
sqoop同步工具详情
未经允许不得转载
来源
数据同步工具(针对各种数据库):
开源工具:
sqoop:
datax:
kettle:
cannal:
自定义代码:
闭源工具:
1、关系型数据库中数据怎么导入到hdfs、hbase(压缩或者非压缩)?
2、hdfs中的数据(压缩)怎么导入关系型数据库中?
3、增量数据导入?
2、sqoop****定义
sqoop是一个hadoop和关系型数据库之间高效批量数据同步工具。
导入(import): 关系型数据库 -----> hadoop(hdfs\hive\hbase)
导出****(export):hadoop(hdfs) ----> 关系型数据库
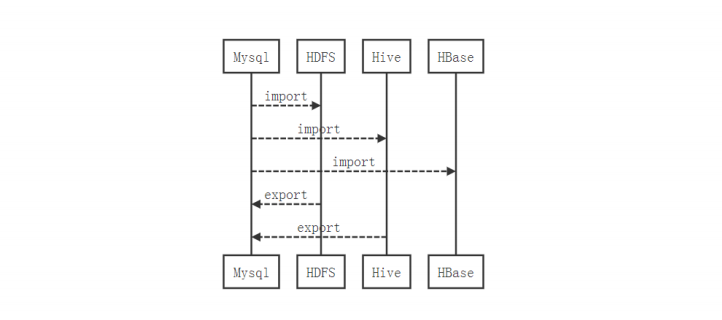
数据同步本质:使用mapreudce来进行数据同步,主要是使用mapper。
优点:跨平台数据同步
缺点:不是很灵活。
3****、sqoop的安装
准备:
需要hadoop的安装
需要jdk
需要准备关系型数据库的依赖jar包
安装
1、解压配置环境变量即可
[root@hadoop01 local]# tar -zxvf /home/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C
/usr/local/
[root@hadoop01 local]# mv ./sqoop-1.4.7.bin__hadoop-2.6.0/ ./sqoop-1.4.7
2、配置环境变量
[root@hadoop01 local]# vi /etc/profile [root@hadoop01 local]# source /etc/profile
验证
[root@hadoop01 local]# which sqoop
常见命令:
3、配置sqoop-env.sh文件
[root@hadoop01 local]# mv ./sqoop-1.4.7/conf/sqoop-env-template.sh ./sqoop- 1.4.7/conf/sqoop-env.sh
[root@hadoop01 local]# vi ./sqoop-1.4.7/conf/sqoop-env.sh
修改如下:
#Set Hadoop-specific environment variables here.
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/usr/local/hadoop-2.7.1/
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/usr/local/hadoop-2.7.1/
#set the path to where bin/hbase is available
export HBASE_HOME=/usr/local/hbase-1.1.2/
#Set the path to where bin/hive is available
export HIVE_HOME=/usr/local/hive-2.3.6/
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/usr/local/zookeeper-3.4.10/
4、测试
[root@hadoop01 local]# sqoop-version
Warning: /usr/local/sqoop-1.4.7//../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/local/sqoop-1.4.7//../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/local/sqoop-1.4.7//../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
19/12/02 10:13:30 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Sqoop 1.4.7
git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8
Compiled by maugli on Thu Dec 21 15:59:58 STD 2017
4、sqoop****的实战
sqoop只允许将语句放到1行,如果想要放到多行,需要\来表示换行。
4.1 sqoop列出mysql****中的所有库
格式:
$ sqoop list-databases (generic-args) (list-databases-args)
$ sqoop-list-databases (generic-args) (list-databases-args)
准备:
引入mysql的驱动包。
[root@hadoop01 sqoop-1.4.7]# cp /home/mysql-connector-java-5.1.6-bin.jar ./lib/
语句:
sqoop list-databases --connect jdbc:mysql://hadoop01:3306 \
--username root \
--password root
结果:
information_schema
azkaban
bap_dm
bap_ods
hive
kettle
mysql
performance_schema
sales_report
sales_source
test
ywp
4.2 sqoop列出mysql****某库的所有表
sqoop list-tables --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root
4.3 sqoop****数据的导入
数据导入import
数据导出export
格式:
$ sqoop import (generic-args) (import-args)
$ sqoop-import (generic-args) (import-args)
导入某个表的所有数据到hdfs中:
sqoop import --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u1 \
--delete-target-dir \
--target-dir '/1906sqoop/u1' \
--split-by id
并行导入:
sqoop import --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u1 \
--delete-target-dir \
--target-dir '/1906sqoop/u2' \
--split-by id \ -m 1
选择列导入:
法一:
sqoop import --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table stu \
--driver com.mysql.jdbc.Driver \
--columns 'id,name,age' \
--where id > 6 \
--delete-target-dir \
--target-dir '/1906sqoop/u3' \
--split-by id \ -m 1
法二: sqoop import
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--query 'select id,name,age from stu where id > 6 and $CONDITIONS' \
