

Spark基础实验一-Linux 系统的安装和常用命令
一、实验目的
(1)掌握 Linux 虚拟机的安装方法。Spark 和 Hadoop 等大数据软件在 Linux 操作系统
上运行可以发挥最佳性能,因此,本教程中,Spark 都是在 Linux 系统中进行相关操作,同
时,下一章的 Scala 语言也会在 Linux 系统中安装和操作。鉴于目前很多读者正在使用
Windows 操作系统,因此,为了顺利完成本教程的后续实验,这里有必要通过本实验,让读
者掌握在 Windows 操作系统上搭建 Linux 虚拟机的方法。当然,安装 Linux 虚拟机只是安
装 Linux 系统的其中一种方式,实际上,读者也可以不用虚拟机,而是采用双系统的方式安
装 Linux 系统。本教程推荐使用虚拟机方式。
(2)熟悉 Linux 系统的基本使用方法。本教程全部在 Linux 环境下进行实验,因此,
需要读者提前熟悉 Linux 系统的基本用法,尤其是一些常用命令的使用方法。
二、实验平台
操作系统:Windows 系统和 CentOS。
三、实验内容和要求
1.安装 Linux 虚拟机
2.使用 Linux 系统的常用命令
启动 Linux 虚拟机,进入 Linux 系统,通过查阅相关 Linux 书籍和网络资料,或者参考
本教程官网的“实验指南”的“Linux 系统常用命令”,完成如下操作:
(1)切换到目录 /usr/bin;

(2)查看目录/usr/local 下所有的文件;
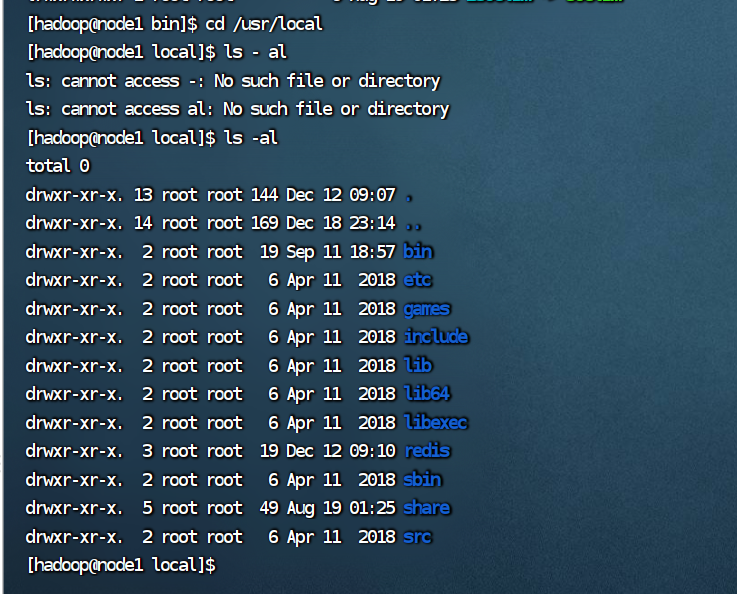
(3)进入/usr 目录,创建一个名为 test 的目录,并查看有多少目录存在;
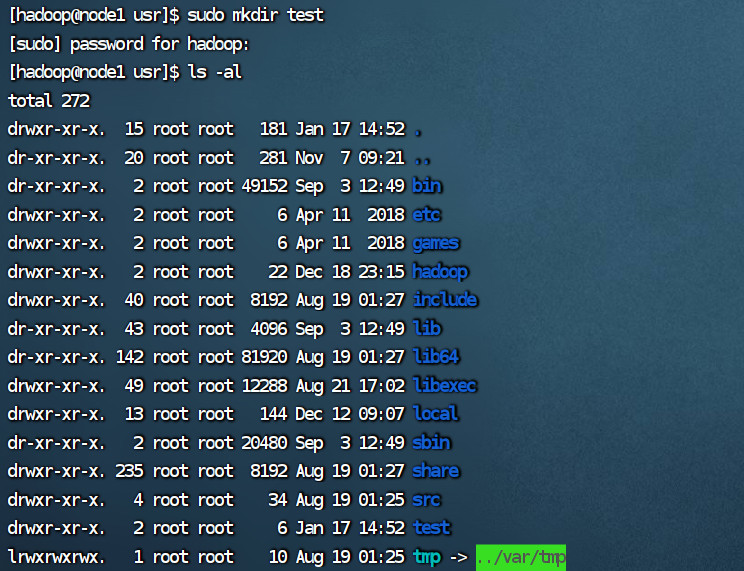
(4)在/usr 下新建目录 test1,再复制这个目录内容到/tmp;

