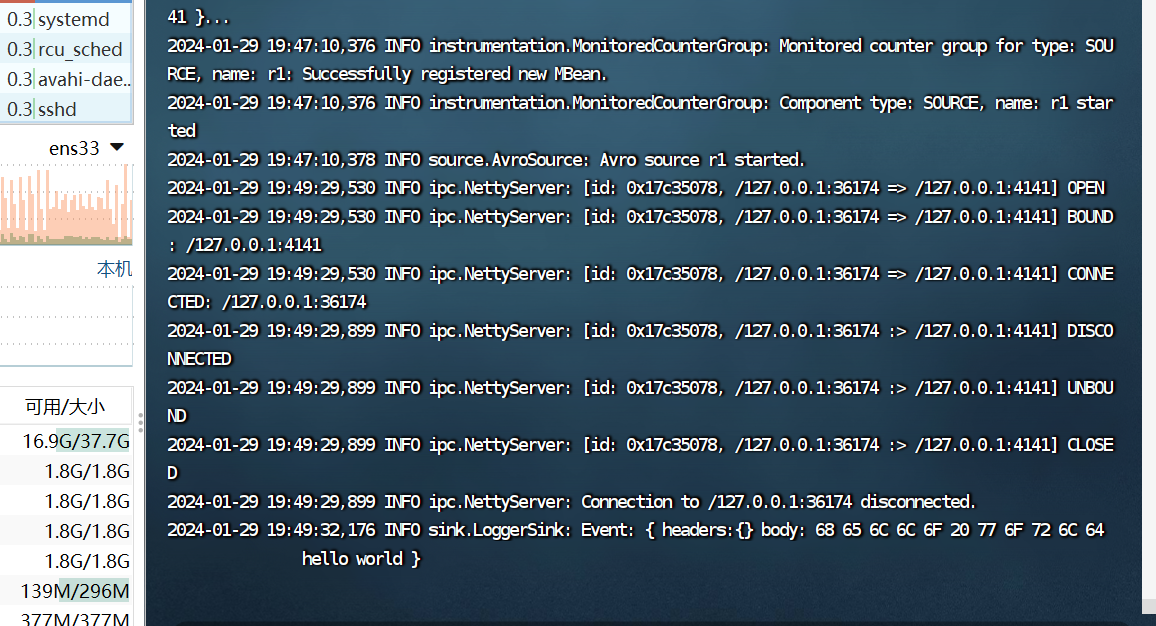
2. 使用 Avro 数据源测试 Flume
Avro 可以发送一个给定的文件给 Flume,Avro 源使用 AVRO RPC 机制。请对 Flume
的相关配置文件进行设置,从而可以实现如下功能:在一个终端中新建一个文件
helloworld.txt(里面包含一行文本“Hello World”),在另外一个终端中启动 Flume 以后,
可以把 helloworld.txt 中的文本内容显示出来。
3. 使用 netcat 数据源测试 Flume
请对 Flume 的相关配置文件进行设置,从而可以实现如下功能:在一个 Linux 终端(这
里称为“Flume 终端”)中,启动 Flume,在另一个终端(这里称为“Telnet 终端”)中,
输入命令“telnet localhost 44444”,然后,在 Telnet 终端中输入任何字符,让这些字符可以