--driver com.mysql.jdbc.Driver \
--delete-target-dir \
--target-dir '/1906sqoop/u6' \
--split-by id \ -m 1 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0'
单引号和双引号的区别:
--query 'select id,name,age from stu where id > 6 and $CONDITIONS' \
--query "select id,name,age from stu where id > 6 and \$CONDITIONS" \
参数属性:
--table mysql中的表
--delete-target-dir 如果hdfs中的目标目录存在,则删除
--target-dir 导入到hdfs中的那个目录
--split-by 切分工作单元,后面需要指定column
-m 使用n个map task来并行导入,一般和
--split-by搭配使用
--columns 导入指定列,和table搭配使用
--where 指定条件
--driver 指定驱动参数
--query 指定运行的sql语句,不能和--table搭配使用
-warehouse-dir 仓库目录,项目可以指定一个根目录
--fields-terminated-by 导入的字段分隔符,默认是,分割
--null-string 字符串列空值处理 --null-non-string 非字符串列空值处理
--as-parquetfile 输出的数据文件格式
--fetch-size 10000 一次获取的数据条数
--compress 指定压缩
--compression-codec 指定压缩类型,默认gzip压缩
指指定文件格式导入:
sqoop import
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--query 'select id,name,age from stu where id > 6 and $CONDITIONS' \
--driver com.mysql.jdbc.Driver \
--delete-target-dir \
--target-dir '/1906sqoop/u5' \
--split-by id \ -m 1 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0' \
--as-parquetfile \
--fetch-size 10000
问题:
1、如果mysql的表没有主键,将会报错:19/12/02 10:39:50 ERROR tool.ImportTool: Import failed: No primary key could be found for table u1. Please specify one with -- split-by or perform a sequential import with '-m 1'.
解决方法:
指定--split-by 2、
导入指定列错误 :java.sql.SQLException: Streaming result set com.mysql.jdbc.RowDataDynamic@4c39bec8 is still active. No statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.
解决方法:
加上该属性: --driver com.mysql.jdbc.Driver \
思考:
1、怎么监控数据是否完全导入???
2、某表如果2G数据,设置多少个mapper合适?
4.4 sqoop****数据的导出
1、构建mysql的表:
CREATE TABLE `u2` (
`id` int(11) DEFAULT NULL,
`age` int(11) DEFAULT '0'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `u3` (
`id` int(11) DEFAULT NULL,
`name` varchar(20) default NULL,
`age` int(11) DEFAULT '0'
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2、hdfs导出到mysql语句
sqoop export --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u2 \
--driver com.mysql.jdbc.Driver \
--export-dir '/1906sqoop/u2/*' \
-m 1
法二:
先从新导入数据:
sqoop import --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--query 'select id,name,age from stu where id > 6 and $CONDITIONS' \
--driver com.mysql.jdbc.Driver \
--delete-target-dir \
--target-dir '/1906sqoop/u7' \
--split-by id \ -m 1 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0'
导出语句:
sqoop export --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u3 \
--driver com.mysql.jdbc.Driver \
--export-dir '/1906sqoop/u7/*' \
--input-fields-terminated-by '\t' \
--input-null-string '\\N' \
--input-null-non-string '\\N' \
-m 1
注:
1、导出数据中有些列值有"null",会报没法解析
2、导出数据的类型需要和mysql中的一致(能自动转没有问题)
5、sqoop****高级实例
5.1 sqoop导入到hive****表
方式:
1、直接导入到hdfs中的某个目录,然后再创建表去指向该目录即可。
2、直接导入到hive的表中。
准备:
1、需要hive能正常使用(metastore服务启动起来)
2、将hive的exec.jar包复制到sqoop的lib目录下
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u2 \
--hive-import \ --hive-overwrite \
--hive-table u2 \
-m 1
分解步骤:
1、导入hdfs中的目录下
2、将该目录下的数据装载到hive表中
问题:
1、hive-1.2.1 和 sqoop-1.4.7 ,从mysql导入数据到hive表中,hive中查询不出来表,元数据也没有。
解决办法:
将hive-site.xml放到sqoop的conf目录中即可。
5.2 sqoop****导入到hive的分区表
方式:
1、sqoop导入数据到hdfs目录(分区的形式),然后再hive中创建分区表,最后使用alter table add
partition...