(5)将上面的/tmp/test1 目录重命名为 test2;

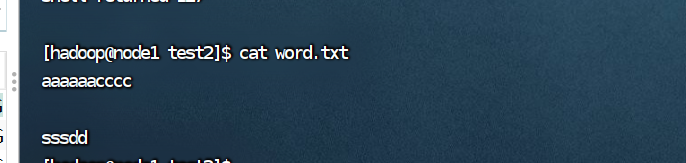
(6)在/tmp/test2 目录下新建 word.txt 文件并输入一些字符串保存退出;
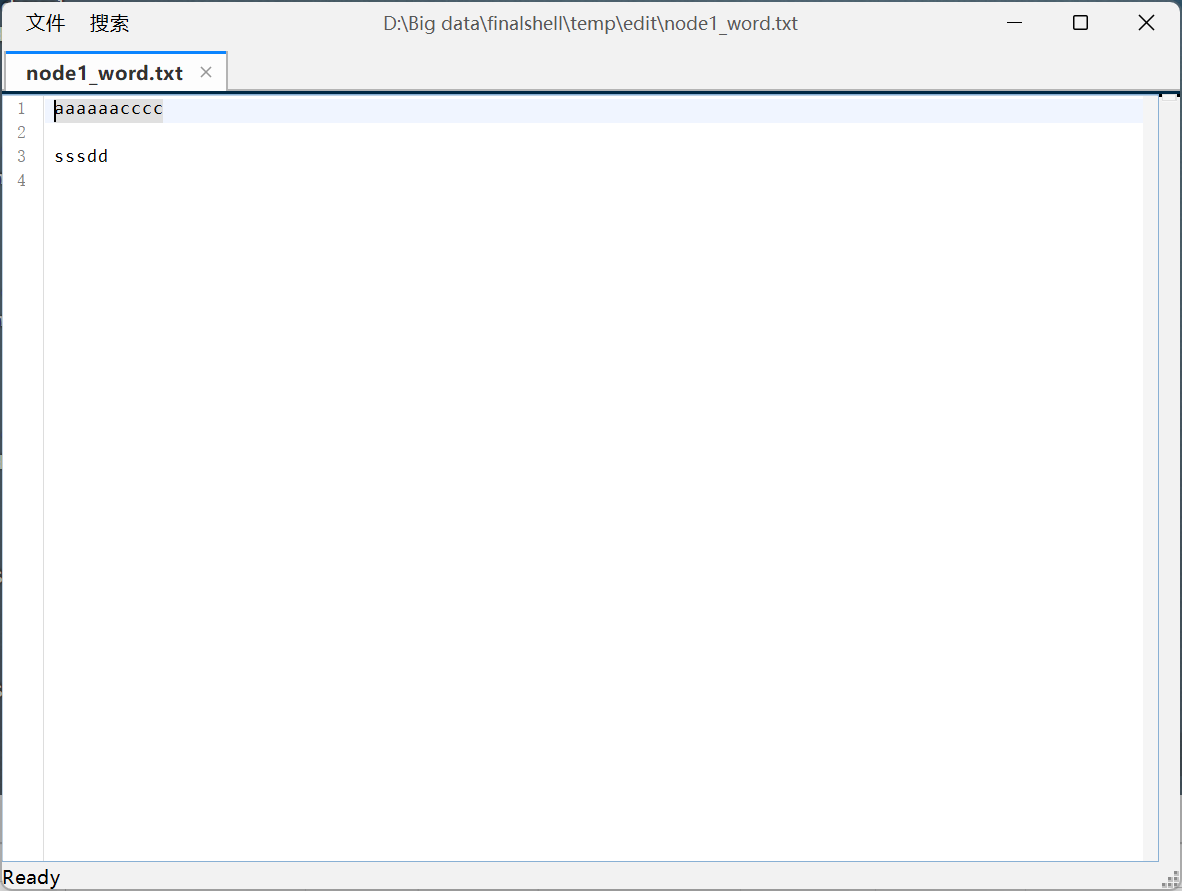
(7)查看 word.txt 文件内容;
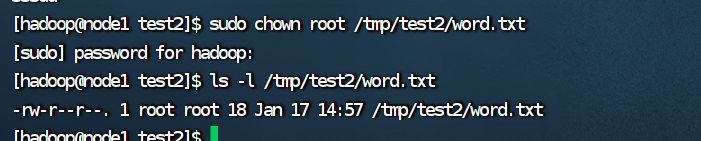
(8)将 word.txt 文件所有者改为 root 帐号,并查看属性;
(9)找出/tmp 目录下文件名为 test2 的文件;