顺利地在 Flume 终端中显示出来。
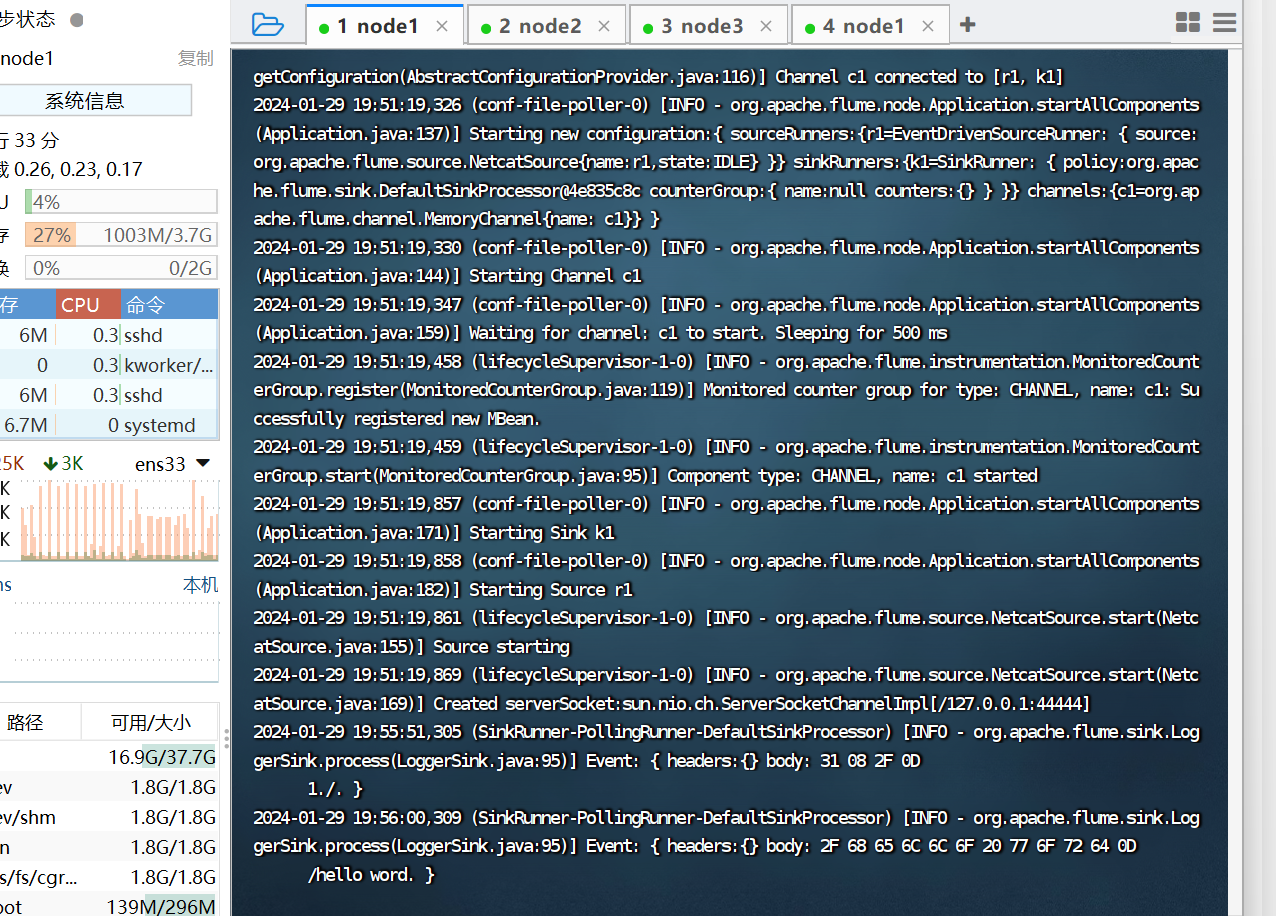
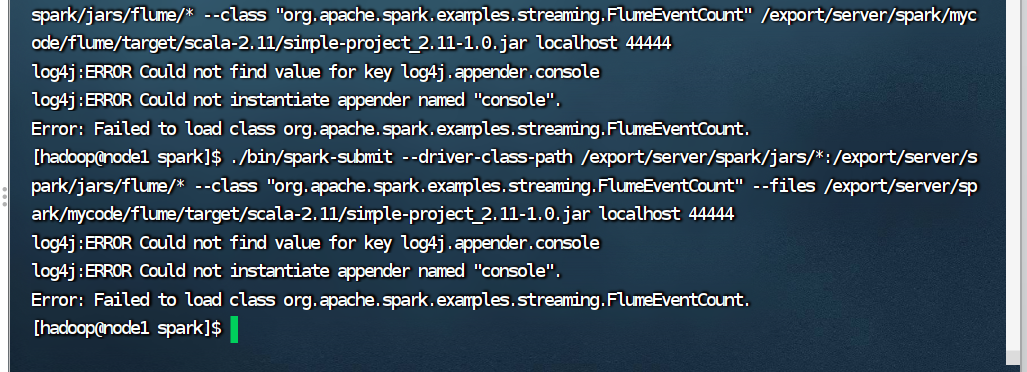
4.使用 Flume 作为 Spark Streaming 数据源
Flume 是非常流行的日志采集系统,可以作为 Spark Streaming 的高级数据源。请把 Flume
Source 设置为 netcat 类型,从终端上不断给 Flume Source 发送各种消息,Flume 把消息汇集
到 Sink,这里把 Sink 类型设置为 avro,由 Sink 把消息推送给 Spark Streaming,由自己编写
的 Spark Streaming 应用程序对消息进行处理。
参考博客:https://dblab.xmu.edu.cn/blog/1357/
我的最后结果出现了bug,暂时修改不了,很痛苦