2、直接使用sqoop导入都分区表中ss
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \ --password root \
--hive-import \
--hive-overwrite \
--hive-partition-key 'bdp_day' \
--hive-partition-value '20191202' \
--target-dir /root/u22 \
--hive-table u22 \
--num-mappers 1 \
--query 'SELECT * FROM u2 where $CONDITIONS;'
5.3 hive的job
sqoop提供一系列的job语句来操作sqoop。
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
使用方法:
usage: sqoop job [GENERIC-ARGS] [JOB-ARGS] [-- [<tool-name>] [TOOL-ARGS]]
Job management arguments:
--create <job-id> Create a new saved job
--delete <job-id> Delete a saved job
--exec <job-id> Run a saved job
--help Print usage instructions
--list List saved jobs
--meta-connect <jdbc-uri> Specify JDBC connect string for the
metastore
--show <job-id> Show the parameters for a saved job
--verbose Print more information while working
列出sqoop的job:
sqoop job --list
创建一个sqoop的job:
sqoop job --create sq2
-- import --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u2 \
--driver com.mysql.jdbc.Driver \
--delete-target-dir \
--target-dir '/1906sqoop/u9' \
--split-by id \
-m 1
执行sqoop的job:
sqoop job --exec sq1
执行的时候回让输入密码:
输入该节点用户的对应的密码即可
1、配置客户端记住密码(sqoop-site.xml)追加
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
</property>
2、将密码配置到hdfs的某个文件,我们指向该密码文件
说明:在创建Job时,使用--password-file参数,而且非--passoword。主要原因是在执行Job时使用--password参数将有警告,并且需要输入密码才能执行Job。当我们采用--password-file参数时,执行
Job无需输入数据库密码。
echo -n "root" > sqoop.pwd
hdfs dfs -rm sqoop.pwd /input/sqoop.pwd
hdfs dfs -put sqoop.pwd /input
hdfs dfs -chmod 400 /input/sqoop.pwd
hdfs dfs -ls /input
-r-------- 1 hadoop supergroup 6 2018-01-15 18:38 /input/sqoop.pwd
查看sqoop的job:
sqoop job --show sq1
删除sqoop的job:
sqoop job --delete sq1
问题:
1、创建job报错:19/12/02 23:29:17 ERROR sqoop.Sqoop: Got exception running Sqoop:
java.lang.NullPointerException
java.lang.NullPointerException
at org.json.JSONObject.<init>(JSONObject.java:144)
解决办法:
添加java-json.jar包到sqoop的lib目录中。
如果上述办法没有办法解决,请注意hcatlog的版本是否过高,过高将其hcatlog包剔除sqoop的lib目录即可。
2、报错:Caused by: java.lang.ClassNotFoundException: org.json.JSONObject
解决办法:
添加java-json.jar包到sqoop的lib目录中。
job的好处:
1、一次创建,后面不需要创建,可重复执行job即可
2、它可以帮我们记录增量导入数据的最后记录值
3、job的元数据存储目录:$HOME/.sqoop/
5.4 更新并插入导出
场景:
多维结果数据导出;异常重跑数据
--update-mode : updateonly,是默认,仅更新;allowinsert:更新并允许插入
--update-key :
CREATE TABLE `upv` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`visits` int(11) DEFAULT NULL,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
导出语句:
sqoop export --connect jdbc:mysql://hadoop01:3306/test \
--username root --password root --table upv \
--export-dir /1906sqoop/upv/* \