(10)在/目录下新建文件夹 test,然后在/目录下打包成 test.tar.gz;
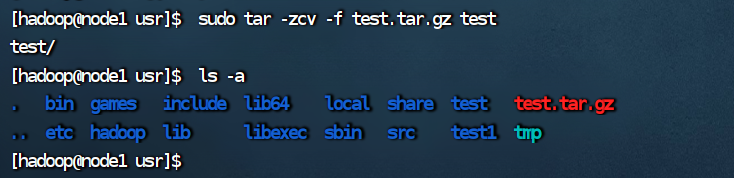
(11)将 test.tar.gz 解压缩到/tmp 目录。

3. 在 Windows 系统和 Linux 系统之间互传文件
完成以下操作:
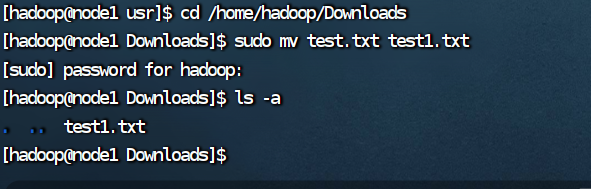
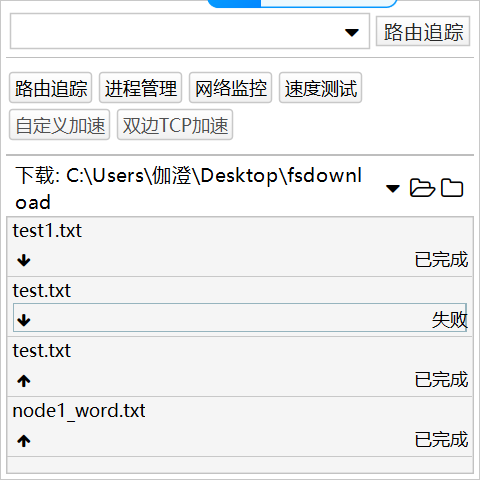
(1)在 Windows 系统中新建一个文本文件 test.txt,并通过 FTP 软件 FileZilla,把 test.txt
上传到 Linux 系统中的“/home/hadoop/下载”目录下,把利用 Linux 命令把该文件名修改为
test1.txt;

(2)通过 FTP 软件 FileZilla,把 Linux 系统中的“/home/hadoop/下载”目录下的 test1.txt厦
文件下载到 Windows 系统的某个目录下
四、实验报告
出现的问题:
本次实验主要是Linux的基本操作,在之前也用过,不过一段时间没用,又有些生疏,在用vim和vi命令的时候出现了些许问题,退出时无法退出:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】