--input-fields-terminated-by "," \
--update-mode allowinsert \
--update-key country_id
5.5 sqoop导出parquet****格式的数据
导入数据到HDFS中为parqut格式:
sqoop import --connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--query 'select id,age from stu where id > 6 and $CONDITIONS' \
--driver com.mysql.jdbc.Driver \
--delete-target-dir \
--target-dir '/1906sqoop/u9' \
--split-by id \
-m 1 \
--fields-terminated-by '\t' \
--null-string '\\N' \
--null-non-string '0' \
--as-parquetfile
导出语句:
创建表:
CREATE TABLE `par` (
`id` int(11) NOT NULL DEFAULT '0',
`age` int(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
hive创建表:
create table if not exists par(
`id` int,
`age` int
)
row format delimited fields terminated by '\t'
stored as parquet
location '/1906sqoop/u9/'
;
将hive包中的lib目录下的hcatlog相关包拷贝到sqoop的lib目录中去:
[root@hadoop01 sqoop-1.4.7]# cp /usr/local/hive-2.3.6/lib/hive-hcatalog-core-2.3.6.jar /usr/local/hive-2.3.6/lib/hive-hcatalog-server-extensions-2.3.6.jar ./lib/
导出parquet格式语句:
sqoop export \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table par \
--hcatalog-database default \
--hcatalog-table par \
-m 1
参数说明:
--table:MySQL库中的表名
--hcatalog-database:Hive中的库名
--hcatalog-table:Hive库中的表名,需要抽数的表
5.6 定期执行
方法:
1、直接调度框架调度sqoop语句
2、将sqoop语句封装到shell脚本中,调度框架调度脚本或者直接在服务器中使用crontab来定时
vi /home/add_u2.sh
#!/bin/bash
/usr/local/sqoop-1.4.7/bin/sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password root \
--table u2 \
--hive-import \
--hive-overwrite \
--hive-table u2 \
-m 1
授予可执行权限:
[root@hadoop01 sqoop-1.4.7]# chmod a+x /home/add_u2.sh
定时:
[root@hadoop01 sqoop-1.4.7]# crontab -e
\* 2 * * * /home/add_u2.sh >> /home/u2.log
自己捣鼓
1、将资料中 sales_source.sql加载到自己mysql中,并且使用sqoop将里面的三章表的数据导入到hive
表中,hive的表名和sales_source.sql中的表名一样,hive的库名统一叫sales_ods.
需求:
a、sales_order表需要增量导入,必须是分区表
b、其它两张表全量导入,不用分区表
c、将其sqoop语句放到shell脚本中,执行脚本即可执行把3张表的数据导入即可。
提示
------------
customer : 全量
product : 全量
orders : 增量
vi /home/hw01.sh
#!/bin/bash
create database if not exists sales_ods;
sqoop import \
--connect jdbc:mysql://hadoop01:3306/sales_source \
--username root \
--password root \
--table customer \
--hive-import \
--hive-overwrite \
--hive-table sales_ods.customer \
-m 1
sqoop import \
--connect jdbc:mysql://hadoop01:3306/sales_source \
--username root \
--password root \
--table product \
--hive-import \
--hive-overwrite \
--hive-table sales_ods.product \
-m 1
思考:
1、怎么监控数据是否完全导入???
使用shell脚本去查询mysql中某表的数据,然后和hive中表的行数对比。
#!/bin/bash
u2_cnt=`mysql -uroot -proot -e "select count(*) from test.u2"`
echo "u2 table of test total rows:${u2_cnt}"
2、某表如果2G数据,设置多少个mapper合适?
建议128M(和块大小一致)一个mapper即可。

